Running the dbt cloud collector on-premise
Note
The latest version of the Collector is 2.330. To view the release notes for this version and all previous versions, please go here.
Generating the command or YAML file
This section walks you through the process of generating the command or YAML file for running the collector from Windows or Linux or MAC OS.
To generate the command or YAML file:
In the Catalog experience, go to the Admin page > Metadata collectors section.
Click the Add a collector button.
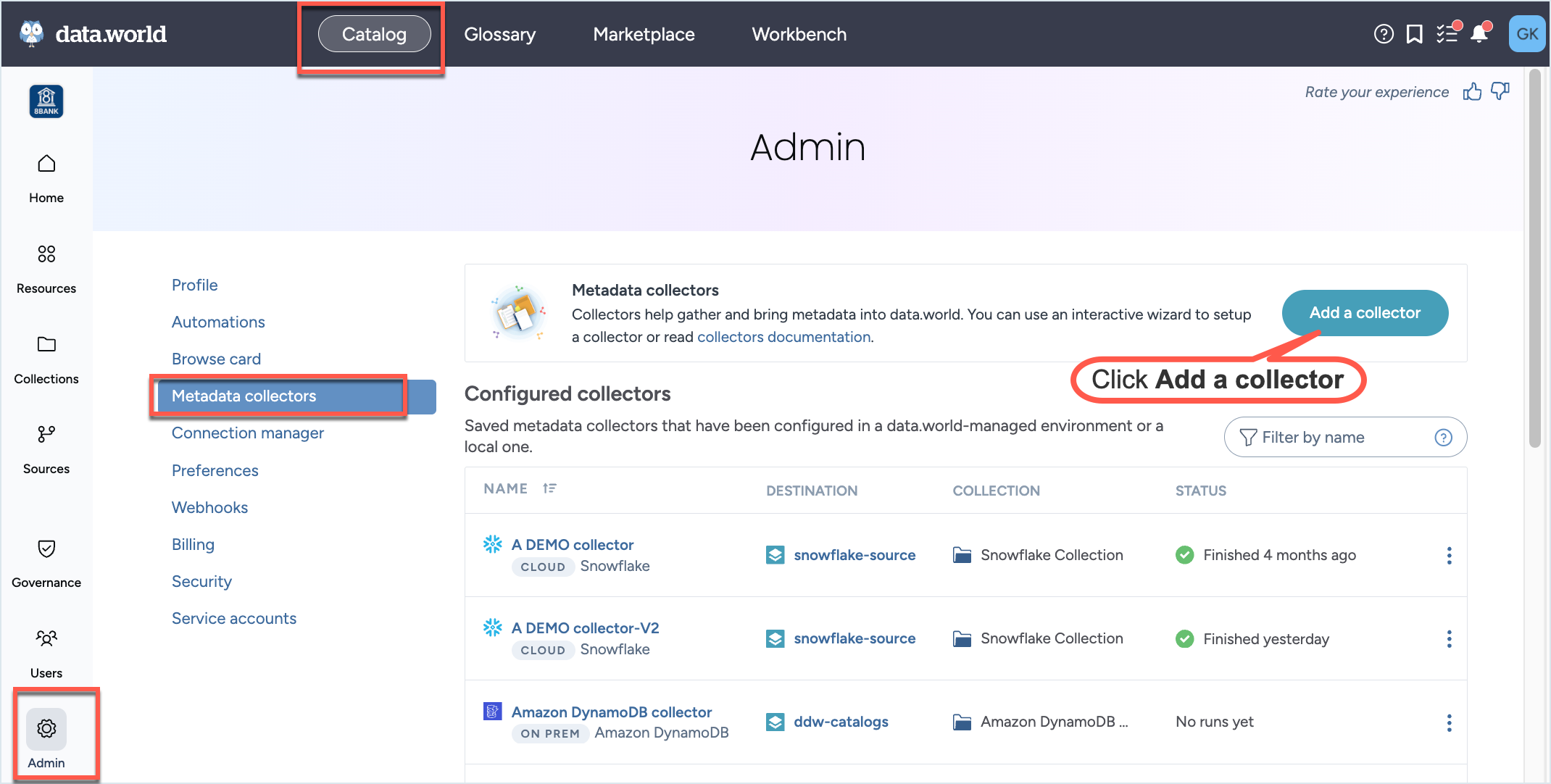
On the Choose metadata collector screen, select the correct metadata source. Click Next.
On the Choose where the collector will run screen, in the On-premise section, select if you will be running the collector on Windows or Mac OS or Linux. This will determine the format of the YAML and CLI that is generated in the end. Click Next.
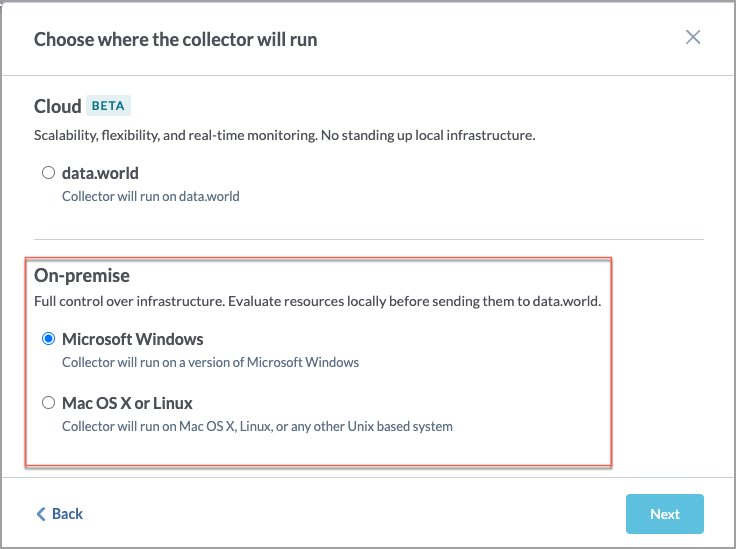
On the On-prem collector setup prerequisites screen, read the pre-requisites and click Next.
On the Configure an on-premises DBT Cloud Collector screen, set the following properties and click Next.
On the next screen, set the following properties and click Next.
Table 2.Field name
Corresponding parameter name
Description
Required?
dbt Cloud host
--dbt-cloud-host=<dbtCloudHost>
Specify the host for your organization's account on dbt cloud. If left unspecified, the default host will be assumed as cloud.getdbt.com.
No
dbt cloud account ID
--dbt-cloud-account= <account>
The dbt cloud account that owns the project from which to harvest dbt metadata artifacts.
Yes
dbt cloud API key
--dbt-cloud-api-key= <dbtCloudApiKey>
A dbt cloud-issued api key with permissions to access the specified account
Yes
dbt cloud project
--dbt-cloud-project= <project>
The name or numeric identifier of the project from which to harvest dbt metadata artifacts.
Yes
dbt cloud run
--dbt-cloud-run= <runIdentifier>
The numeric identifier of the run that produced the artifacts to be harvested; if not specified, the most recent successful run that produced artifacts within the project will be harvested.
No
dbt Cloud environment
--dbt-cloud-environment=<environmentIDOrName>
Specify the dbt Cloud environment (ID or name) used to filter the job runs from which to harvest dbt metadata artifacts.
No
dbt Cloud job
--dbt-cloud-job= <jobIDOrName>
Specify the dbt Cloud job (ID or name) used to filter the job runs from which to harvest dbt metadata artifacts.
No
On the next screen, set the following advanced options and click Next.
Important: You must set the Target database to Snowflake overrides if you want to harvest Snowflake lineage relationships between columns specified through views.
You can authenticate to Snowflake either using the username and password or private key file and password.
By default, the collector obtains the connection information to Snowflake from the identified dbt Cloud run. This connection information includes the Snowflake account, role, and warehouse used to authenticate to Snowflake. You have the option to override the connection information for a given run using the Snowflake account, Snowflake role, and Snowflake warehouse override fields.
Table 3.Field name
Corresponding parameter name
Description
Required?
Target database
-
The dbt cloud collector will obtain database connection information from the connection configured on the Project in dbt cloud. Only use these options to override the values if necessary.
Yes
No Target database overrides
-
Allows the collector to skip connecting to a data warehouse and only harvest dbt assets. This means no lineage will be available for any views.
Snowflake overrides
-
Select this option if you want to harvest Snowflake lineage relationships between columns specified through views.
Authentication: Select from one of the following authentication options.
Yes
(if Snowflake overrides is selected)
Option 1: Snowflake username and password overrides
Username
--database-user= <databaseUser>
The user credential to use in connecting to the target database.
Password
--database-password= <databasePassword>
The password credential to use in connecting to the target database.
Option 2: Snowflake private key file overrides
Database username
--database-user= <databaseUser>
Specify the username to use in connecting to the target database.
Snowflake key file path
--snowflake-private-key-file= <snowflakePrivateKey>
The private key file to use for authentication with Snowflake (for example rsa_key.p8). Use this option to override the dbt profile. Ignored for non-Snowflake target dbs.
Snowflake key file password
--snowflake-private-key-file-password= <snowflakePrivateKeyFilePassword>
The password for the private key file to use for authentication with Snowflake, if the key is encrypted and a password was set Use this option to override the dbt profile or cloud configuration. It is ignored for non-Snowflake target dbs.
Other optional resources
Snowflake application
--snowflake-application= <snowflakeApplication>
The application connection parameter to use in connecting to the target Snowflake database. Use this option to override the dbt profile or cloud configuration. It is ignored for non-Snowflake target dbs.
Use datadotworld unless otherwise directed.
No
Snowflake account
<snowflakeAccount> --snowflake-account=
The Snowflake account/tenant.
No
Snowflake role
--snowflake-role= <snowflakeDatbaseRole>
The role to use in connecting to the target Snowflake database. Use this option to override the dbt profile or cloud configuration. It is ignored for non-Snowflake target dbs. This is case-insensitive.
No
Snowflake warehouse
--snowflake-warehouse= <snowflakeDatbaseWarehouse>
The warehouse to use in connecting to the target Snowflake database. Use this option to override the dbt profile or cloud configuration. It is ignored for non-Snowflake target dbs. This is case-insensitive.
No
On the next screen, set the following advanced options and click Next.
Table 4.Field name
Corresponding parameter name
Description
Required?
Max retries
--api-max-retries=<maxRetries>
Specify the number of times to retry an API call which has failed. The default value is 5.
No
Retry delay
--api-retry-delay=<retryDelay>
Specify the amount of time in seconds to wait between retries of an API call which has failed. The default is to try with a delay of 2 seconds between each call.
No
API HTTP header
--api-http-header
Specify name-value pairs that the collector will include as HTTP headers in any calls to the HTTP API used by the collector to harvest metadata. Use the option multiple times for multiple headers.
Note: Use this option only after consulting the data.world Support team.
No
JDBC driver property
--jdbc-property=<driverProperties>
JDBC driver properties to pass through to driver connection, as name=value pair. Use the parameter multiple times for multiple properties. For example, --jdbc-property property1=value1 --jdbc-property property2=value2
No
--jdbc-property="integratedSecurity=true"
-jdbc-property="authenticationScheme=NTLM"
If you are using the NTLM authentication, make sure to set these two JDBC properties.
Yes
(if using NTLM authentication)
On the next screen, provide the Collector configuration name and an optional Configuration description. This is the name used to save the configuration details. The configuration is saved and made available on the Metadata collectors summary page from where you can edit or delete the configuration at a later point. Click Save and Continue.
On the Finalize your collector configuration screen, you are notified about the environment variables and directories you need to setup for running the collector. Select if you want to generate Configuration file ( YAML) or Command line arguments (CLI). Click Next.
Important
You must ensure that you have set up these environment variables and directories before you run the collector.
The next screens gives you an option to download the YAML configuration file or copy the CLI command.
If you selected Command line arguments (CLI), from the Choose how to run the collector dropdown, select Java command or Docker command and note down the generated command. Click Done.
If you selected Configuration file ( YAML), download the generated a YAML file. Click Next.
The final screen displays the command to use for running the collector with the YAML file. From the Choose how to run the collector dropdown, select Java command or Docker command, and note down the generated command.
You will notice that the YAML/CLI has following additional parameters that are automatically set for you.
Warning
Except for the collector version, you should not change the values of any of the parameter listed here.
Table 5.Parameter name
Details
Required?
-a= <agent>
--agent= <agent>
--account= <agent>
The ID for the data.world account into which you will load this catalog - this is used to generate the namespace for any URIs generated.
Yes
--site= <site>
This parameter should be set only for Private instances. Do not set it for public instances and single-tenant installations. Required for private instance installations.
Yes (required for private instance installations)
-U
--upload
Whether to upload the generated catalog to the organization account's catalogs dataset.
Yes
--no-log-upload
Do not upload the log of the collector run to a dataset in data.world. This is the same dataset where the collector output is uploaded. By default, log files are uploaded to this dataset.
Yes
dwcc: <CollectorVersion>
The version of the collector you want to use (For example,
datadotworld/dwcc:2.248)Yes
Add the following additional parameter to test run the collector.
--dry-run: If specified, the collector does not actually harvest any metadata, but just checks the connection parameters provided by the user and reports success or failure at connecting.
We recommend enabling debug level logs when running the collector for the first time. This approach aids in swiftly troubleshooting any configuration and connection issues that might arise during collector runs. Add the following parameter to your collector command:
-e log_level=DEBUG: Enables debug level logging for collectors.
Verifying environment variables and directories
Verify that you have set up all the required environment variables that were identified by the Collector Wizardbefore running the collector. Alternatively, you can set these credentials in a credential vault and use a script to retrieve those credentials.
Verify that you have set up all the required directories that were identified by the Collector Wizard.
Running the collector
Important
Before you begin running the collector make sure you completed all the pre-requisite tasks.
Running collector using YAML file
Go to the machine where you have setup docker to run the collector.
Place the YAML file generated from the Collector wizard to the correct directory.
From the command line, run the command generated from the application for executing the YAML file. Here is a sample Docker command. Similarly, you can get the Java command from the UI.
Caution
Note that is just a sample command for showing the syntax. You must generate the command specific to your setup from the application UI.
docker run -it --rm --mount type=bind,source=${HOME}/dwcc,target=/dwcc-output \ --mount type=bind,source=${HOME}/dwcc,target=/app/log -e DW_AUTH_TOKEN=${DW_AUTH_TOKEN} \ -e DW_DBT_CLOUD_KEY=${DW_DBT_CLOUD_KEY} datadotworld/dwcc:2.142 \ --config-file=/dwcc-output/config-dbt_cloud.ymlThe collector automatically uploads the file to the specified dataset and you can also find the output at the location you specified while running the collector. Similarly, the log files are uploaded to the specified dataset and can be found in the directory mounted to target=/app/log specified in the command.
If you decide in the future that you want to run the collector using an updated version, simply modify the collector version in the provided command. This will allow you to run the collector with the latest version.
Running collector without the YAML file
Go to the machine where you have setup docker to run the collector.
From the command line, run the command generated from the application. Here is a sample Docker command. Similarly, you can get the Java command from the UI.
Caution
Note that is just a sample command for showing the syntax. You must generate the command specific to your setup from the application UI.
docker run -it --rm --mount type=bind,source=${HOME}/dwcc,target=/dwcc-output \ --mount type=bind,source=${HOME}/dwcc,target=/app/log datadotworld/dwcc:2.142 \ catalog-dbt-cloud --agent=initech --output=/dwcc-output --api-token=${DW_AUTH_TOKEN} \ --no-log-upload=false --upload=true --name=initech-collection --upload-location=ddw-catalogs \ --dbt-cloud-account=49586 --dbt-cloud-api-key=${DW_DBT_CLOUD_KEY} \ --dbt-cloud-project=8bank-projectThe collector automatically uploads the file to the specified dataset and you can also find the output at the location you specified while running the collector. Similarly, the log files are uploaded to the specified dataset and can be found in the directory mounted to target=/app/log specified in the command.
If you decide in the future that you want to run the collector using an updated version, simply modify the collector version in the provided command. This will allow you to run the collector with the latest version.
Automating updates to your metadata catalog
Maintaining an up-to-date metadata catalog is crucial and can be achieved by employing Azure Pipelines, CircleCI, or any automation tool of your preference to execute the catalog collector regularly.
There are two primary strategies for setting up the collector run times:
Scheduled: You can configure the collector according to the anticipated frequency of metadata changes in your data source and the business need to access updated metadata. It's necessary to account for the completion time of the collector run (which depends on the size of the source) and the time required to load the collector's output into your catalog. This could be for instance daily or weekly. We recommend scheduling the collector run during off-peak times for optimal performance.
Event-triggered: If you have set up automations that refresh the data in a source technology, you can set up the collector to execute whenever the upstream jobs are completed successfully. For example, if you're using Airflow, Github actions, dbt, etc., you can configure the collector to automatically run and keep your catalog updated following modifications to your data sources.
Managing collector runs and configuration details
From the Metadata collectors summary page, view the collectors runs to ensure they are running successfully,
From the same Metadata collectors summary page you can view, edit, or delete the configuration details for the collectors.