Configuring data profiling while running collectors
Which Collectors support profiling for metadata?
The Data profiling feature is available for the following collectors:
Important
Activating the data profiling feature may extend the running time of the collector. This is because the collector needs to read the table data to be able to gather metadata for profiling.
How are column statistics collected?
To compute the column statistics, the collectors retrieves a sample amount of data from the source database and produces:
Statistics for the sample based on the number of rows that the user can supply to the collector.
Calculate distinct and non-null estimates for the entire data in a given column. Estimates are calculated based on the sample size and the number of rows in a given table. For column statistics, only the statistics metadata and bucket counts for the data distribution (histogram) are stored in data.world.
What profiling statistics are collected for metadata?
Object | Information cataloged |
|---|---|
Column |
|
Table |
|
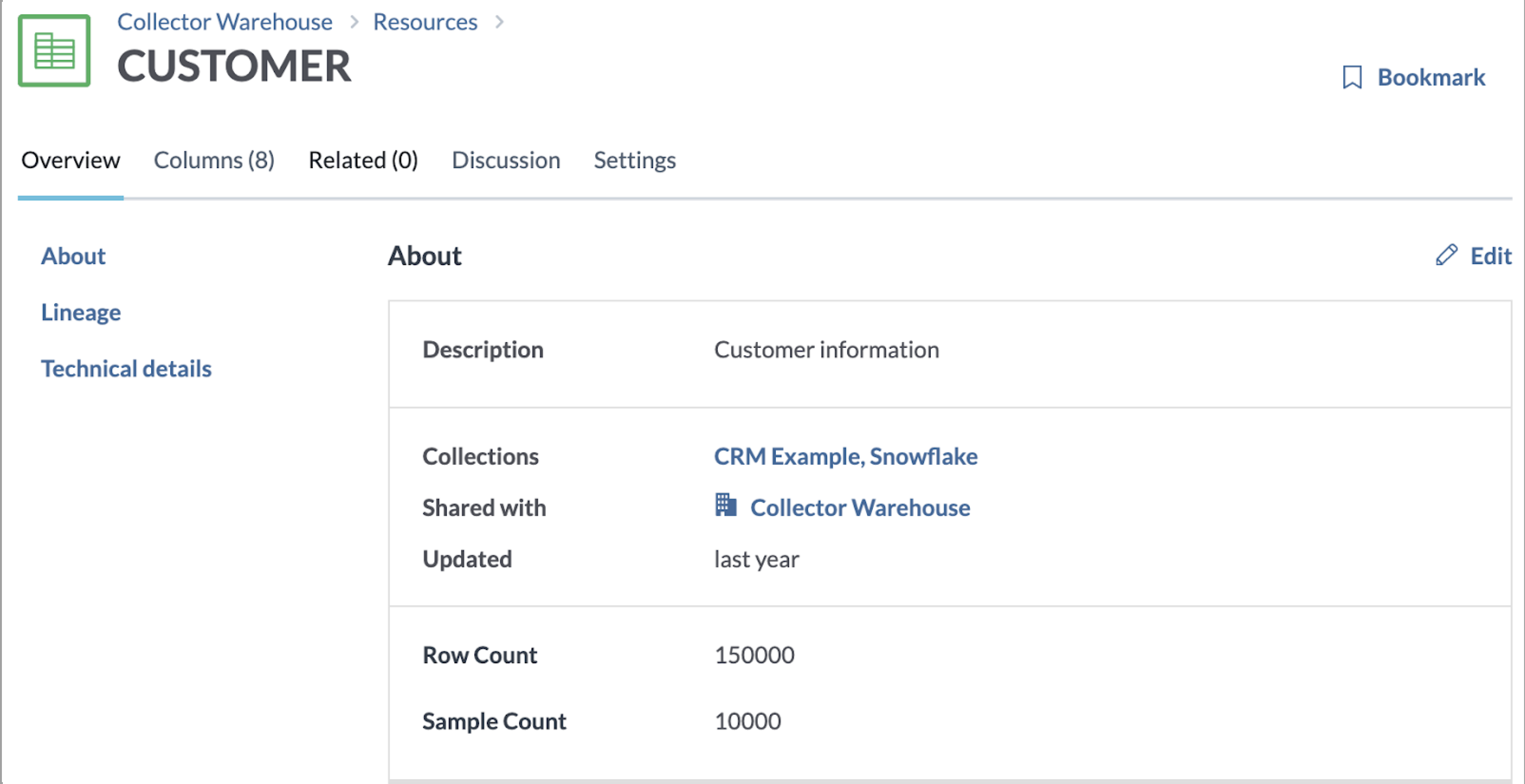
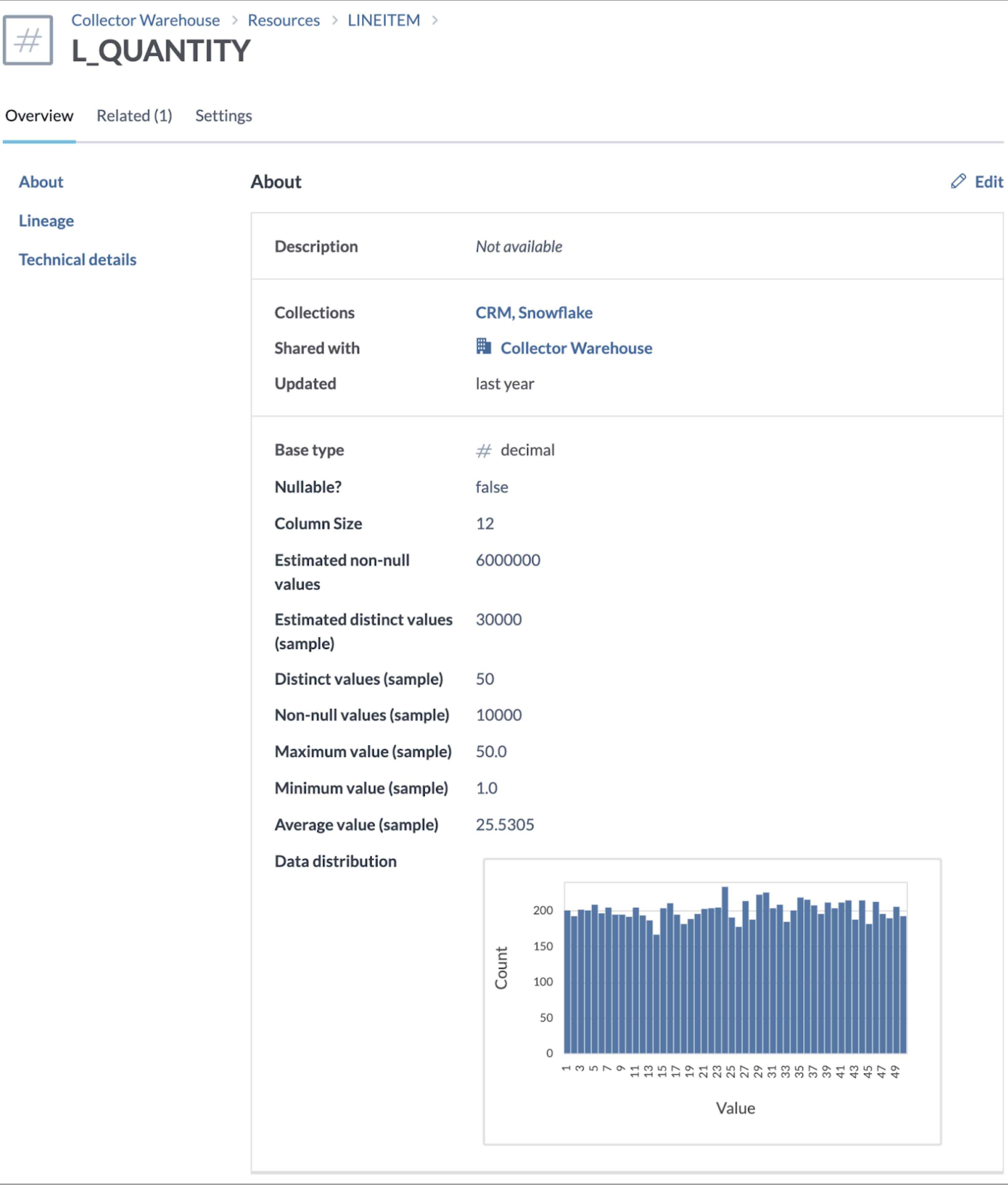
A sample view of data profiling information for metadata:
Sample 1: Statistics on table resource page showing the row count and sample count.
Sample 2: Statistics on a column-resource page showing statistics for the sample, estimates across the entire column data, and data distribution.
Note
Note that Data distribution will show a maximum of 50 buckets.
Does the system sample data to create profiling statistics?
The collector samples a small amount of data only to generate statistics and histogram. The underlying data is not ingested into data.world.
Enabling profiling for metadata
You can enable profiling for metadata by using the following optional parameters for the collectors that support data profiling:
Important
If you are using Catalog Toolkit, make sure you select the relevant module for data profiling to use this feature.
Enable column statistics collection (--enable-column-statistics): To enable harvesting of column statistics.
Enable sample string values collection (--sample-string-values): To enable harvesting of sample values and histograms for columns containing string data. Note: Only applies if Enable column statistics collection is turned on.
Target sample size for column statistics (--target-sample-size): To control the number of rows sampled for computation of column statistics and string-value histograms. For example, to sample 1000 rows, set the parameter as: --target-sample-size=1000. Default is 100000. Note: Only applies if Enable column statistics collection is turned on.
A commonly asked question is - how does the --target-sample-size=1000 sample the 1000 results? It uses the target databases native TABLESAMPLE functionality to efficiently sample approximately 1000 rows from the database table. Usually this is done by sampling a calculated percentage of the rows in the table (determined using SELECT COUNT(*)) but some databases (Snowflake in particular) allow sampling counts of rows directly. Importantly, this is all approximate, and we don't guarantee that an exact number of rows is sampled.