RDF ontologies supported by data.world
As described in the Default graph section, data.world adds a variety of additional RDF triples to each dataset’s default graph. These triples represent metadata information about the contents of the dataset. They use concepts from a variety of standard data description ontologies to expose the structure of the dataset for querying. These ontologies are:
RDF/RDFS
OWL
CSVW
SSD
VoID
DW
RDF/RDFS ontologies
data.world creates triples using the RDF and RDFS ontologies to describe the classes and properties that have been defined for your data during the data.world data ingest process. For instance, each table in a dataset is represented as an RDF class, and a triple specifying that fact is added to the graph as <tableiri> rdf:type rdf:Class. Similarly, each column in the table is represented as an RDF property, and a triple of the form <columniri> rdf:type rdf:Property is generated. Additionally, triples describing the domain and range of those properties are generated. Full descriptions of the RDFS ontology can be found here.
Example - RDF ontology
Here is a query used to access RDF metadata for a data.world dataset, showing RDF properties available.:
PREFIX : <https://ddw-doccorp.linked.data.world/d/ontology-sample-queries/>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
SELECT ?predicate
{
?predicate a rdf:Property
}Here is what it looks like run on data.world:
OWL ontology
data.world creates a few triples in the OWL ontology to help describe the classes and properties that have been defined for your data. For each column defined in a tabular data file, the corresponding RDF property is declared to be an OWL FunctionalProperty (meaning that it is single-valued) and either an OWL DatasetProperty (for properties that refer to simple data types) or an OWL ObjectProperty (for properties that refer to other resources). A full description of the OWL ontology can be found here.
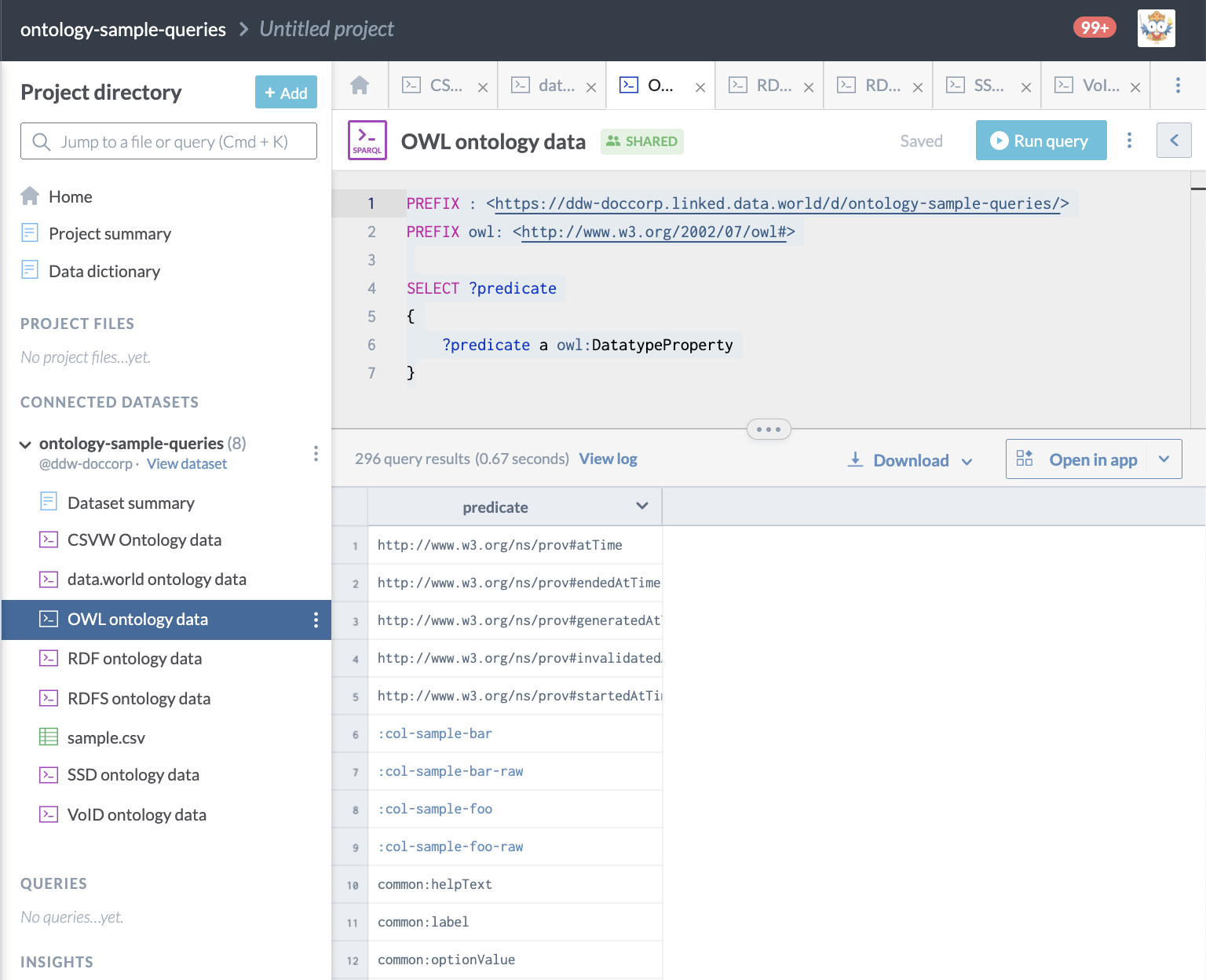
Example - OWL ontology
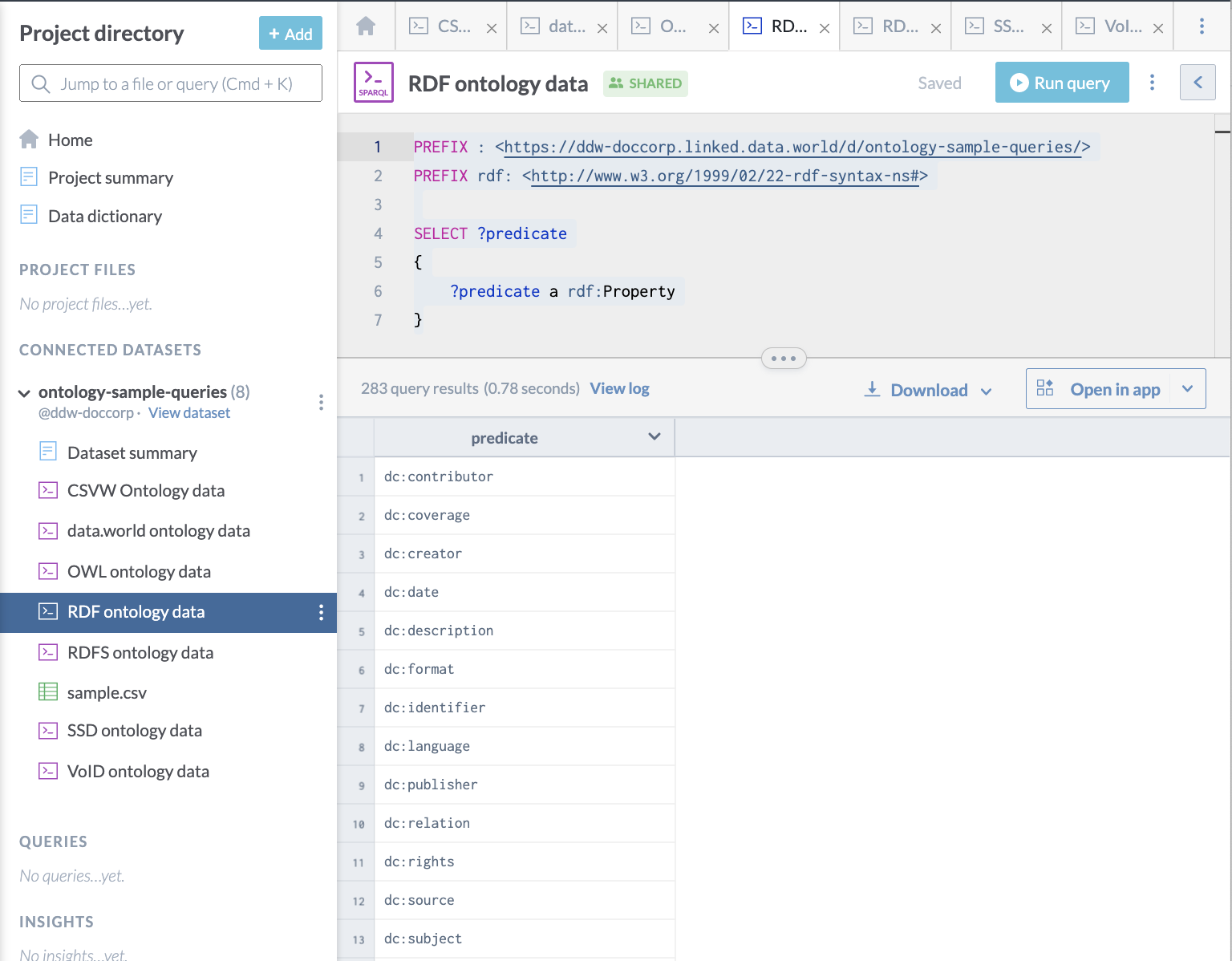
Here is a query used to access OWL metadata for a data.world dataset, showing OWL properties available:
PREFIX : <https://ddw-doccorp.linked.data.world/d/ontology-sample-queries/>
PREFIX owl: <http://www.w3.org/2002/07/owl#>
SELECT ?predicate
{
?predicate a owl:DatatypeProperty
}This is what it looks like on data.world:
CSVW ontology
For datasets containing tabular or virtualized data, data.world generates a large number of triples in the CSVW ontology to describe the tabular structure of your data. CSVW triples are generated describing the structure of each table and column in the dataset, including their names, descriptions, and datatypes. We use CSVW both for data ingest from CSV files (its original intention) and in simplified form data from any tabular or virtualized data source. A full description of the CSVW ontology can be found here.
Example -CSVW ontology
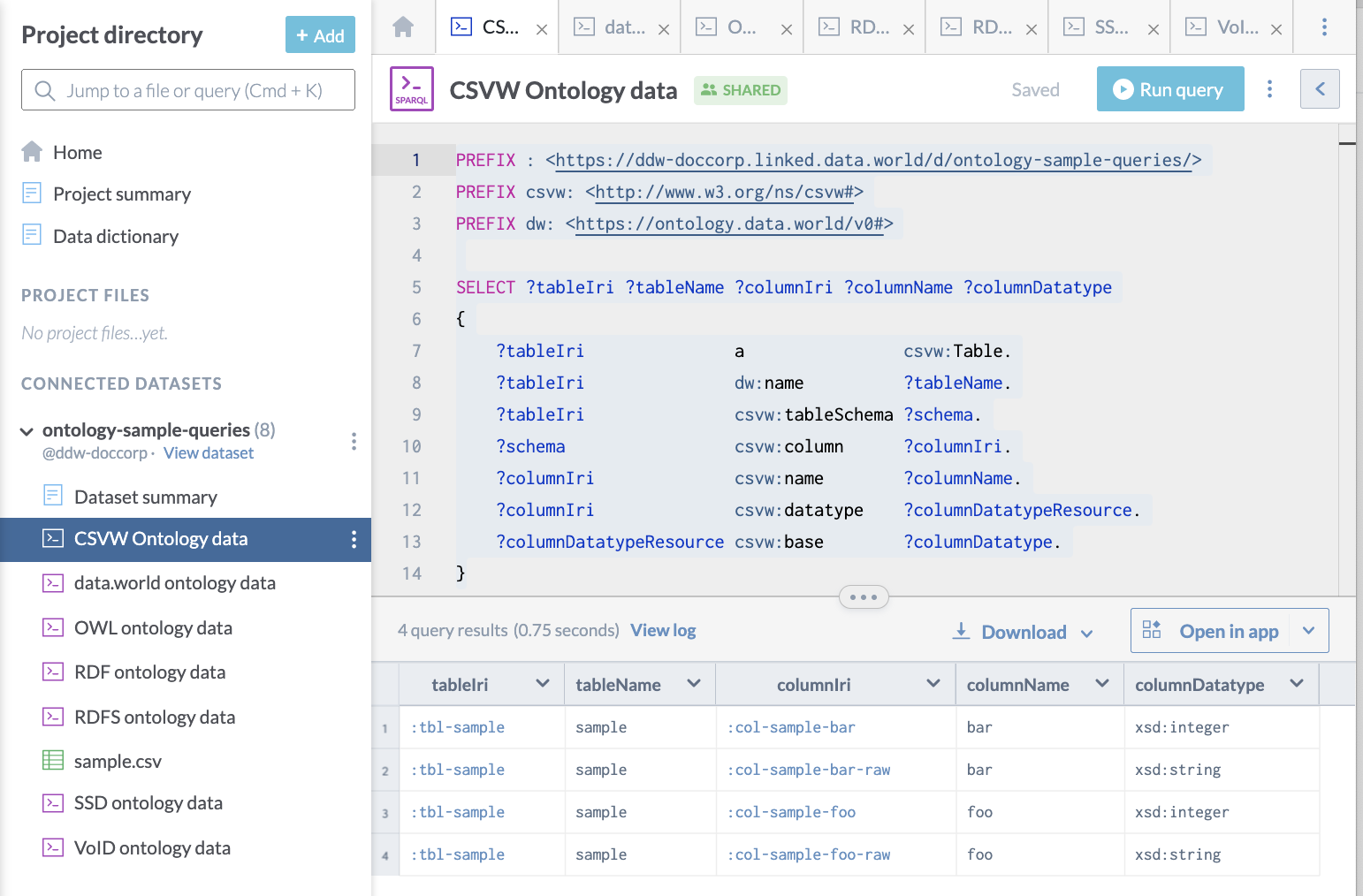
Here is a query used to access CSVW metadata for a data.world dataset, showing details of tabular structure:
PREFIX : <https://ddw-doccorp.linked.data.world/d/ontology-sample-queries/>
PREFIX csvw: <http://www.w3.org/ns/csvw#>
PREFIX dw: <https://ontology.data.world/v0#>
SELECT ?tableIri ?tableName ?columnIri ?columnName ?columnDatatype
{
?tableIri a csvw:Table.
?tableIri dw:name ?tableName.
?tableIri csvw:tableSchema ?schema.
?schema csvw:column ?columnIri.
?columnIri csvw:name ?columnName.
?columnIri csvw:datatype ?columnDatatypeResource.
?columnDatatypeResource csvw:base ?columnDatatype.
}And here is what it looks like on data.world:
SSD ontology
For each dataset, data.world generates triples in the Sparql 1.1 Service Description ontology. These triples describe the dataset in its presentation as a queryable SPARQL endpoint. This includes information about the named graphs which are available for restricted subsets of the dataset, including per-file graphs and metadata graphs. A full description of the SSD ontology can be found here.
Example - SSD ontology
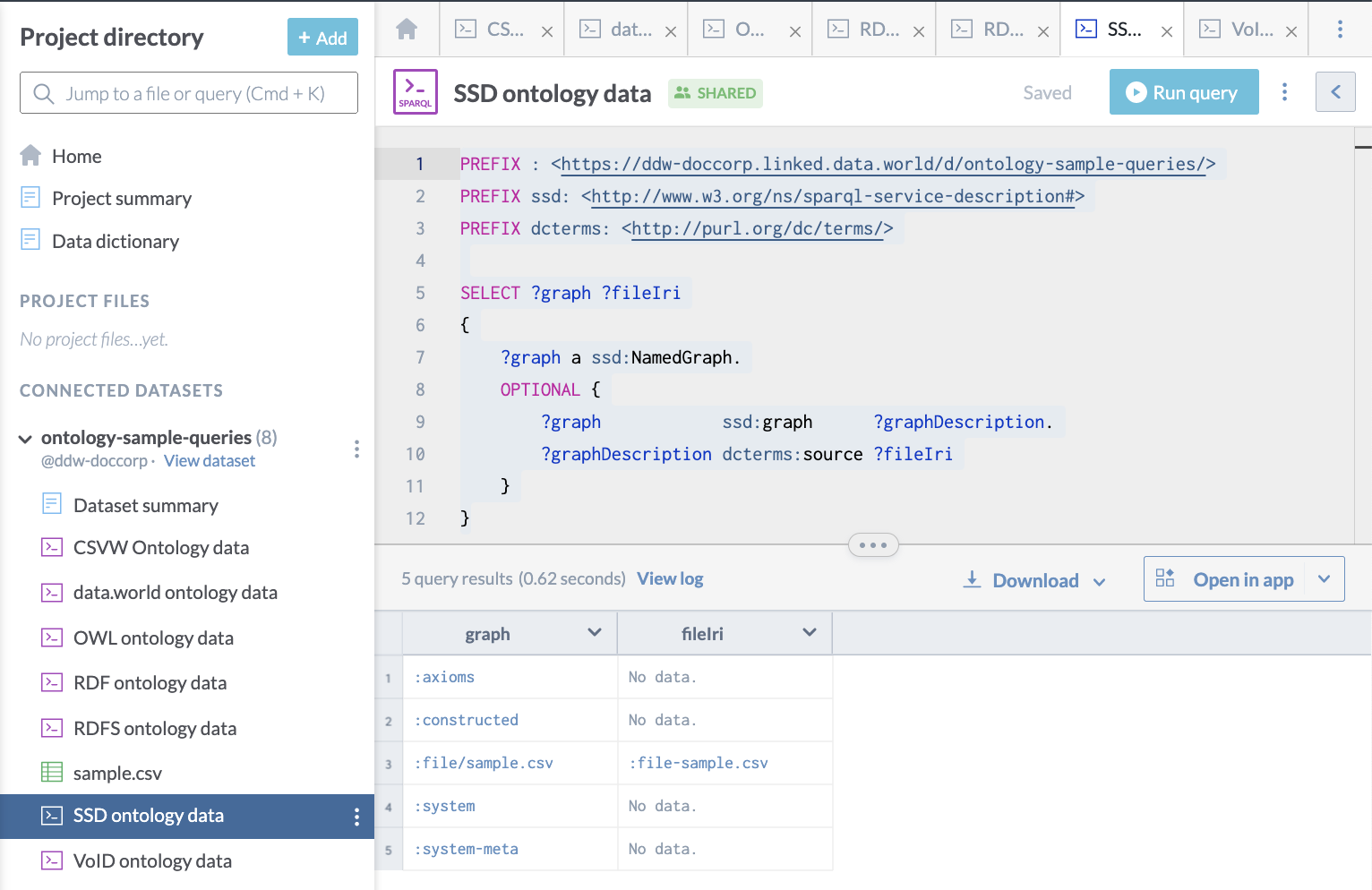
Here is a query used to access SSD metadata for a data.world dataset, showing named graphs available:
PREFIX : <https://ddw-doccorp.linked.data.world/d/ontology-sample-queries/>
PREFIX ssd: <http://www.w3.org/ns/sparql-service-description#>
PREFIX dcterms: <http://purl.org/dc/terms/>
SELECT ?graph ?fileIri
{
?graph a ssd:NamedGraph.
OPTIONAL {
?graph ssd:graph ?graphDescription.
?graphDescription dcterms:source ?fileIri
}
}Here is what it looks like on data.world:
VoID ontology
For every dataset, data.world generates some triples in the VoID ontology to help describe the dataset to prospective users. These triples are largely concerned with providing simple statistics for the number of triples, subjects, predicates, and objects in the tabular user data for the dataset. We also provide those statistics broken out by class and predicate for triples that are created from tabular data. A full description of the VoID ontology can be found here.
Example - VoID ontology
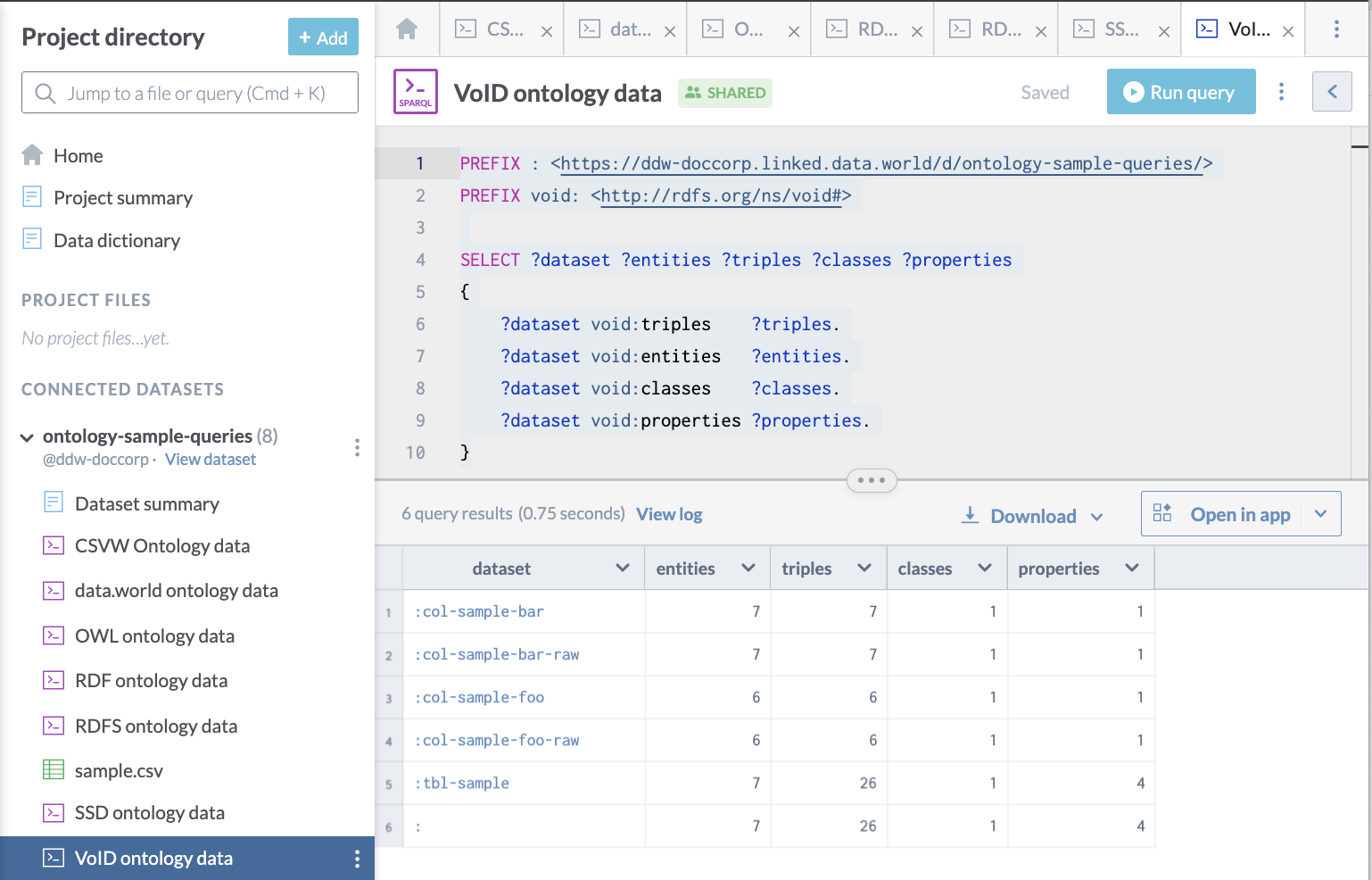
Here is a query used to access VOID metadata for a data.world dataset, showing simple graph statistics:
PREFIX : <https://ddw-doccorp.linked.data.world/d/ontology-sample-queries/>
PREFIX void: <http://rdfs.org/ns/void#>
SELECT ?dataset ?entities ?triples ?classes ?properties
{
?dataset void:triples ?triples.
?dataset void:entities ?entities.
?dataset void:classes ?classes.
?dataset void:properties ?properties.
}Here is what it looks like on data.world:
DW ontology
Finally, data.world produces a variety of miscellaneous triples for each dataset, storing a variety of extra information calculated during ingest. Perhaps the most useful of these triples are those giving the identifiers for the current dataset version, including agentId, datasetId, and versionId. This can be used for specifying back-in-time queries. Other triples created describe:
spatial data extents
temporal data extents
data inspection results
entity matching recommendations
hashed fingerprints of data used for column matching purposes
Most of these will not be useful for most query use cases.
Example - DW ontology
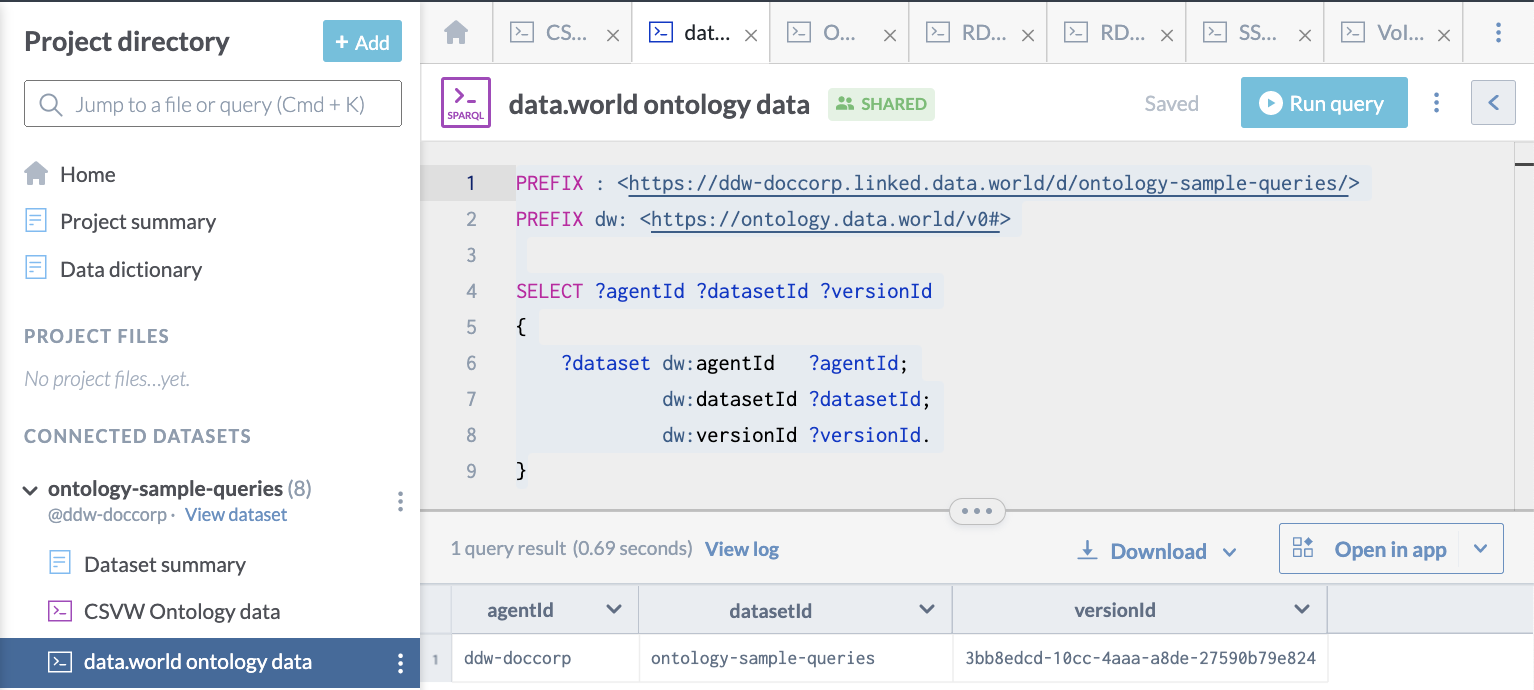
Here is a query using the data.world dataset description ontology to find the agent id, dataset id, and version id of the current dataset :
PREFIX : <https://ddw-doccorp.linked.data.world/d/ontology-sample-queries/>
PREFIX dw: <https://ontology.data.world/v0#>
SELECT ?agentId ?datasetId ?versionId
{
?dataset dw:agentId ?agentId;
dw:datasetId ?datasetId;
dw:versionId ?versionId.
}This is what it looks like on data.world: