About data extraction and virtualization
About data virtualization
Data virtualization facilitates a secure connection between a database and the platform without the necessity to move the data physically. You can achieve this by establishing connections to your data sources using the Connection Manager.
With this feature, you can execute queries on data exceeding the dataset size limits on the platform. When a live table query is conducted, the system translates your query from the platform's native SQL dialect to the target system's SQL dialect. The target system then processes the query on its hardware and returns the results for display.
Your data remains up-to-date as it continues to reside at the source and is not stored on the platform. Consequently, any changes done at the source are immediately reflected when querying the data, facilitating access to the most current data version without any need for manual updates or data synchronization.
Note
Cloud database providers often charge based on either the query execution time or the total data scanned during the query. In such cases, running queries on live tables in data.world will incur charges on those systems.
About data extraction
Data extraction is a feature that retrieves data from various data sources and stores it on the platform for in-depth analysis. Thus, it allows for effortless integration and manipulation of data within the platform.
This method is particularly effective when dealing with small or medium-sized data chunks, preferably under 3GB, as it enhances the efficiency of your queries. For larger amounts of data, consider dividing them into separate datasets or utilizing the data virtualization feature.
Data stored through extraction in the platform is securely encrypted, safeguarding your information.
To ensure data currency, it's advised to sync it with the source regularly. You can opt for manual uploads or set automatic syncing – hourly, daily, or weekly, customizable on the dataset overview. Learn more about syncing options on the Configuring sync options for datasets page.
Key differences between data extraction and virtualization
Feature | Data extraction | Data virtualization |
|---|---|---|
Data location | Data is pulled from the source and stored on the platform. | Data stays at its source location. |
Data size | Ideal for small or medium-sized data, under 3 GB. | Ideal for data that surpasses dataset size limits in data.world. |
Query performance | Provides improved performance as data is stored on the platform. | Performance relies on the source system and network latency. |
Synchronization | Data needs periodic updates or synchronization according to source changes. | Offers real-time data access, negating the need for synchronization. |
Data security | Data is securely encrypted when stored on the platform. | Data stays in the source system, only results from the query are returned. |
Cost | Involves no additional charges for executing queries. | May involve charges from cloud database providers when executing queries. |
Choosing a data access technique based on data size
The following table will help you decide which data access method would work best for your data size.
The choice of data access technique is influenced by several elements, primarily the size of the data and the frequency of updates.
We categorize data into small, medium, or large size according to their size, defined as follows:
Data size | Your data size range | Your data update frequency | Data access technique recommended to use |
|---|---|---|---|
Small | Less than 100MB | Infrequent | Data extraction |
Hourly | Data extraction | ||
Real-time | Data virtualization | ||
Medium | 100MB - 3GB | Infrequent | Data extraction |
Hourly | Data extraction | ||
Real-time | Data virtualization | ||
Large | More than 3GB | Infrequent | Data virtualization |
Hourly | Data virtualization | ||
Real-time | Data virtualization |
Here is a breakdown of these approaches:
Small data size: Extract your data into the platform to enhance query performance. As the data size is small, it will not exceed the platform's size limits, and regularly scheduled synchronization can easily manage any updates.
Medium data size: Consider using data extraction to import non-sensitive data onto the platform for improved query efficiency. For sensitive data, utilize data virtualization to keep the data at its original source, thereby boosting data security.
Large data size: For datasets that are too large to import without exceeding the platform's size limits, consider employing data virtualization. This approach keeps the data at its original source, offering seamless access to the latest data without the necessity for synchronization schedules.
How does my data update in data.world?
When using data extraction, if the data in your source is updated, you would need to manually upload the updated version of the data to data.world. The updated version will overwrite the existing one.
Sync options allows your data to be updated automatically to match its source. The available sync options include not syncing at all, syncing hourly, daily, or weekly. This setting impacts all files in the dataset that can be synced. These sync settings can be modified and viewed on the overview screen for a particular dataset. Syncing can also be done manually anytime. You can learn more about syncing your data at Syncing your data page.
With data virtualization, the data remains at the original source and is not stored on data.world. Therefore, any changes made to the source data will immediately show when the data is queried through data.world. This ensures you always have the most current version of the data without the need for manual updates or synchronization.
Ensuring data security
Establishing secure connections using data.world Bridge
data.world Bridge facilitates a secure, outbound-only method for data virtualization - a significant feature for organizations with stringent security and compliance needs. Make certain your network and firewall settings allow traffic from data.world Bridge to your servers. For more details, visit the Configuring data.world bridge for data virtualization page.
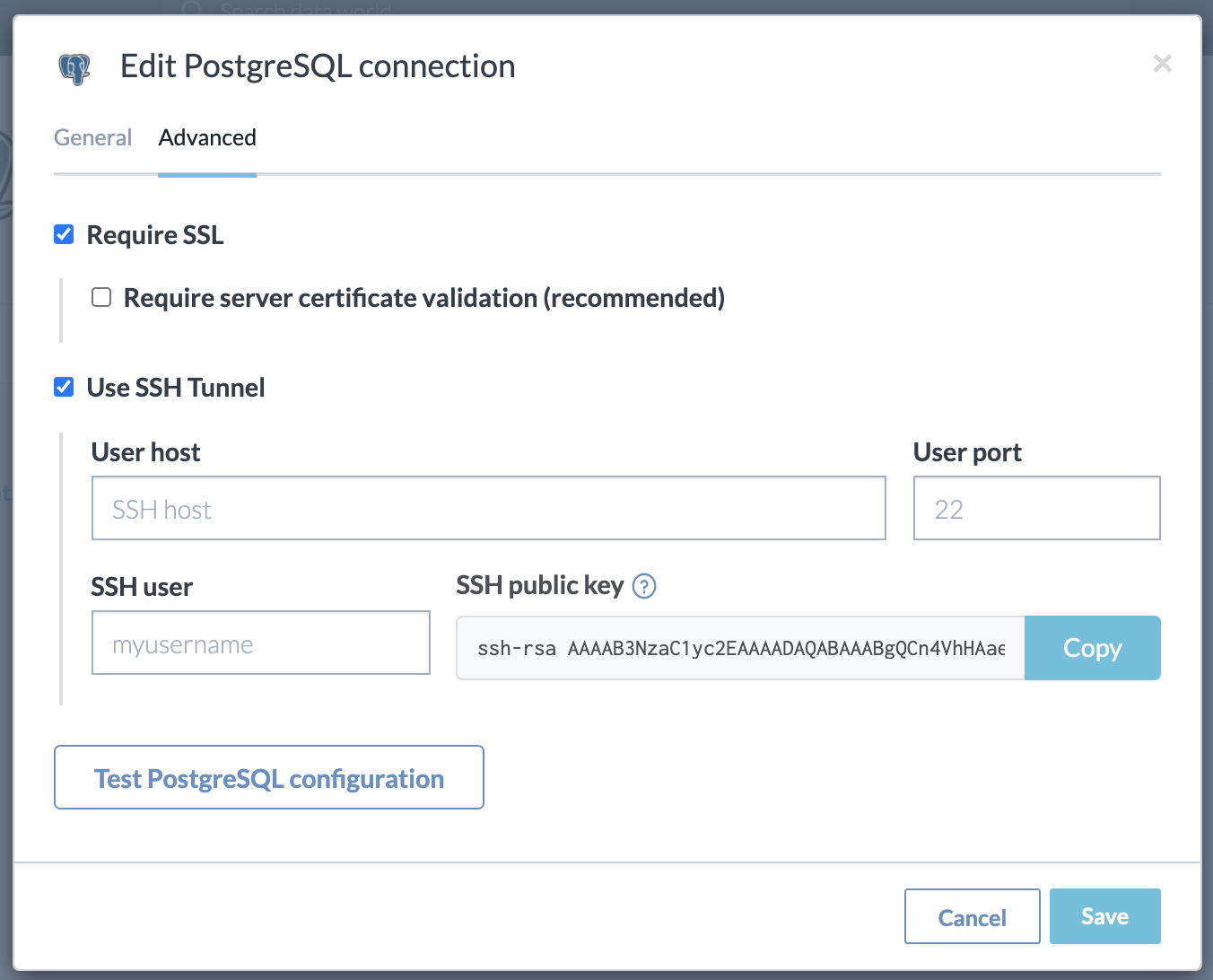
Establishing secure connections using SSH tunnel
Data.world provides an optional feature to set up an SSH tunnel when establishing a connection to a database server. While this method requires some setup by the network administrator, it is more secure than a direct connection.
This method is recommended for connecting database servers to data.world due to its ease, flexibility, and security. No additional hardware is needed beyond a bastion server, a standard feature in many organizations' infrastructure.
For added security, data.world provides user-specific SSH public keys that should be configured on the bastion server (in '.authorized_keys) to confirm that traffic originates from data.world.
Managing sensitive data
If there is sensitive data in the file that you would like to mask you can either modify your query to exclude or mask the data, or use a custom_types.ttl file to set the column to a masked data type.