Tabular files
data.world supports upload of tabular data via CSV, TSV, and Microsoft Excel files. To query tabular data via SPARQL, data.world creates IRIs representing tables, columns, and rows, and triples for your data.
IRIs
We create the IRIs in the following forms:
Type | Format |
|---|---|
Table | http://<agent_id>.linked.data.world/d/<dataset_id>/tbl-<table_name> |
Column | http://<agent_id>.linked.data.world/d/<dataset_id>/col-<table_name>-<column_name> |
Row | http://<agent_id>.linked.data.world/d/<dataset_id>/row-<table_name>-<row_index> |
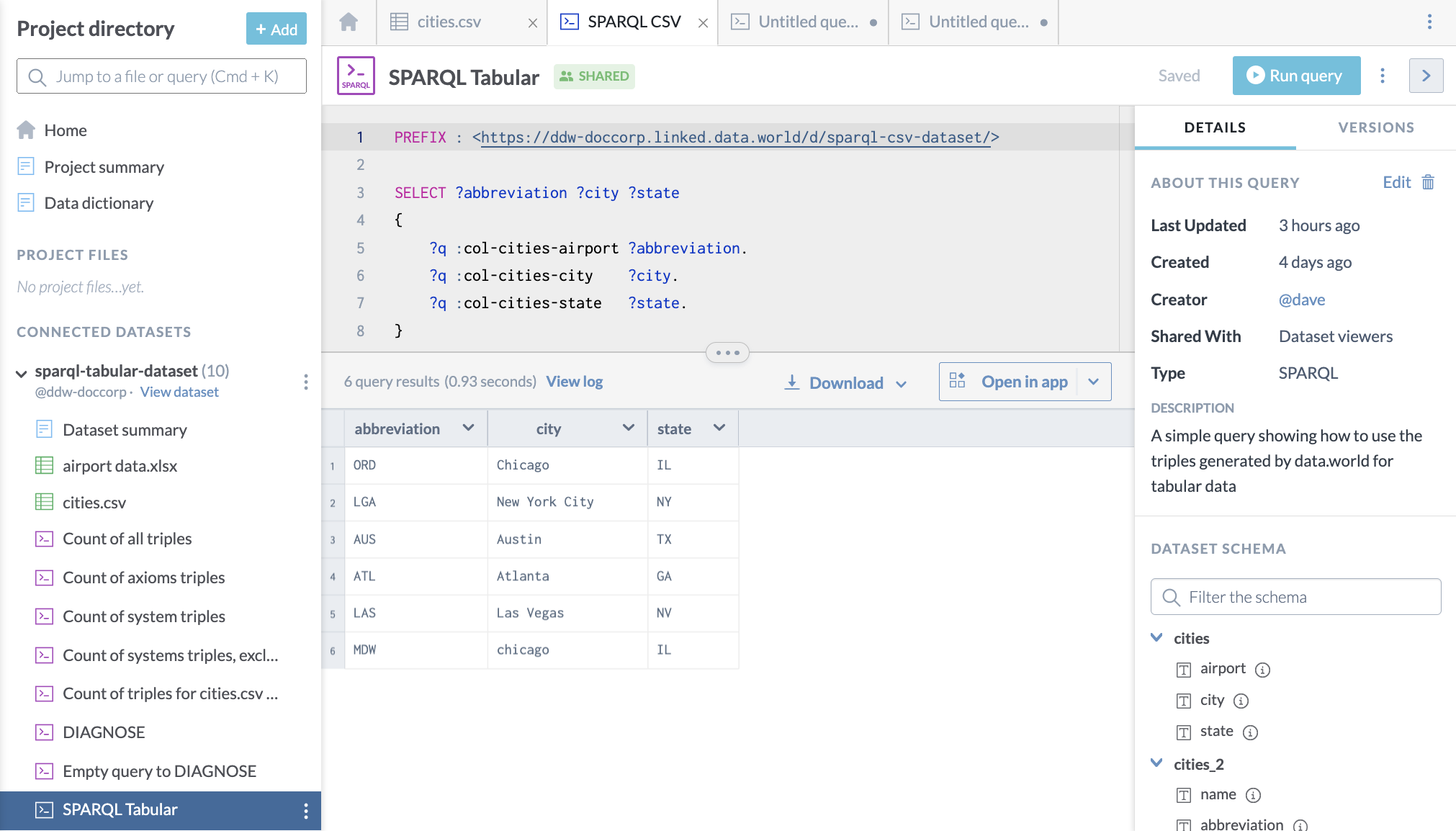
IRIs for tables and columns are available in a dataset or project workspace in the query window for any SPARQL query window. With the query showing in the middle pane, click on any table or column name in the right sidebar to get the IRI:
Triples
The triples we create for tabular data are very minimal. There are only two important kinds. They are:
Purpose | triple format |
|---|---|
Rows in a table | <row_iri> a <table_iri> |
Non-empty cells in a row | <row_iri> <column_iri> <cell_value> |
By connecting those two sorts of triples together we can find any data in the table.
We also produce some additional triples for tabular data, to allow navigation between the rows of a table:
Purpose | Triple |
|---|---|
To get to the first row of a table | <table_iri> <https://ontology.data.world/v0#firstRow> <row_iri> |
To get to the last row of a table | <table_iri> <https://ontology.data.world/v0#lastRow> <row_iri> |
To get to the next row | <row_iri> <https://ontology.data.world/v0#nextRow> <next_row_iri> |
To get to the previous row | <row_iri> <https://ontology.data.world/v0#prevRow> <prev_row_iri> |
To get to a specific row given its index | <row_iri> <https://ontology.data.world/v0#rowNum> <index of row> |
Note
We do not create any triples for for empty cells. If a cell in a table is empty and you wish your query to return that fact, you’ll need to use the SPARQL OPTIONAL pattern.for empty cells.
Naming rules
When you upload a tabular file to data.world we create a unique (within the context of the dataset) and manageable name for the table and for every column in it.
For tables, the name is derived from the name of the file using the following format:
Conversion to lowercase
All non-numeric characters changed to underscores
If there is already a table in the dataset with the same name, the new table is suffixed with an underscore and a number.
For Excel files, each spreadsheet is treated as its own table. The name is generated from the sheet name (if it exists) or from the filename (if it does not).
Column names are handled similarly, starting with the column name as read or inferred from the tabular file. In this way we guarantee that the IRIs generated are unique and well-formed.
Example - Tabular
Here is an example of a SPARQL query written against a tabular data source:
PREFIX : <https://ddw-doccorp.linked.data.world/d/sparql-csv-dataset/>
SELECT ?abbreviation ?city ?state
{
?q :col-cities-airport ?abbreviation.
?q :col-cities-city ?city.
?q :col-cities-state ?state.
}This is what it looks like when run on data.world: