Discover and catalog sensitive data
Warning
This feature is currently in Public preview and is not widely available to all customers. Keep in mind that you will need to purchase an add-on to use this feature. For more details, please reach out to your Customer Success specialist.
What is Sensitive Data Classification?
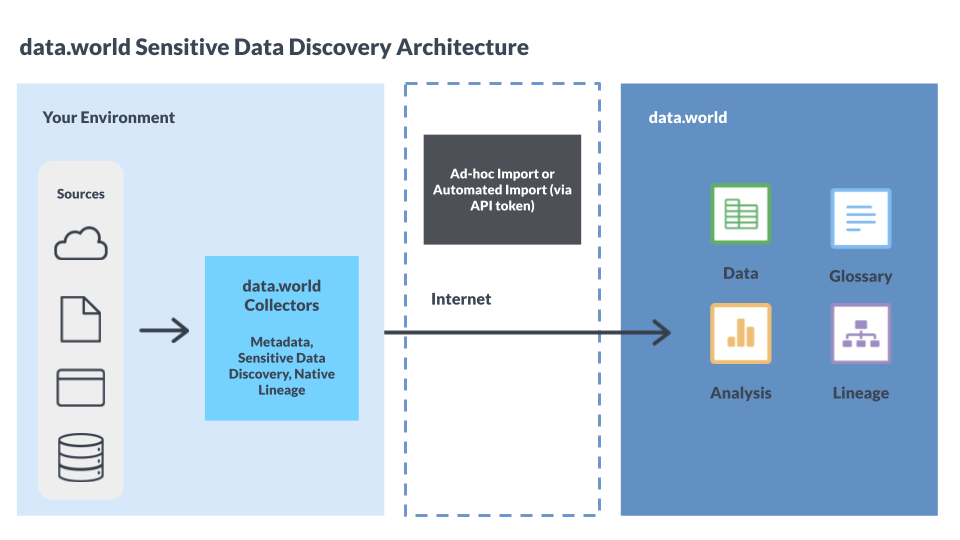
Sensitive Data Classification is a method that employs machine learning to automatically identify and categorize sensitive data in your source technology. Sensitive data can be Personal Identifiable Information (PII), Protected Health Information (PHI), or Payment Card Industry (PCI) information, to name a few. After scanning the source technology and classifying the data, the collector uploads this classification metadata to data.world. Users can then view these classifications for resources cataloged from their source technology.
Collectors can scan any table, accessible via SQL, that contains at least one row of data. It does not have a limit on the number of tables it can scan. Tables are scanned at the column level.
Note
The scans are performed on your source technology. However, it does not perform scans on live connected datasets or virtualized data assets within data.world.
The collector selects data from each table to classify by querying the first n rows in the table, where n is the selected sample size. If the table has fewer than n rows, then the collector will query all the rows. The sampling uses TABLESAMPLE where it is available, and depending on the implementation in the database, the actual number of rows sampled may vary.
Sensitive Data Classification utilizes third-party Sensitive Data Discovery service, Microsoft Presidio or ServiceNow Vault Discovery, to categorize your data. The collectors take a sample of data from the source technology, sends the sampled data to the third-party Sensitive Data Discovery service provided by the user for classification, and then captures the classifications in the collector output.
Key Features
Sensitive Data Classification consists of four main features:
Scan: The tool scans multiple data sources. It uses pre-trained machine learning to instantly identify over 30 types of sensitive data.
Classification: This feature allows you to distinguish between various types of sensitive data and apply specific rules for handling each type. For example, the term confidential could have a unique meaning within your organization. By applying the confidential classification, you can apply your business logic to the data.
Action: All the information obtained is completely reportable. You can generate a report detailing all your assets, including the sensitive data types and classifications applicable to them.
Integration: Finally, you have the option to export these reports to your preferred BI tool to integrate them into a broader system or project.
Supported languages for the content processed from the source
The Collector can be run on content in various languages. For the complete list of languages supported for Microsoft Presidio, see the Microsoft Presidio documentation.
Which Collectors support sensitive data classification for metadata?
The Sensitive data classification feature is available for the following collectors:
What data is scanned by the collectors for sensitive data classification?
Object | Data scanned |
|---|---|
Column |
|
Sensitive Data Classification Provider |
|
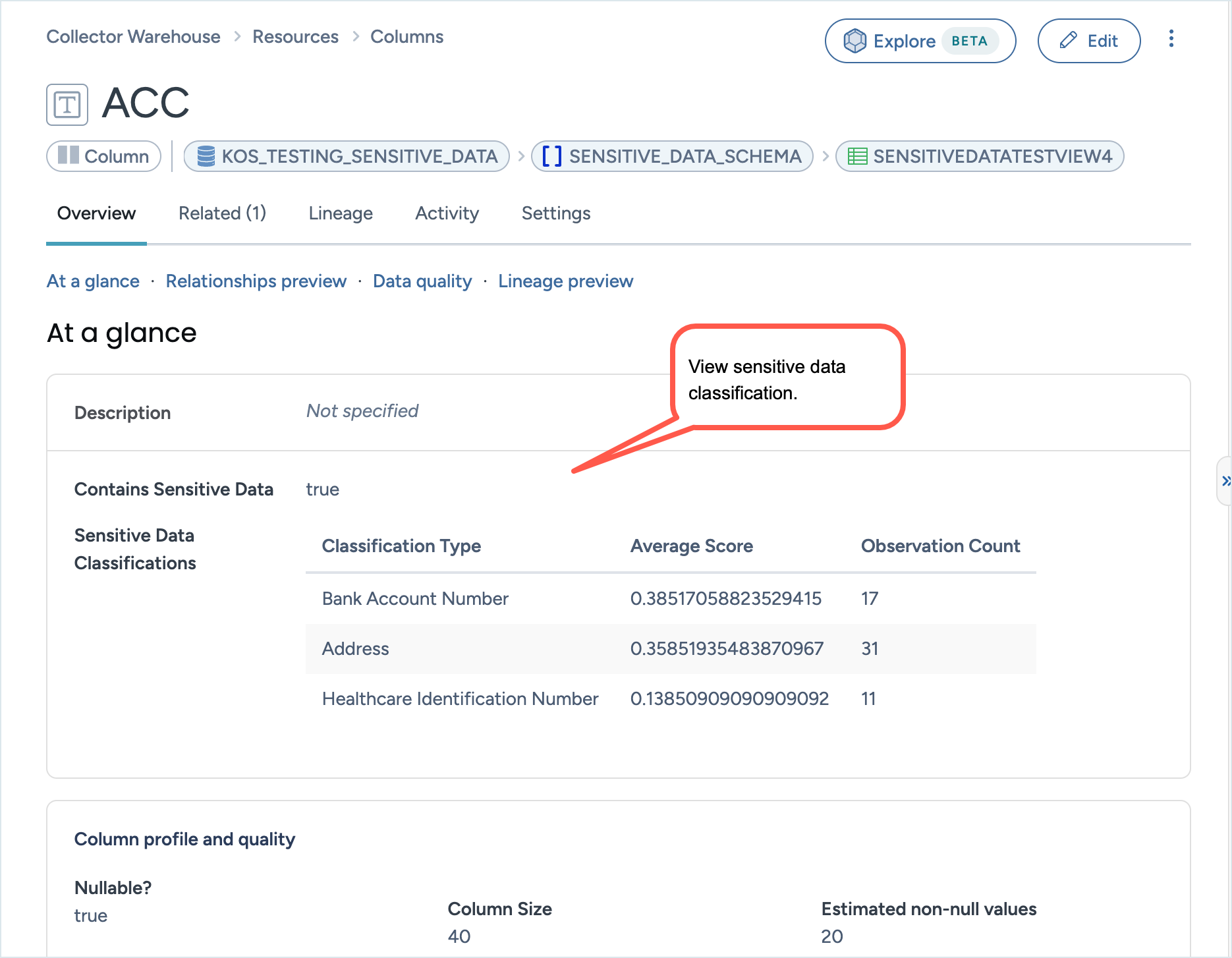
A sample view of sensitive data classification information for metadata:
Browse to the resources to see the type of sensitive data.
On various product pages such as Search results, Resources, use the Sensitive Type filter to narrow down lists by sensitive types attached to the resources.
Setting up an instance of third-party Sensitive Data Discovery service
Depending on where your collectors are deployed, there are two ways to connect to a third-party Sensitive Data Discovery service instance: one for on-premise environments and one for cloud deployments.
If you are running collectors on-premise, you must set up one of the following third-party Sensitive Data Discovery service:
Set up Microsoft Presidio, within your environment and configure the collectors to connect to it using the base URL. For assistance with setup and licensing, please contact your customer service representative.
Set up a ServiceNow instance. The ServiceNow Data Privacy plugin (com.glide.data_privacy) must be activated.
If you are running collectors in the cloud, the collectors will automatically use the data.world–hosted third-party Sensitive Data Discovery service. No additional configuration is required in this case.
Enabling Sensitive Data Classification for metadata
You can enable profiling for metadata by using the following optional parameters for the collectors that support sensitive data classification.
Important
Before you begin, ensure that the Sensitive Data Classification module is deployed and configured through CTK.