Setting up Popularity Analytics
What is Popularity Analytics?
Popularity analytics helps data consumers find the trending or popular resources that are available in the application. It helps data producers and stewards focus their time and energy on the things that provide the most value, and spend less time (or even remove / curate away) content that is less valuable.
Pre-requisites: Metrics Dataset
Popularity Analytics uses the Metrics of the organization to identify the popularity of the resources. Before you begin you must make sure have the Metrics dataset is configured in your organization. For details, see Metrics for the catalog.
STEP 1: Configure the metadata profile for popularity
To configure the metadata profile for people:
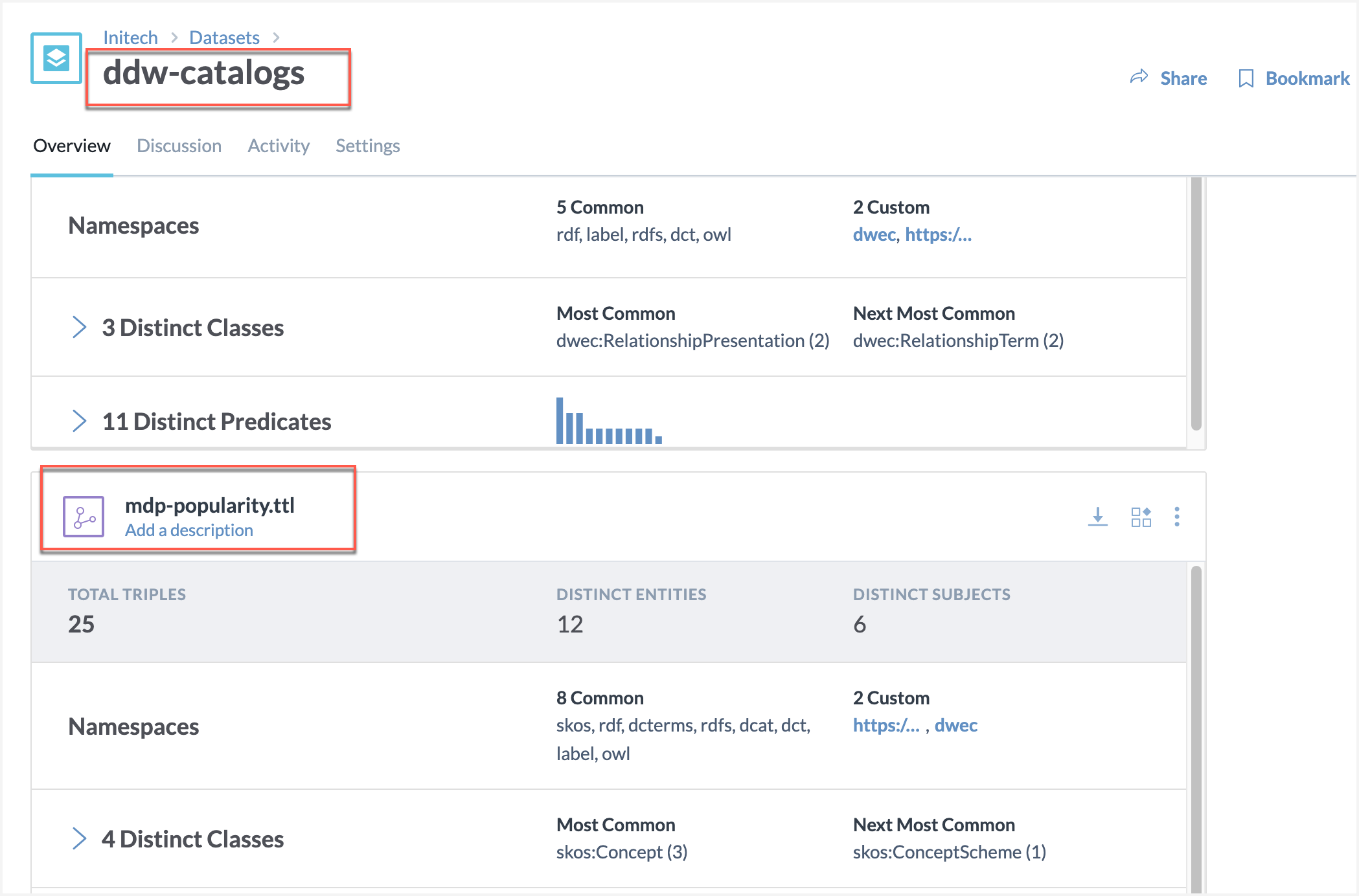
Prepare the mdp-popularity.ttl file by doing the following:
Copy the following ttl file contents in a text editor.
Replace yourorgname with the name of your organization.
For dwec:forType property, specify the resources for which you want to enable the Popularity field. For example, set the value as dwec:DwDataset, dwec:DatabaseTable, dwec:DatabaseColumn, dwec:BusinessTerm ; to enable for datasets, tables, columns, and business terms.
Save the file as mdp-popularity.ttl on your machine.
Upload the mdp-popularity.ttl file to the ddw-catalogs dataset.
Note
This file goes in the ddw-catalogs dataset.
Note
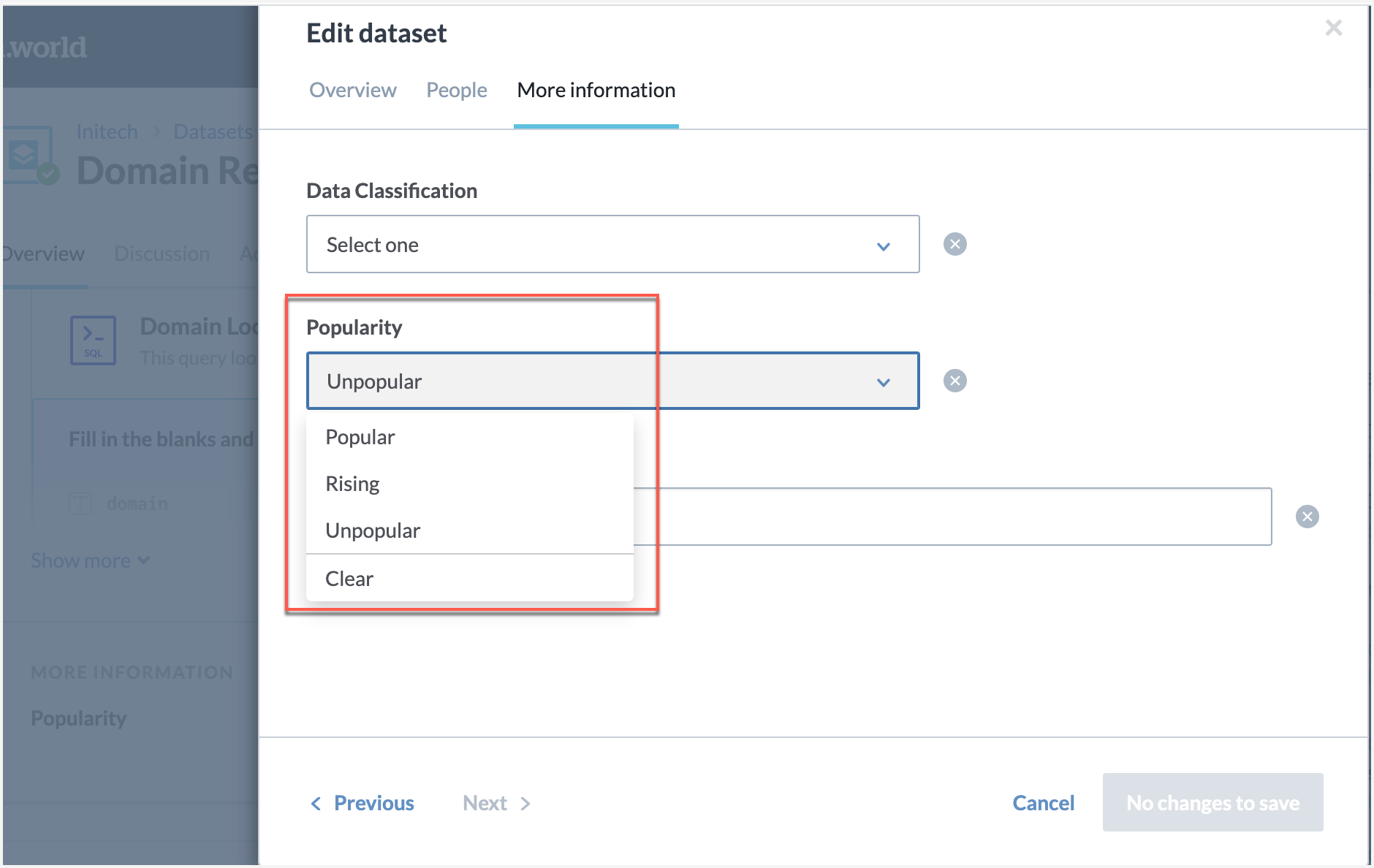
Success! Browse to the resource in your organization for which you enabled the field (for example, dataset) and you should see a new Popularity option.
STEP 2: Create Popularity Analytics Project and Link to Metrics Dataset
In this section, we create the Popularity Analytics project and link it with the Metrics dataset in the organization.
To create the project:
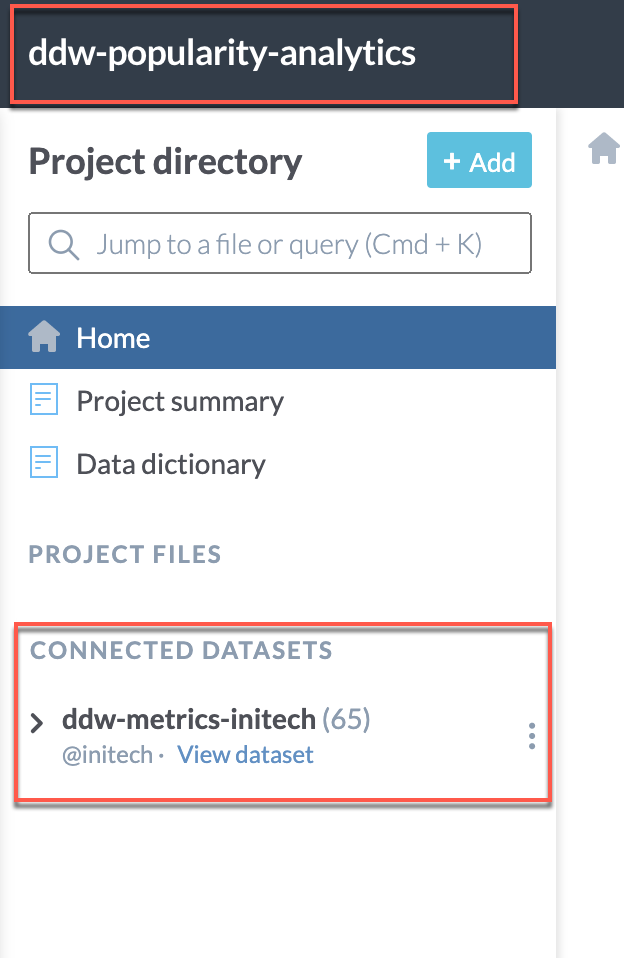
Create a project called ddw-popularity-analytics.
On the Project details page, click the Launch Workspace button.
Link the dataset ddw-metrics (this name will be different for your organization) to the project by clicking Add > Dataset.
STEP 3: Configure Eureka Automation for Metadata Popularity
STEP A: Add and Run the Metadata Popularity SQL Query
Note
What does this query do?
The query creates a valuation scores based on 2 metrics - number of views and number of edits on the metadata resources. By default, both views and edits have the same weights. The valuation score is calculated for two different time periods. By default, it is 14 and 60 days. The popularity rank is calculated by a cumulated distribution over the valuation score. Based on the popularity rank, the metadata resources are categorized as - Popular, Unpopular, Rising. A metadata resource is popular if it's the top 20th percentile (the default value), unpopular if it's in the bottom 20th percentile and rising if was unpopular in the last 60 days but it is popular in the last 14 days.
The default values can be changed.
You can find technical details about this query in the reference information section.
To add and run the SQL query:
In the ddw-popularity-analytics project, add a new SQL Query.
Save the following query with the name metadata-popularity
DECLARE ?views_wt AS INTEGER = 1 DECLARE ?edit_wt AS INTEGER = 1 DECLARE ?daysbackStart AS INTEGER = 14 DECLARE ?daysbackFinish AS INTEGER = 60 DECLARE ?popularity AS DECIMAL = .2 WITH valuationStart as ( SELECT resourcetype, resource, sum(views * ?views_wt + edits * ?edit_wt) AS valuation_score, sum(views) as views, sum(edits) as edits FROM events_catalog_resources_pages_activity_by_day where date > DATE_SUB(now(), ?daysbackStart, "day") GROUP BY resourcetype, resource ), valuationFinish as ( SELECT resourcetype, resource, sum(views * ?views_wt + edits * ?edit_wt) AS valuation_score, sum(views) as views, sum(edits) as edits FROM events_catalog_resources_pages_activity_by_day where date > DATE_SUB(now(), ?daysbackFinish, "day") GROUP BY resourcetype, resource ), rankStart as ( SELECT resourcetype, resource, valuation_score, CUME_DIST() OVER (PARTITION BY resourcetype ORDER BY valuation_score DESC) as popularity_rank FROM valuationStart ), rankFinish as ( SELECT resourcetype, resource, valuation_score, CUME_DIST() OVER (PARTITION BY resourcetype ORDER BY valuation_score DESC) as popularity_rank FROM valuationFinish ) select finish.resource, finish.resourcetype, finish.popularity_rank as popularity_rank_finish, start.popularity_rank as popularity_rank_start, if(start.popularity_rank <= ?popularity,"Y","N") as popular, if(start.popularity_rank >= (1-?popularity),"Y","N") as unpopular, if(start.popularity_rank <= ?popularity and finish.popularity_rank > ?popularity,"Y","N") as rising from rankFinish finish left join rankStart start on finish.resource = start.resource and finish.resourcetype = start.resourcetype order by finish.popularity_rank ascNext, run the query and save the result of the query as a file in the ddw-popularity-analytics project.
In the Query results page, click Download and select Save to dataset or project.
In the Choose how data updates window, select the Use data extract option.
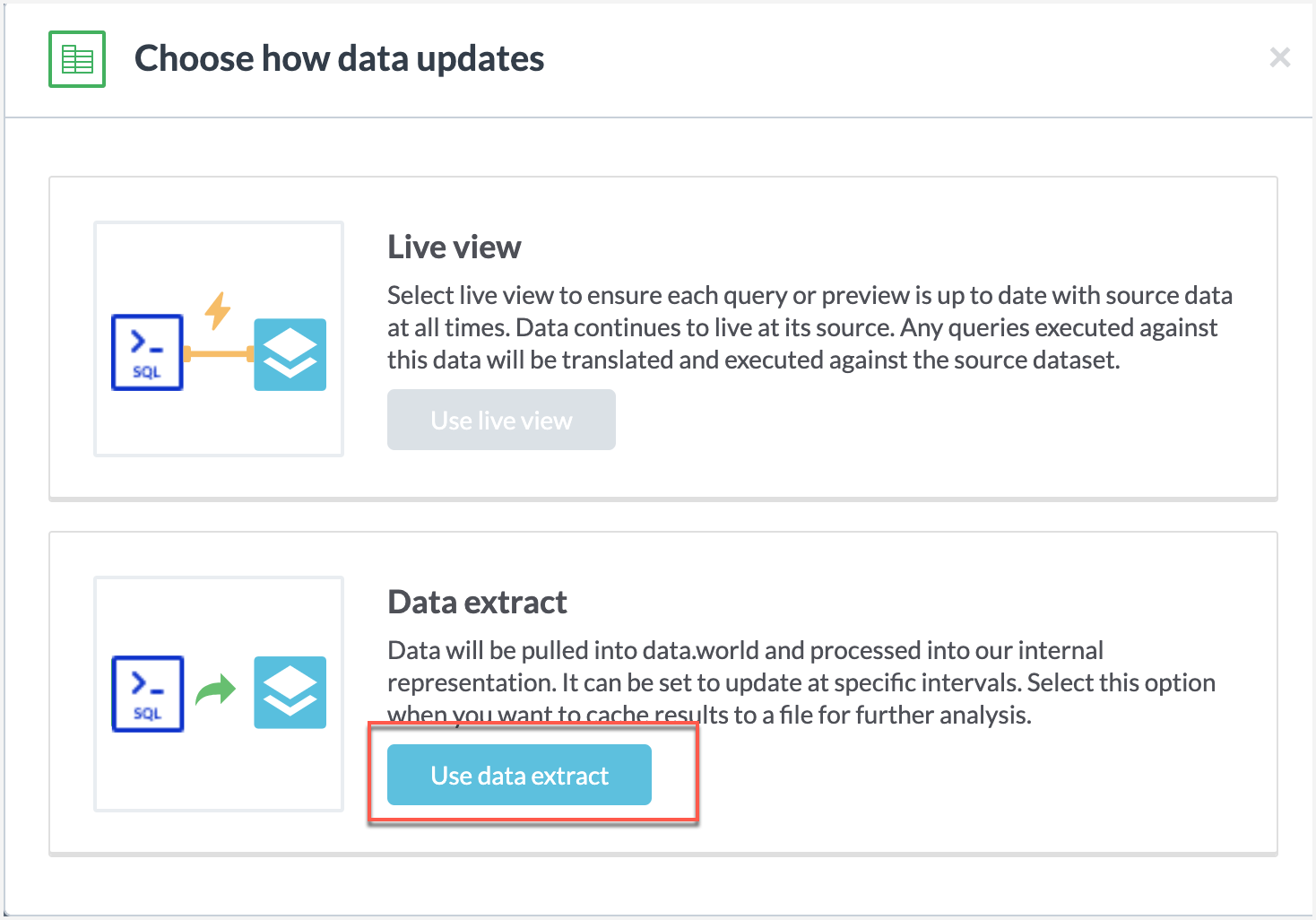
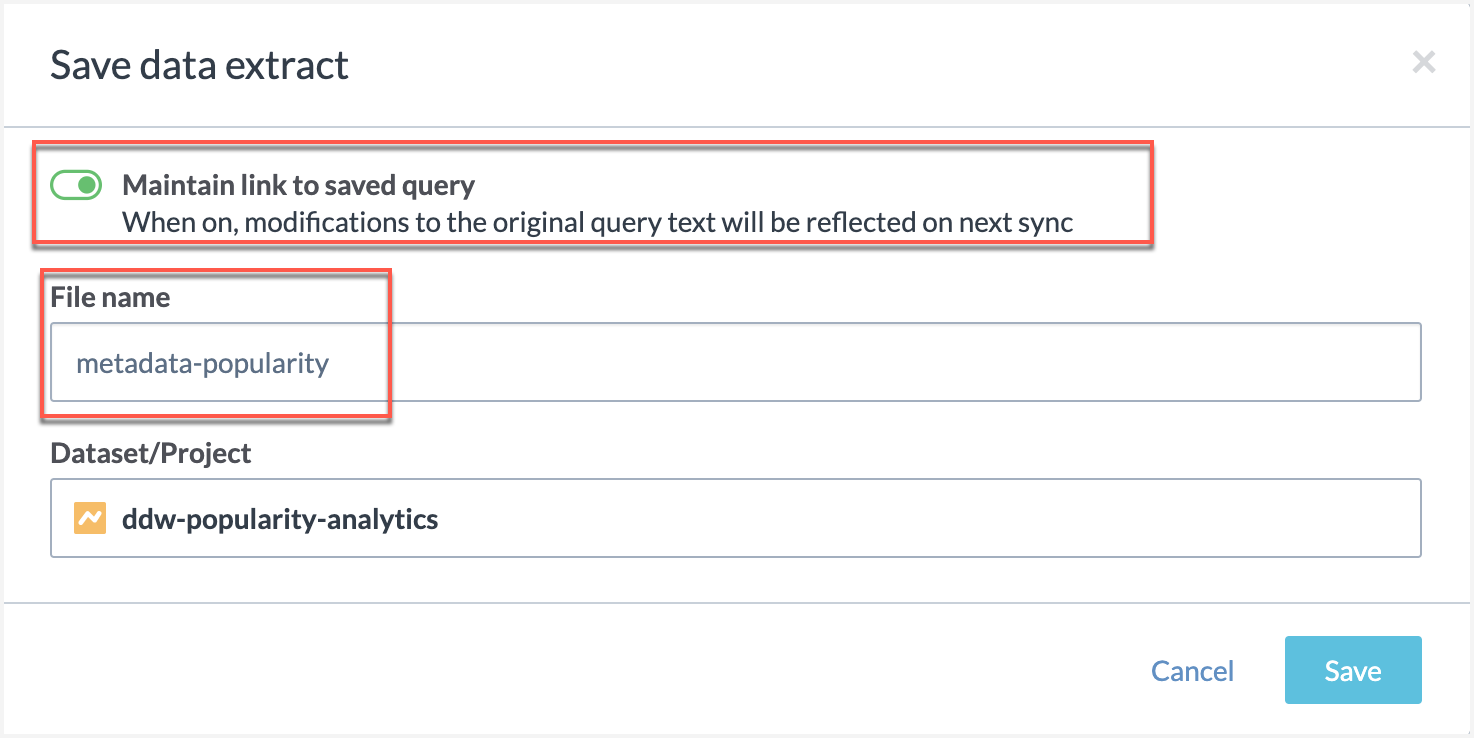
In the Save data extract window, enable the Maintain link to saved query and save the file with the name metadata-popularity.
Note
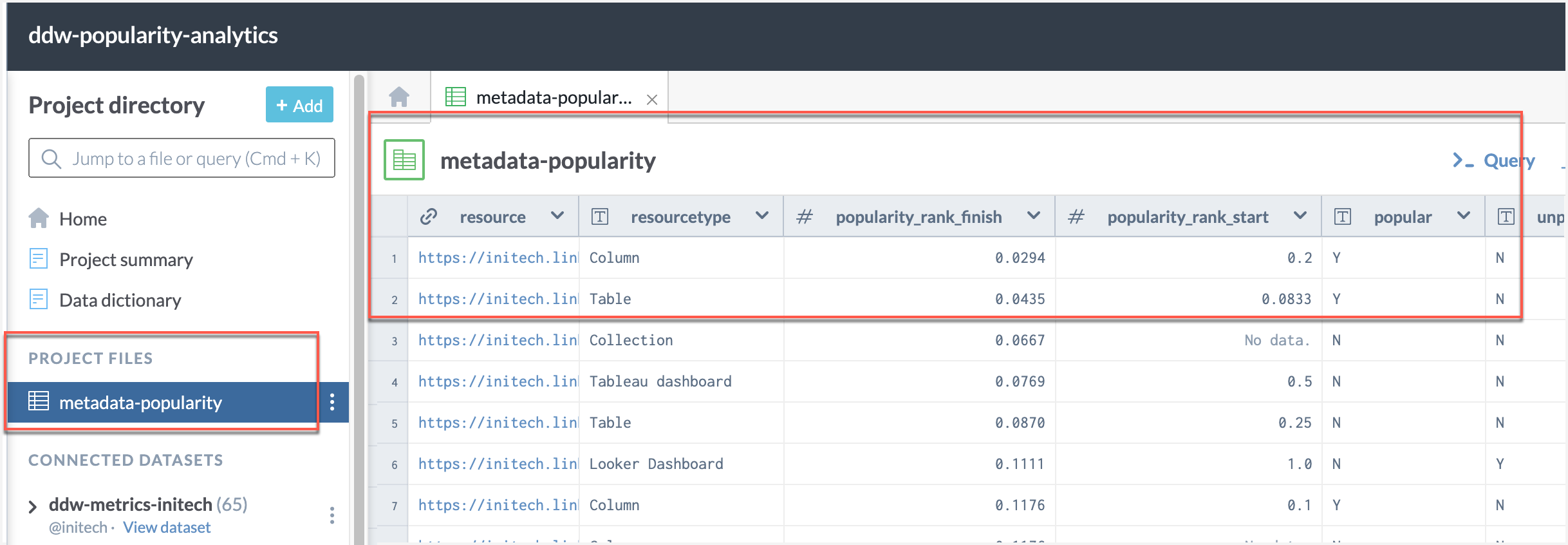
Success!
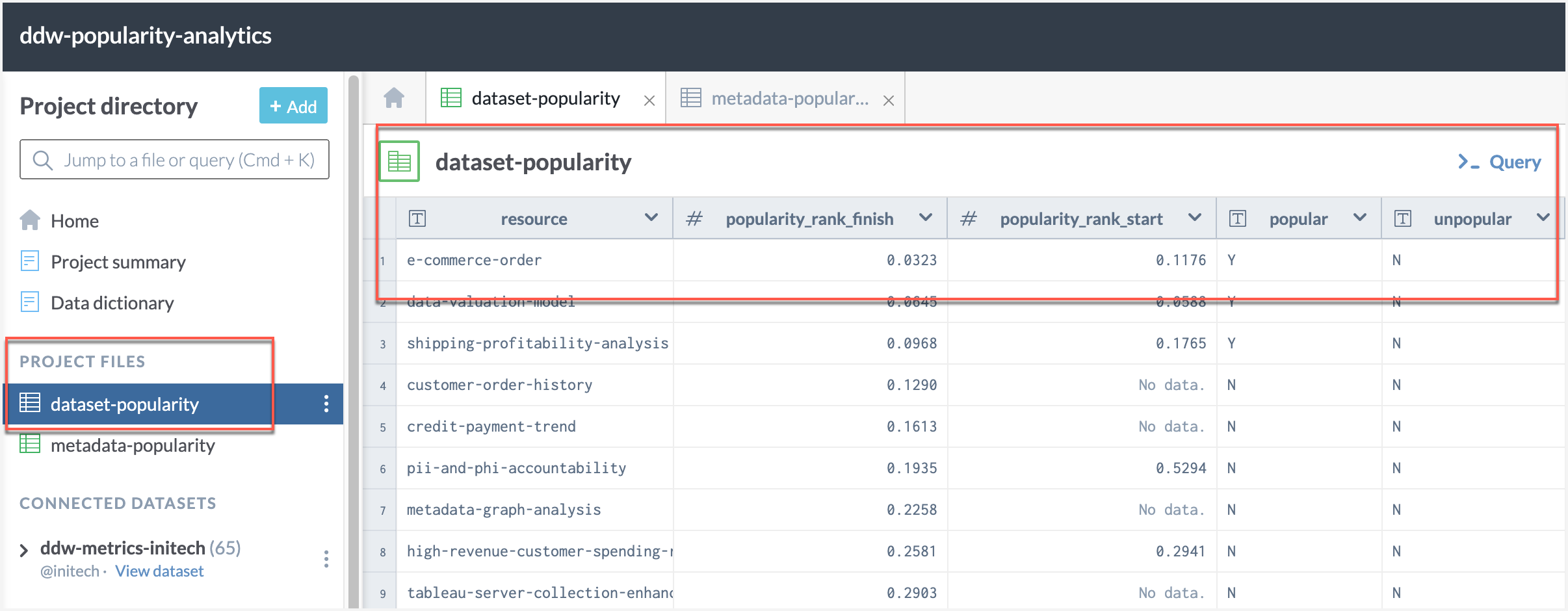
You will now see the metadata-popularity file under the Project Files.
STEP B: Add Eureka Automation SPARQL query for Metadata Popularity
In the ddw-popularity-analytics project, add a new SPARQL Query.
Add the following query. Replace yourorgname with the name of your organization.
PREFIX popularity: <https://yourorgname.linked.data.world/d/ddw-popularity-analytics/> PREFIX : <https://yourorgname.linked.data.world/d/ddw-catalogs/> CONSTRUCT { ?iri :popularity ?popularityAnnotation . } WHERE { [ a popularity:tbl-metadata_popularity ; popularity:col-metadata_popularity-resource ?iri ; popularity:col-metadata_popularity-popular ?popular ; popularity:col-metadata_popularity-unpopular ?unpopular ; popularity:col-metadata_popularity-rising ?rising ; ] . VALUES ?nil { UNDEF } BIND(IF(?popular = "N" && ?unpopular = "N" && ?rising = "Y", :popularity_rising, IF(?popular = "N" && ?unpopular = "Y" && ?rising = "N", :popularity_unpopular, IF(?popular = "Y" && ?unpopular = "N" && ?rising = "N", :popularity_popular, ?nil))) AS ?popularityAnnotation) }Save the query with the name popularity-metadata.ttl.rq
STEP C: Run the Eureka Automation for Metadata Popularity
Run the popularity-metadata.ttl.rq SPARQL query from the previous step.
From the Results page, select Download the results > Save to dataset or project.
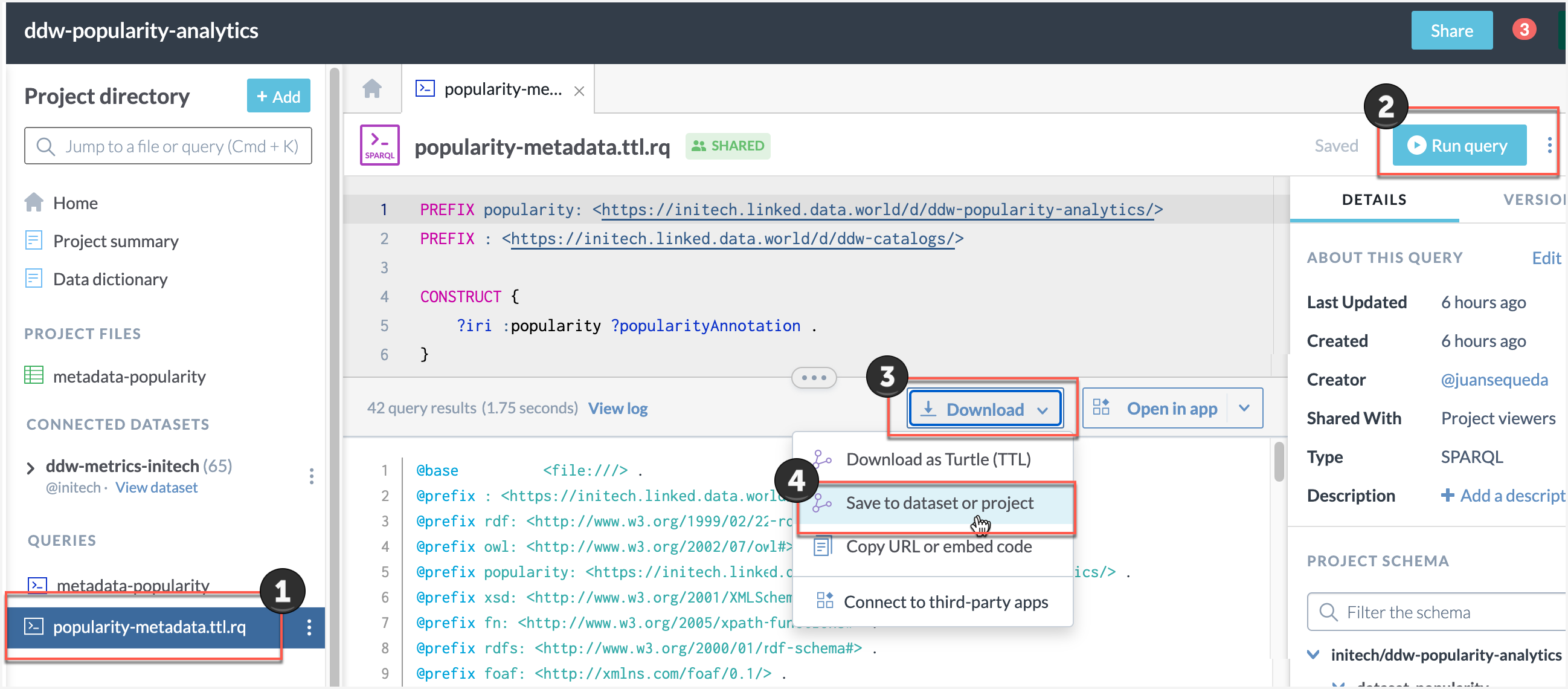
In the Save data extract window:
The query name will automatically appear. Just delete the suffix .rq
Save the file to the ddw-catalogs dataset of your organization. You must set the file to auto-sync every hour.
Note
This file goes in the ddw-catalogs dataset.

STEP 4: Configure Eureka Automation for Dataset Popularity
STEP A: Add and Run the Dataset Popularity SQL Query
Note
What does this query do?
The query creates a valuation scores based on 5 metrics - page views, queries run, downloads, bookmarks, authorization requests of a dataset resources. Each metric has a corresponding weight. The valuation score is calculated for two different time periods. By default, it is 14 and 60 days. The popularity rank is calculated by a cumulated distribution over the valuation score. Based on the popularity rank, the dataset resources are categorized as - Popular, Unpopular, Rising. A dataset resource is popular if it's the top 20th percentile (the default value), unpopular if it's in the bottom 20th percentile and rising if was unpopular in the last 60 days but it is popular in the last 14 days.
The default values can be changed.
You can find technical details about this query in the reference information section.
In the ddw-popularity-analytics project, add a new SQL Query.
Save the following query with the name dataset-popularity.
DECLARE ?daysbackStart AS INTEGER = 14 DECLARE ?daysbackFinish AS INTEGER = 60 DECLARE ?queryrun_wt AS INTEGER = 5 DECLARE ?download_wt AS INTEGER = 5 DECLARE ?bookmark_wt AS INTEGER = 10 DECLARE ?authreq_wt AS INTEGER = 10 DECLARE ?popularity AS DECIMAL = .2 WITH valuationStart as ( SELECT resource, sum(pageviews + queries_run * ?queryrun_wt + downloads * ?download_wt + bookmarks * ?bookmark_wt + auth_requests * ?authreq_wt) AS valuation_score, sum(pageviews) as pageviews, sum(queries_run) as queries_run, sum(downloads) as downloads, sum(bookmarks) as bookmarks, sum(auth_requests) as auth_requests FROM events_dataset_activity_by_day WHERE date > DATE_SUB(now(), ?daysbackStart, "day") AND resource NOT LIKE "ddw%" GROUP BY resource ), valuationFinish as ( SELECT resource, sum(pageviews + queries_run * ?queryrun_wt + downloads * ?download_wt + bookmarks * ?bookmark_wt + auth_requests * ?authreq_wt) AS valuation_score, sum(pageviews) as pageviews, sum(queries_run) as queries_run, sum(downloads) as downloads, sum(bookmarks) as bookmarks, sum(auth_requests) as auth_requests FROM events_dataset_activity_by_day WHERE date > DATE_SUB(now(), ?daysbackFinish, "day") AND resource NOT LIKE "ddw%" GROUP BY resource ), rankStart as ( SELECT resource, valuation_score, CUME_DIST() OVER (ORDER BY valuation_score DESC) as popularity_rank FROM valuationStart ), rankFinish as ( SELECT resource, valuation_score, CUME_DIST() OVER (ORDER BY valuation_score DESC) as popularity_rank FROM valuationFinish ) select finish.resource, finish.popularity_rank as popularity_rank_finish, start.popularity_rank as popularity_rank_start, if(start.popularity_rank <= ?popularity,"Y","N") as popular, if(start.popularity_rank >= (1-?popularity),"Y","N") as unpopular, if(start.popularity_rank <= ?popularity and finish.popularity_rank > ?popularity,"Y","N") as rising from rankFinish finish left join rankStart start on finish.resource = start.resource order by finish.popularity_rank ascNext, run the query and save the result of the query as a file in the ddw-popularity-analytics project.
In the Query results page, click Download and select Save to dataset or project.
In the Choose how data updates window, select the Use data extract option.
In the Save data extract window, enable the Maintain link to saved query and save the file with the name dataset-popularity.
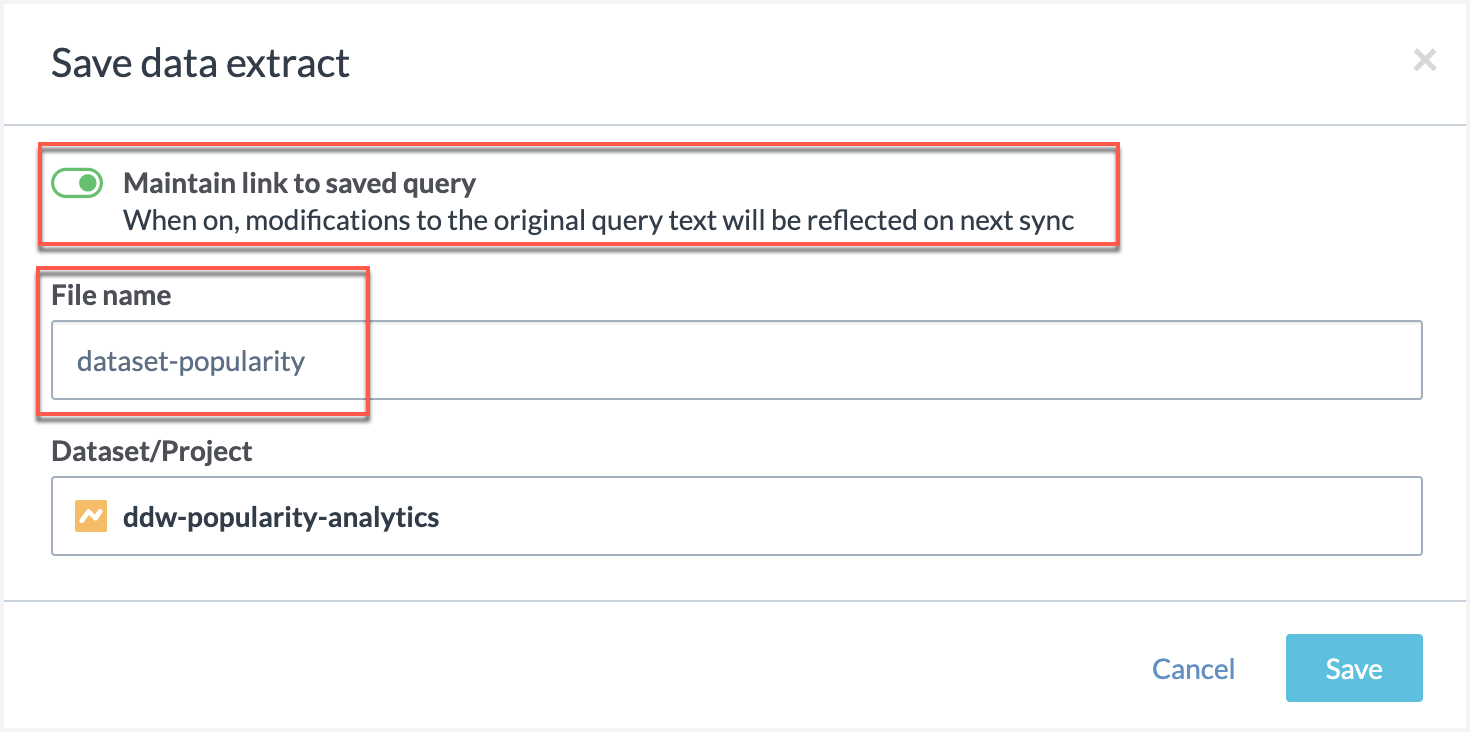
Note
Success! You will now see the dataset-popularity file under the Project Files.
STEP B: Add Eureka Automation SPARQL query for Dataset Popularity
In the ddw-popularity-analytics project, add a new SPARQL Query.
Add the following query. Replace yourorgname with the name of your organization at three places in the query.
Note
Organization name needs to be updated at 3 places!
Please note that the organization name in this query has to be updated in 3 lines in this query.
PREFIX popularity: <https://yourorgname.linked.data.world/d/ddw-popularity-analytics/> PREFIX : <https://yourorgname.linked.data.world/d/ddw-catalogs/> PREFIX dwec: <https://dwec.data.world/v0/> PREFIX dct: <http://purl.org/dc/terms/> CONSTRUCT { ?iri a dwec:DwDataset. ?iri dct:identifier ?resource. ?iri :popularity ?popularityAnnotation . } WHERE { [ a popularity:tbl-dataset_popularity ; popularity:col-dataset_popularity-resource ?resource ; popularity:col-dataset_popularity-popular ?popular ; popularity:col-dataset_popularity-unpopular ?unpopular ; popularity:col-dataset_popularity-rising ?rising ; ] . VALUES ?nil { UNDEF } BIND(IF(?popular = "N" && ?unpopular = "N" && ?rising = "Y", :popularity_rising, IF(?popular = "N" && ?unpopular = "Y" && ?rising = "N", :popularity_unpopular, IF(?popular = "Y", :popularity_popular, ?nil))) AS ?popularityAnnotation) BIND(IRI(CONCAT(STR("https://yourorgname.linked.data.world/d/"), ?resource)) as ?iri) }Save the query with the name popularity-dataset.ttl.rq.
STEP C: Run the Eureka Automation for Dataset Popularity
Run the popularity-dataset.ttl.rq SPARQL query from the previous step.
From the Results page, select Download the results > Save to dataset or project.
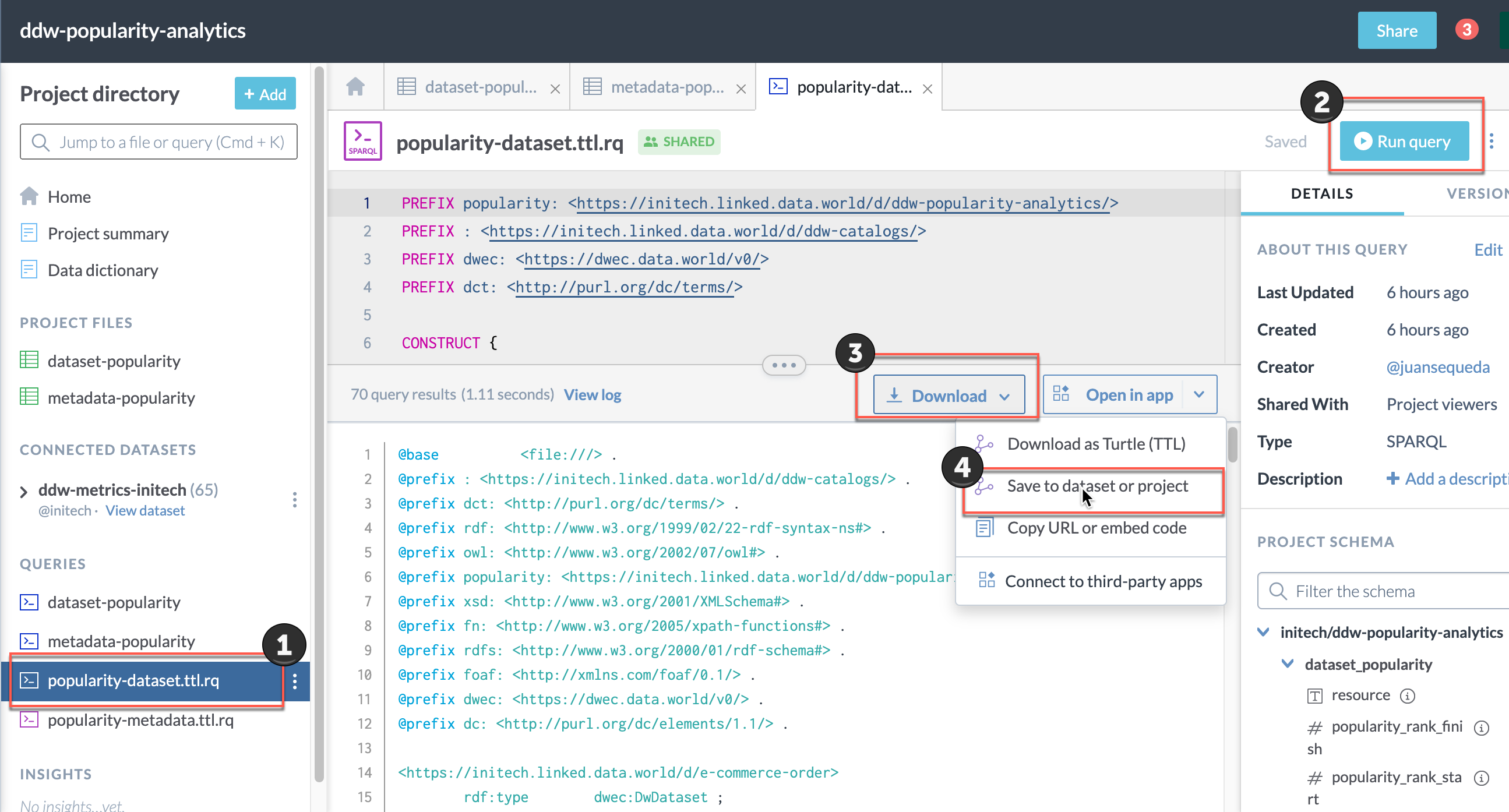
In the Save data extract window:
The query name will automatically appear. Just delete the suffix .rq
Save the file to the ddw-catalogs dataset of your organization. You must set the file to auto-sync every hour.
Note
This file goes in the ddw-catalogs dataset.

View the results🥳
Now that you have set up the popularity analysis for the datasets and metadata resources, you can:
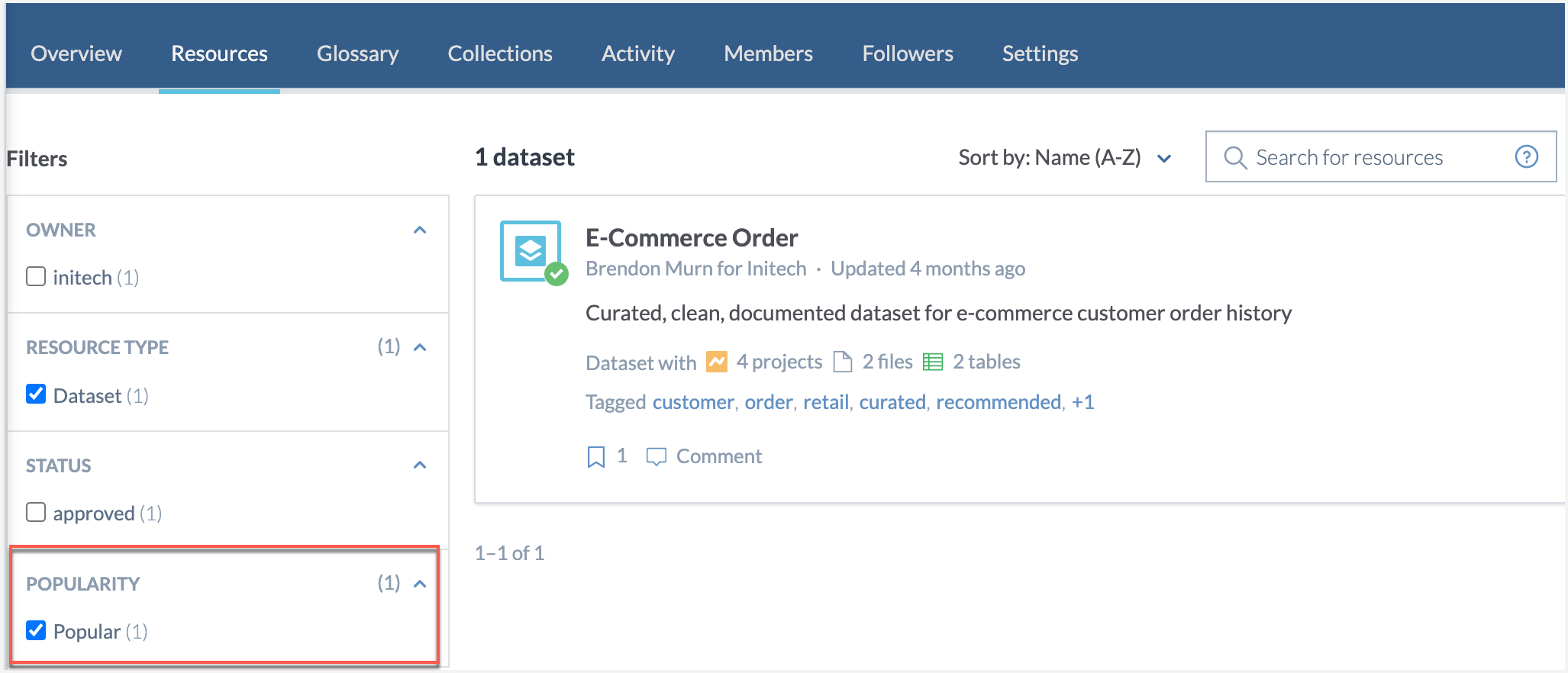
Browse to the resources to see them automatically categorized as Popular, Unpopular, and Rising!
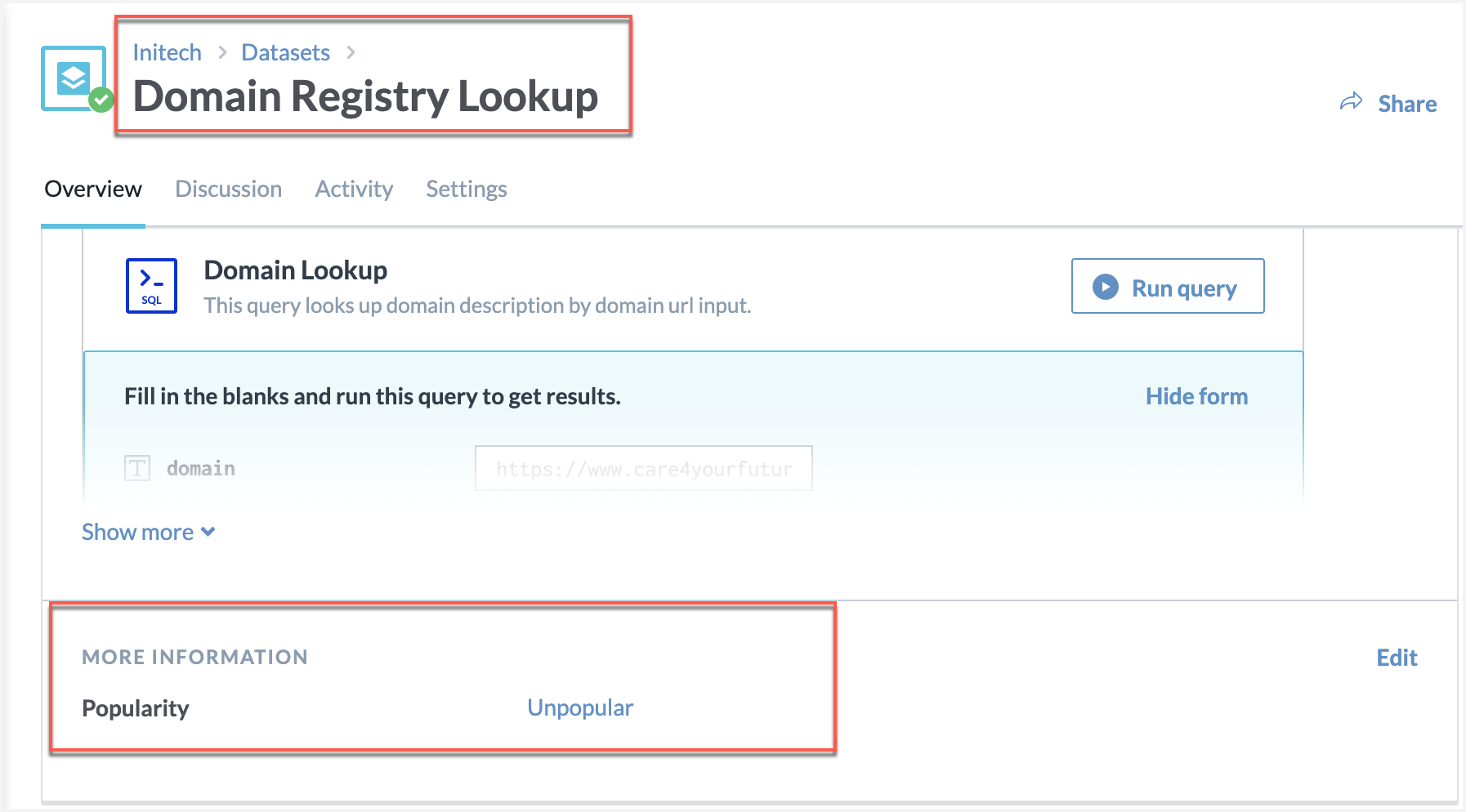
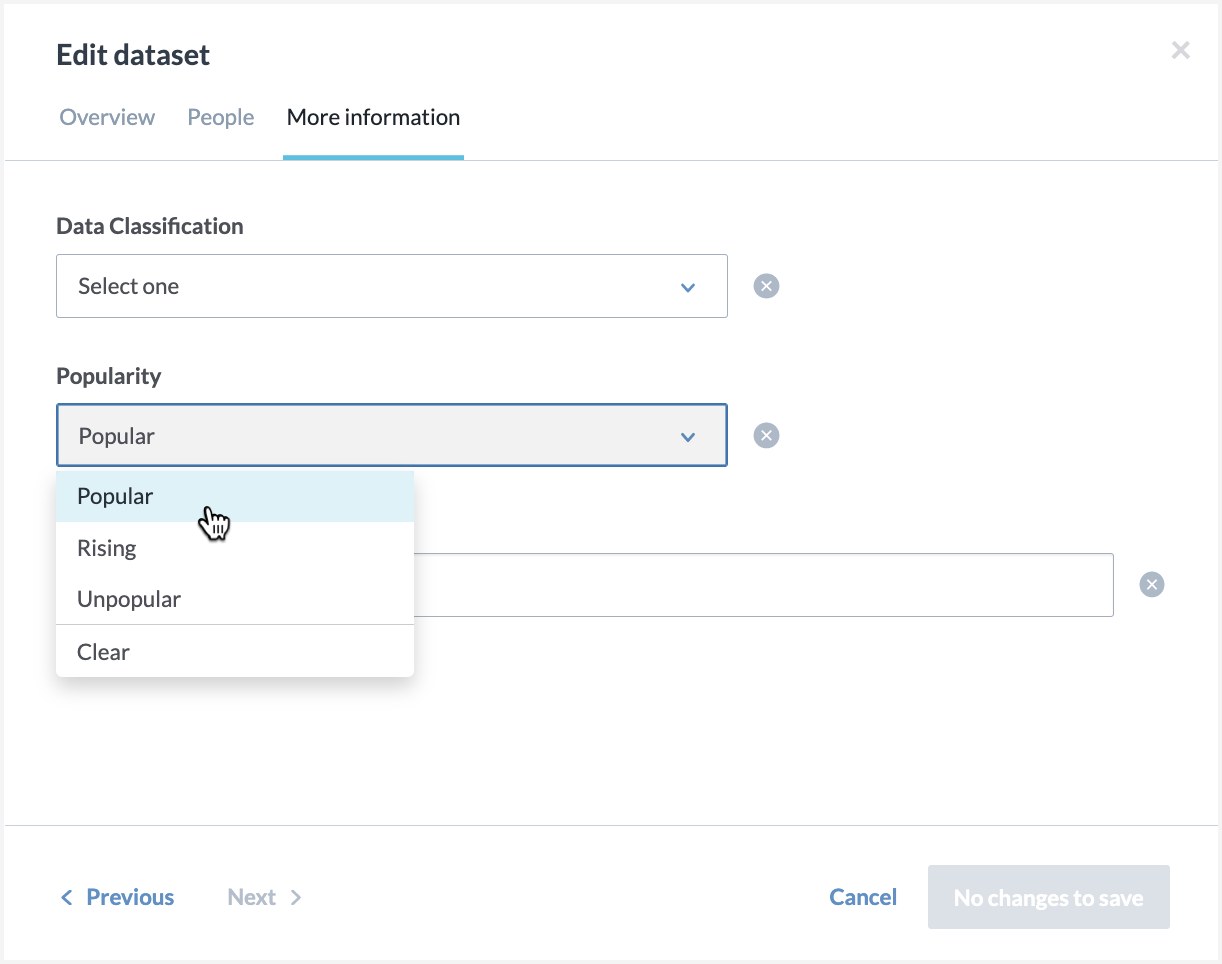
Click the Edit button in the More information section, to edit the popularity!
On various product pages such as Search results Resources, use the Popularity filter to narrow down lists by popularity scores attached to the resources.