Overview of the custom_types.ttl file
In this article we introduce the composition of the custom_types.ttl file and the vocabulary used to describe it. Then we go on to discuss the format of the file and indicate what should not be changed, what must be changed, what can be changed, and how. If you do not currently have a ddw-ontologies dataset with a custom_types.ttl file in it, you can request one from support. Your custom types file can be called anything you'd like and stored in any of your organization's datasets that you would like.
Note
Though you can name your .ttl file anything you would like and put it in any dataset you would like, we recommend using ddw-ontologies as the name for your dataset and storing the .ttl file there.
A .ttl file is divided into two parts: the prologue at the top followed by the body. The prologue is where short forms of the prefixes for the iris (addresses or references for resources) are defined. These short forms are used in the body so that you don't have to type out the long form of the prefix each time you describe a resource.
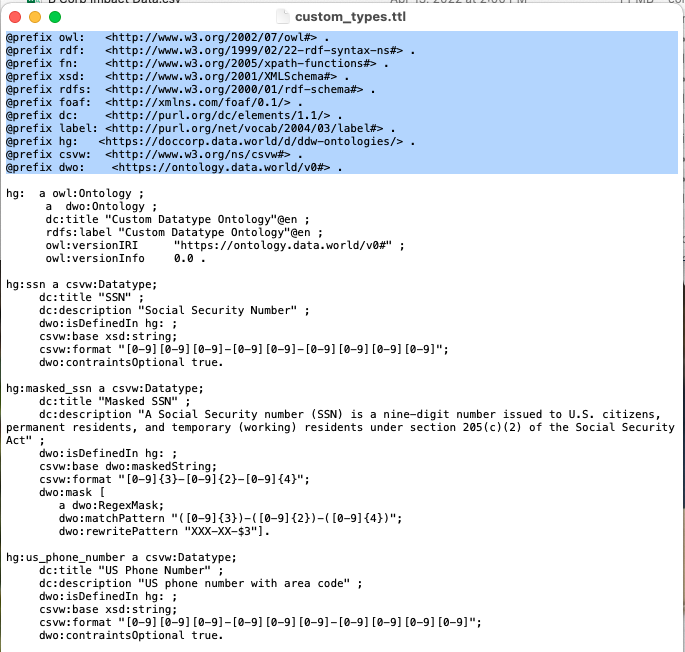
Most of the prefixes in the custom_types.ttl prologue refer to standard ontologies and should be left alone. The one exception is the hg prefix which should be changed to reference your organization's ddw-ontologies dataset:
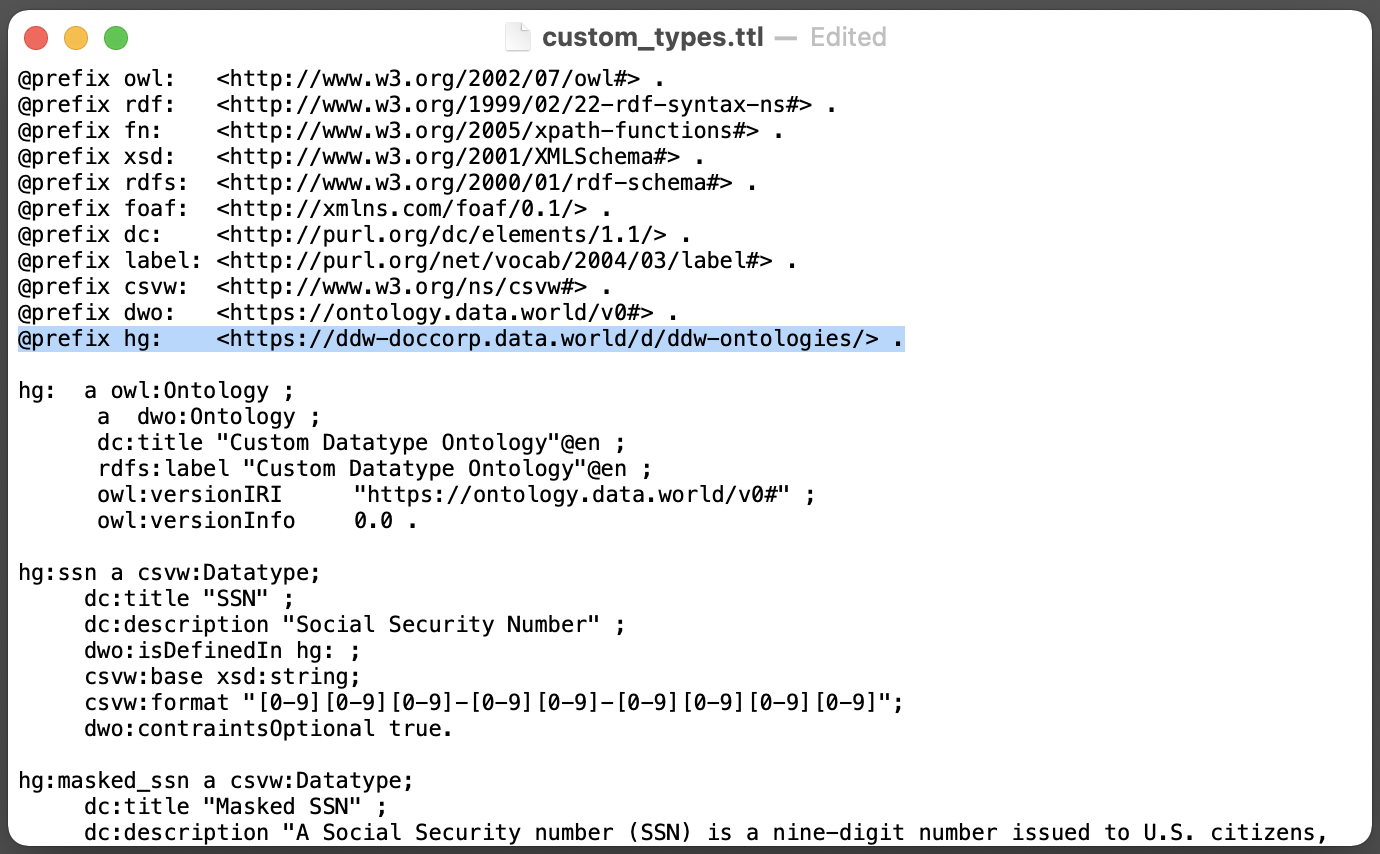
Important
Because you are defining the prefixes in the prologue, you can rename them, for example changing hg to something else. However, if you do, you will also need to change all the references to that prefix elsewhere in the file:
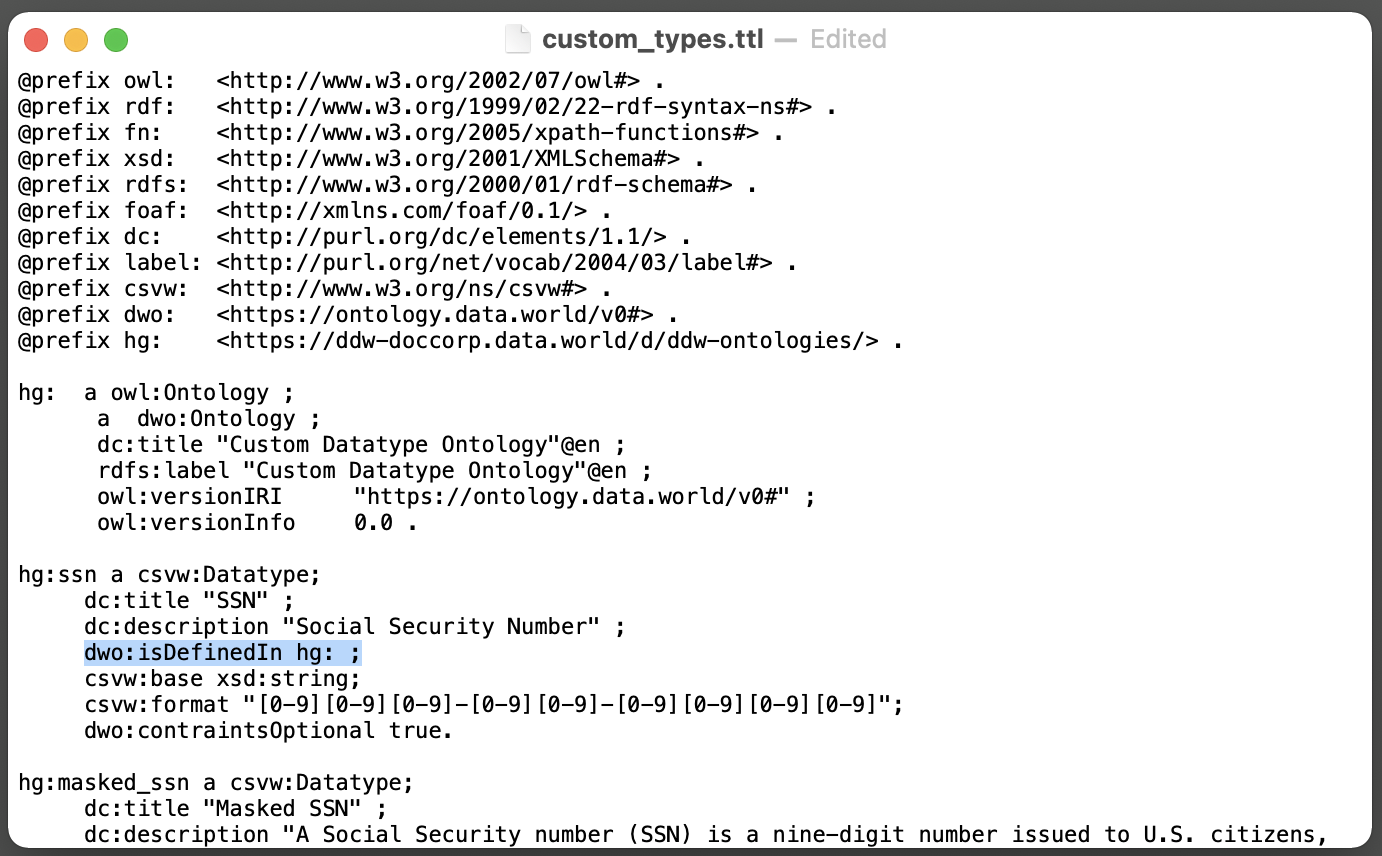
The body is made up of information about resources. This information is in a form called a triple . A triple has a subject-predicate-object format, which is a standardized way of describing something. For example, one triple might be, "Data science is fun for everyone" "Data science" is the subject, "is fun for" is the predicate, and "everyone" is the object.
Triples for the same resource can be grouped together in a stanza. The benefit of grouping the triples for a resource is that
The subject in the triple does not have to be rewritten for every triple in the stanza
You can see all the triples for the same resource at once.
The first stanza of the body of the data.world custom_types.ttl file describes the data.world ontology. It needs to remain unchanged for custom types to run.
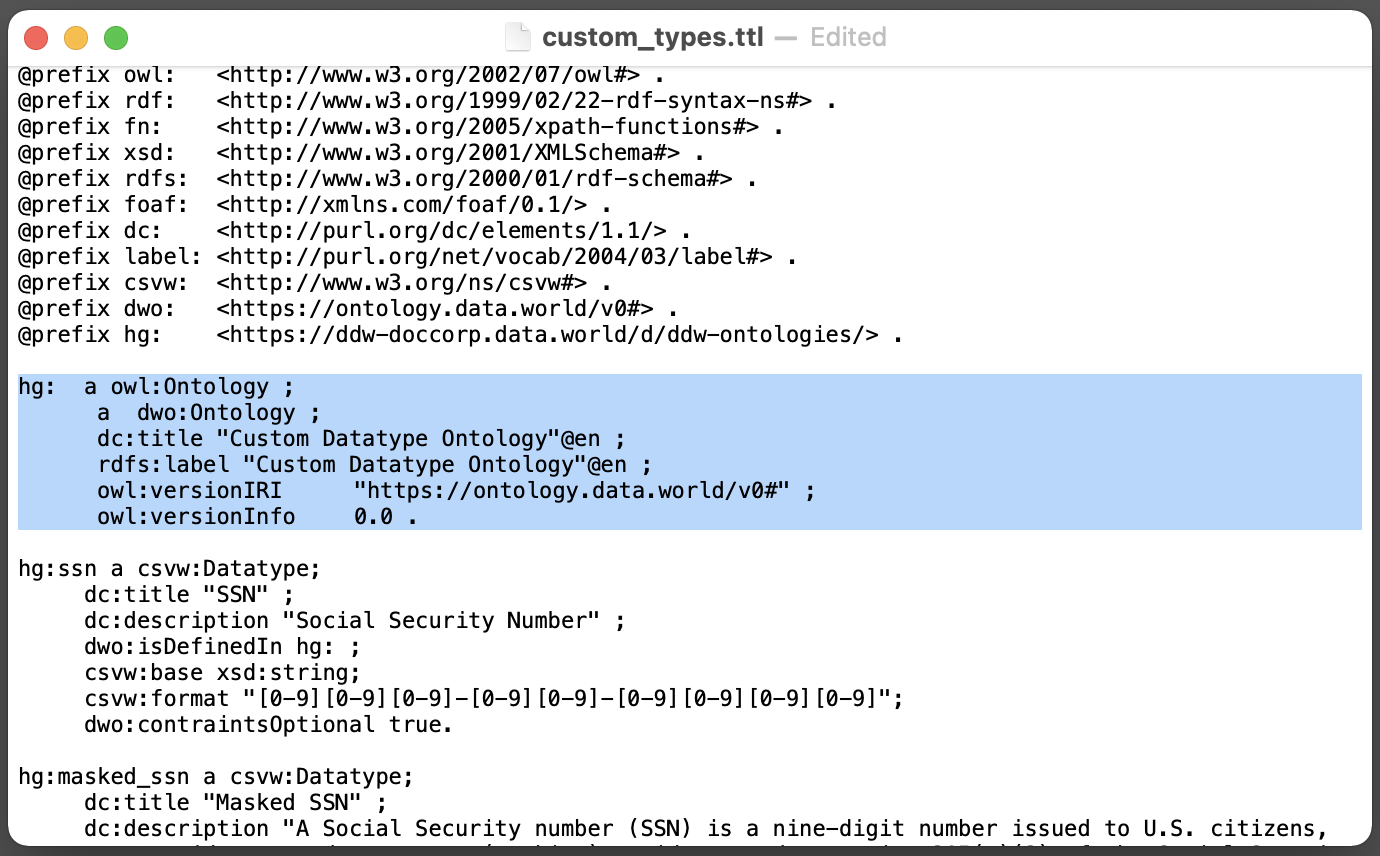
The second stanza contains an example of a custom data type defined by data.world:
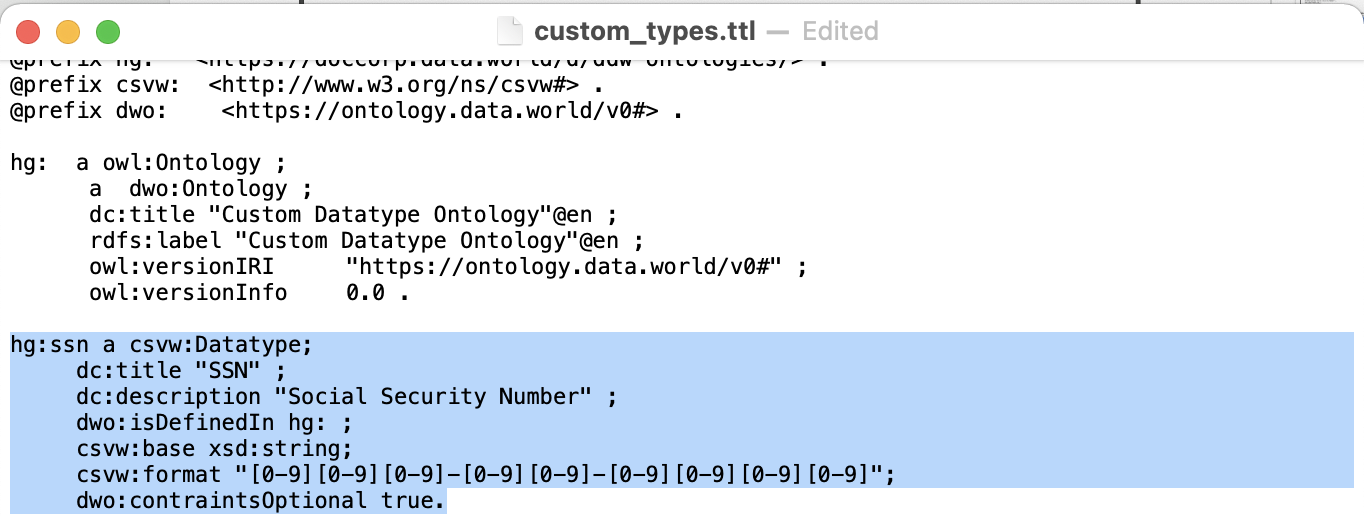
The following table shows the triples in the stanza separated into subjects, predicates and objects. The elements that can be modified are shown in bold. Notice that only the subject and the objects that are text strings can be changed, and the prefix for the subject should only be changed if it was changed in the prologue:
Line | Subject | Predicate | Object |
|---|---|---|---|
line 1 | hg:ssn | a | csvw:Datatype |
line 2 | dc:title | "SSN" | |
line 3 | dc:description | "Social Security Number" | |
line 4 | dwo:isDefinedIn | hg: | |
line 5 | csvw:base | xsd:string | |
line 5 | csvw:format | "[0-9][0-9][0-9]-[0-9][0-9]-[0-9][0-9][0-9][0-9]" | |
line 7 | dwo:contraintsOptional | true |
The third stanza shows a masked custom data type:
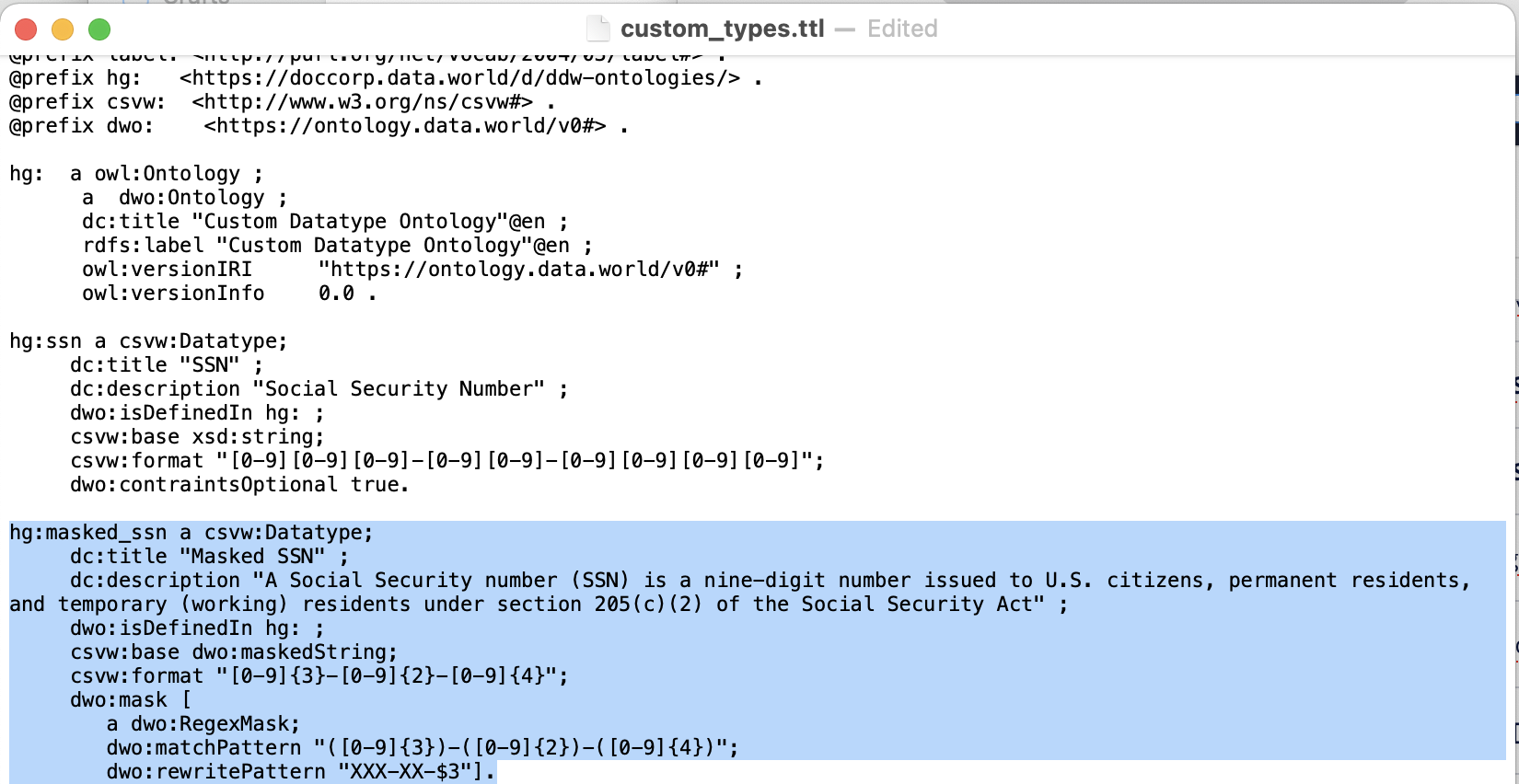
As in the previous example, the elements that can be modified are in bold:
Line | Subject | Predicate | Object |
|---|---|---|---|
line1 | hg:masked_ssn | a | csvw:Datatype |
line 2 | dc:title | "Masked SSN" | |
line 3 | dc:description | "A Social Security number (SSN) is a ..." | |
line 4 | dwo:isDefinedIn | hg: | |
line 5 | csvw:base | dwo:maskedString | |
line 6 | csvw:format | "[0-9]{3}-[0-9]{2}-[0-9]{4}" | |
line 7 | dwo:mask | [ a dwo:RegexMask; dwo:matchPattern "([0-9]{3})-([0-9]{2})-([0-9]{4})"; dwo:rewritePattern "XXX-XX-$3"] |
The example is complicated a bit by additional predicates and objects nested in the object of the triple on the seventh line. However, as before, only the subject and objects that are text strings can be modified. Everything else should stay the same. For more information about Regex and how to use it, visit the Oracle Java documentation.