Named graphs
To get more control over just what data is used in a query, and to enable different data to be used in different parts of a query, SPARQL has the concept of named graphs. These are graphs that are named using an IRI, and can be specified using FROM and FROM NAMED clauses, and GRAPH patterns in a SPARQL query. data.world allows you to specify named graphs from various data.world resources including:
Datasets
Project and project-unions
Files
Dataset graphs
Each dataset in data.world can be referenced as a named graph. It has an IRI in the form https://<agent_id>.linked.data.world/d/<dataset_id>. The dataset graph allows data from one dataset to be accessed from a different dataset, or data from multiple datasets to be combined together.
Example - Named graph
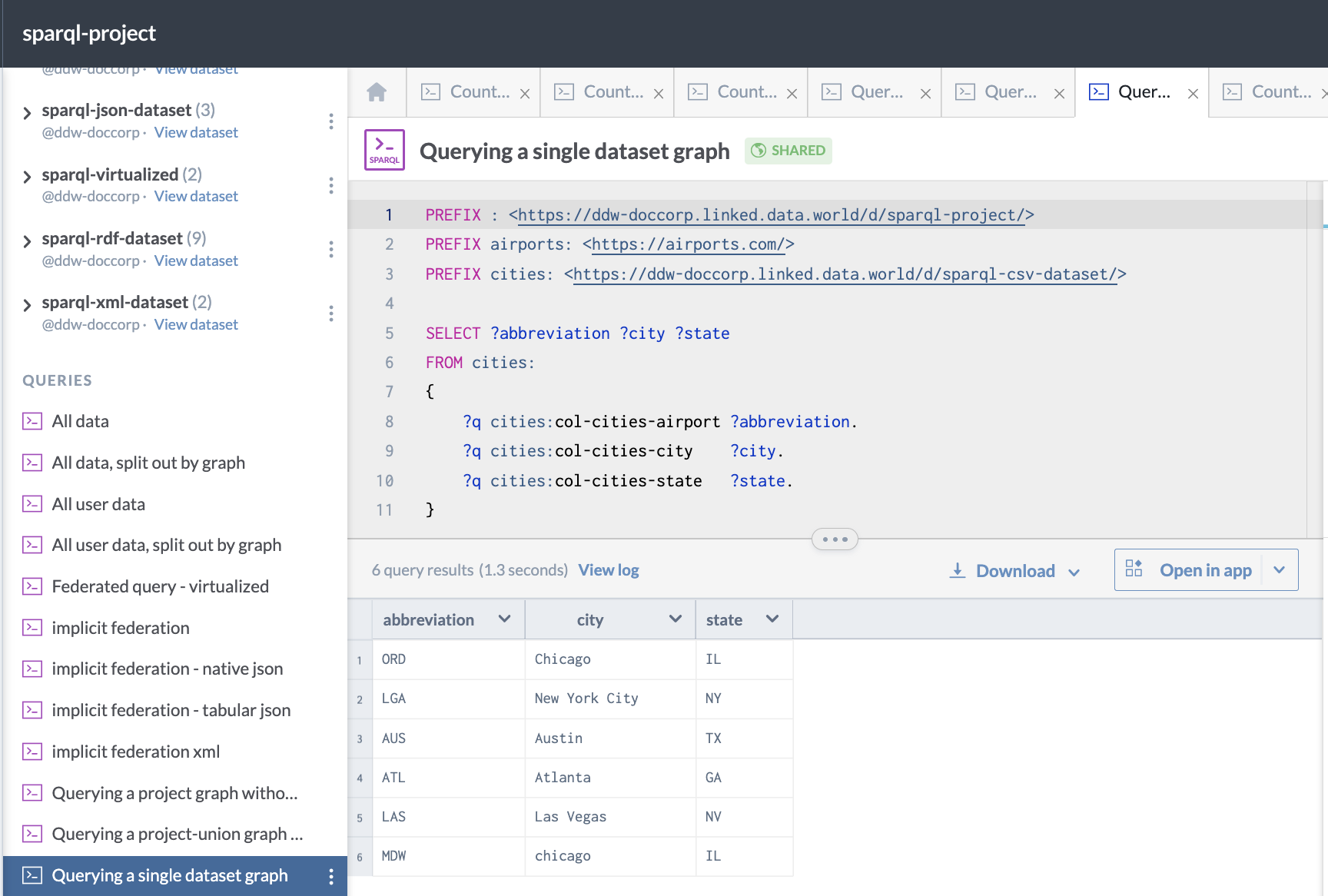
Here is an example of a query against a single dataset graph:
PREFIX : <https://ddw-doccorp.linked.data.world/d/sparql-project/>
PREFIX airports: <https://airports.com/>
PREFIX cities: <https://ddw-doccorp.linked.data.world/d/sparql-csv-dataset/>
SELECT ?abbreviation ?city ?state
FROM cities:
{
?q cities:col-cities-airport ?abbreviation.
?q cities:col-cities-city ?city.
?q cities:col-cities-state ?state.
}This is what it looks like on data.world:
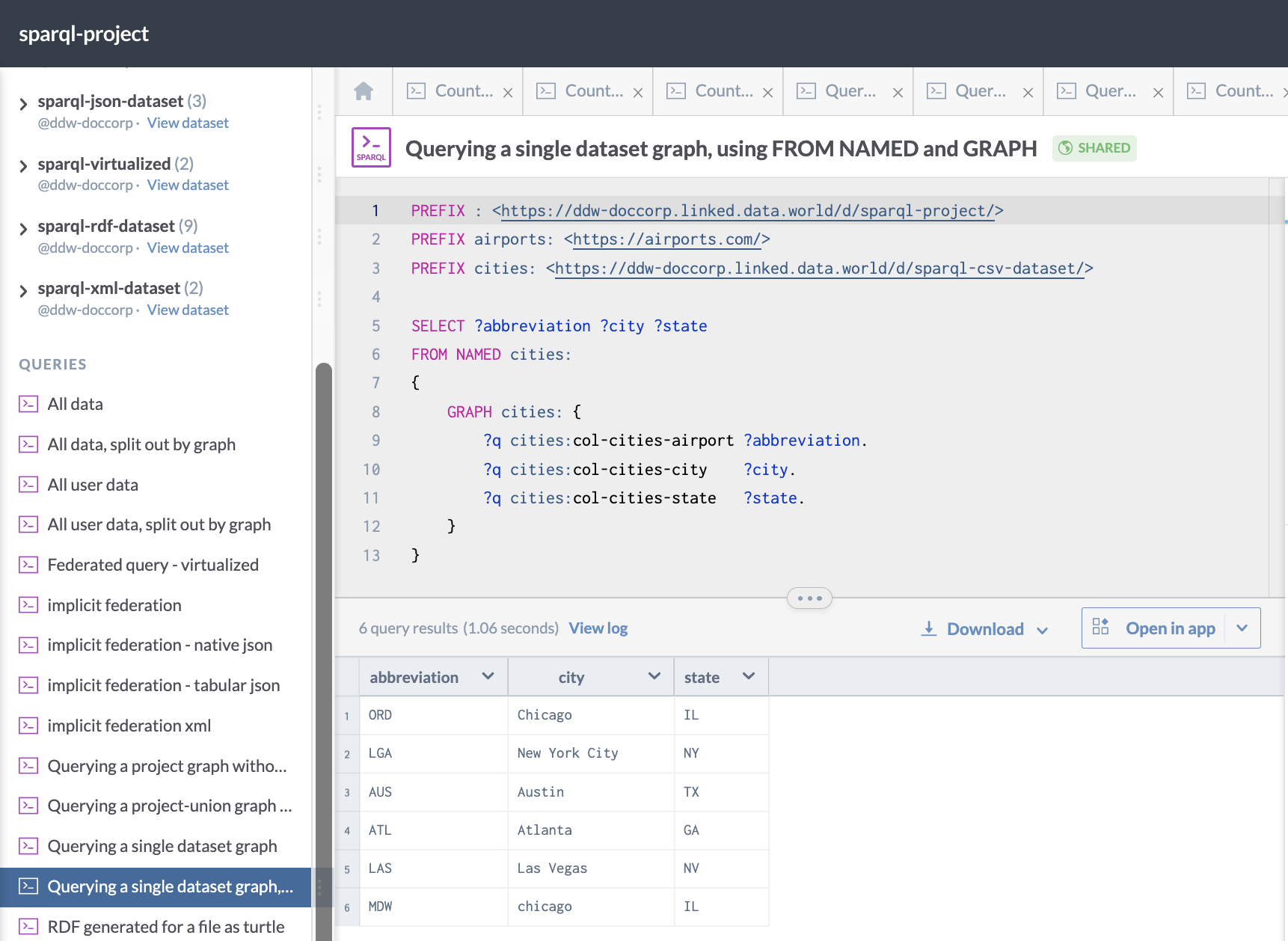
Here is an example of a query against a single dataset using FROM NAMED and GRAPH:
PREFIX : <https://ddw-doccorp.linked.data.world/d/sparql-project/>
PREFIX airports: <https://airports.com/>
PREFIX cities: <https://ddw-doccorp.linked.data.world/d/sparql-csv-dataset/>
SELECT ?abbreviation ?city ?state
FROM NAMED cities:
{
GRAPH cities: {
?q cities:col-cities-airport ?abbreviation.
?q cities:col-cities-city ?city.
?q cities:col-cities-state ?state.
}
}This is what it looks like when run on data.world:
Project and project-union graphs
Each project in data.world can also be referenced as a named graph. It has an IRI in the form https://<agent_id>.linked.data.world/d/<project_id>.
Note
Note that the project graph represents only the data present in the project, not in any datasets linked to the project.
The named graph which represents the data in a project merged with that in all of the datasets linked to that project is called a project-union graph and has an IRI in the form https://<agent_id>.linked.data.world/d/<project_id>/project-union.
Example - Project and project union
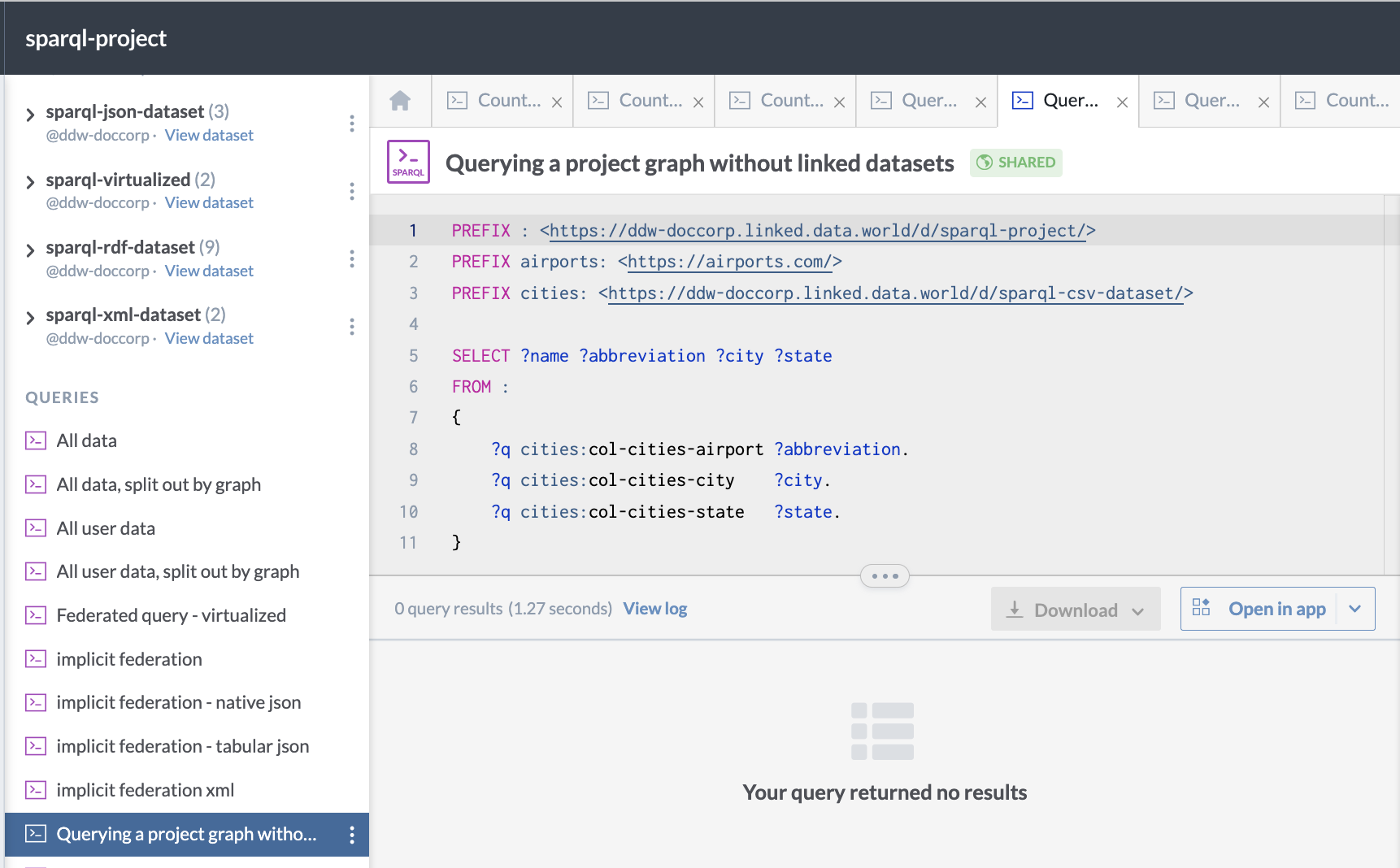
Here is an example of a query against all the files in a project (NOT including the data in the linked datasets):
PREFIX : <https://ddw-doccorp.linked.data.world/d/sparql-project/>
PREFIX airports: <https://airports.com/>
PREFIX cities: <https://ddw-doccorp.linked.data.world/d/sparql-csv-dataset/>
SELECT ?name ?abbreviation ?city ?state
FROM :
{ ?q cities:col-cities-airport ?abbreviation.
?q cities:col-cities-city ?city.
?q cities:col-cities-state ?state.
}This is what the query looks like when run on data.world:
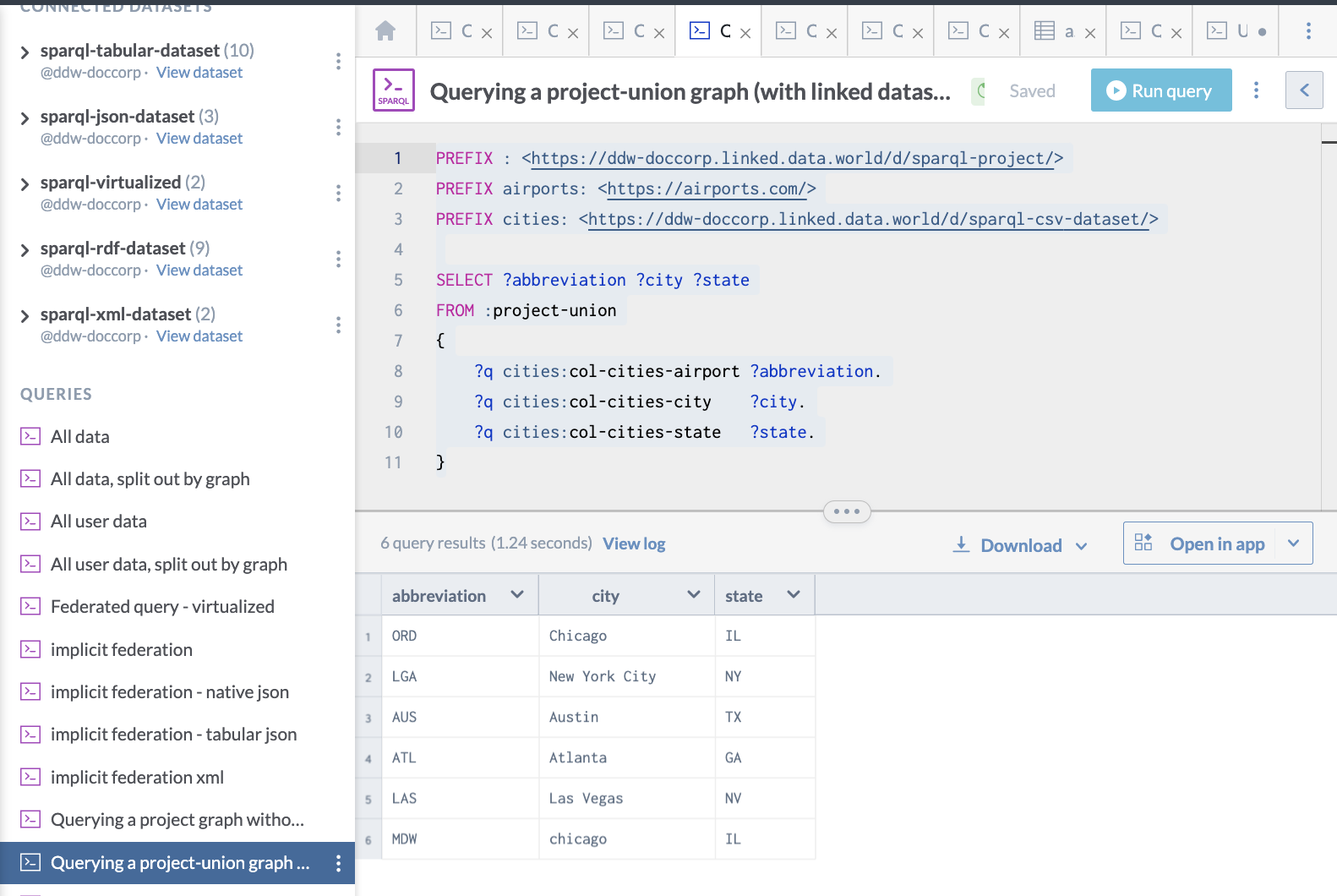
Here is an example of querying a project-union graph (with linked datasets):
PREFIX : <https://ddw-doccorp.linked.data.world/d/sparql-project/>
PREFIX airports: <https://airports.com/>
PREFIX cities: <https://ddw-doccorp.linked.data.world/d/sparql-csv-dataset/>
SELECT ?abbreviation ?city ?state
FROM :project-union
{
?q cities:col-cities-airport ?abbreviation.
?q cities:col-cities-city ?city.
?q cities:col-cities-state ?state.
}And this is what it looks like on data.world:
File graphs
For even more precise control over the data used in a query, data.world supports querying the data from one individual RDF or tabular file in a dataset or project. The IRI for the file is in the form http://<agent_id>.linked.data.world/d/<dataset_id>/file/<filename>.
To simultaneously query multiple files, use :files. The :files graph strictly includes the triples uploaded as RDF files - there are no axioms, ingest metadata, or tabular data, it is simply the data you uploaded.
Example for single file
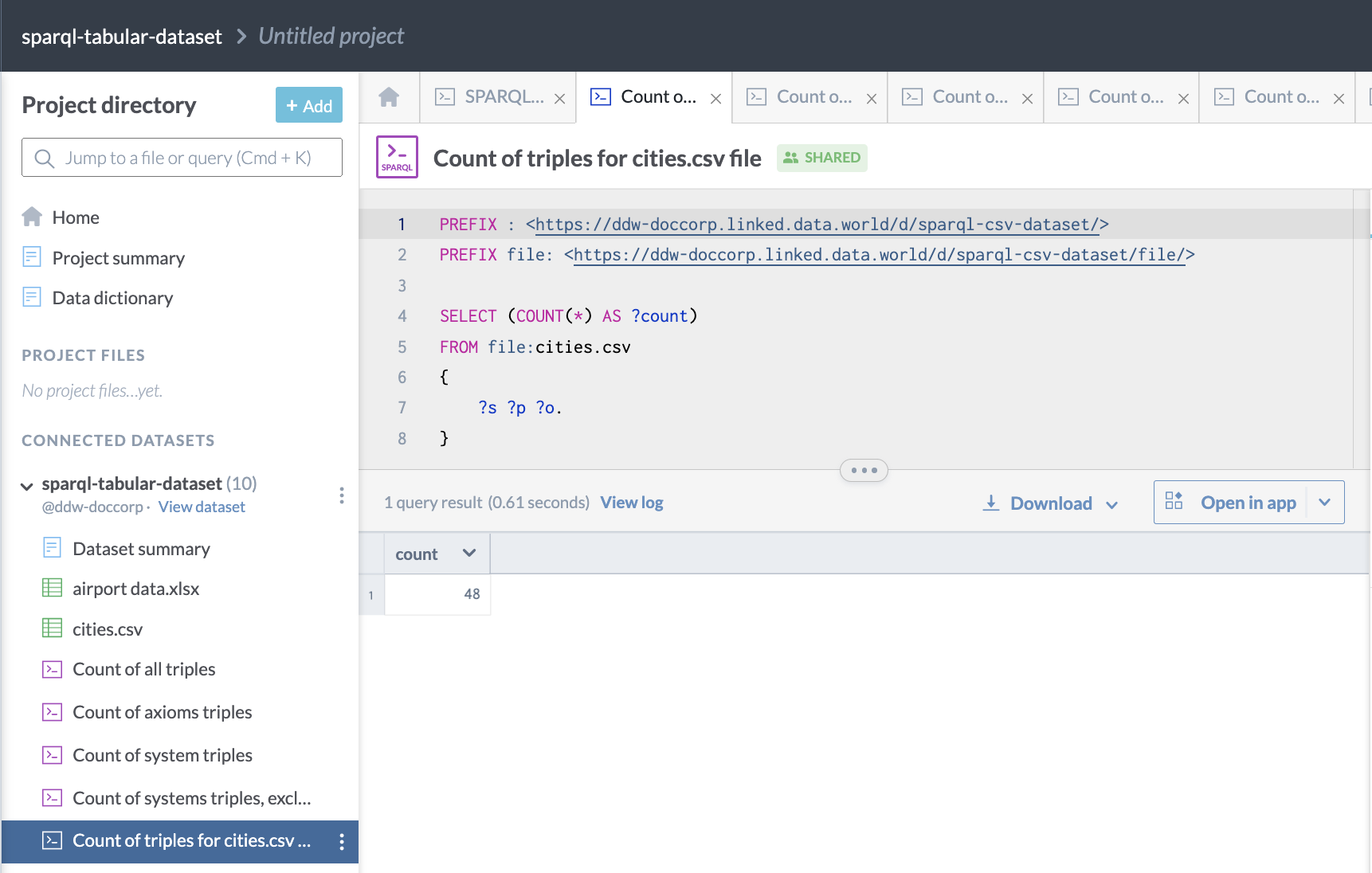
Here is an example of a query run against a single file:
PREFIX : <https://ddw-doccorp.linked.data.world/d/sparql-csv-dataset/>
PREFIX file: <https://ddw-doccorp.linked.data.world/d/sparql-csv-dataset/file/>
SELECT (COUNT(*) AS ?count)
FROM file:cities.csv
{
?s ?p ?o.
}This is what the query looks like when run on data.world:
Example for multiple files
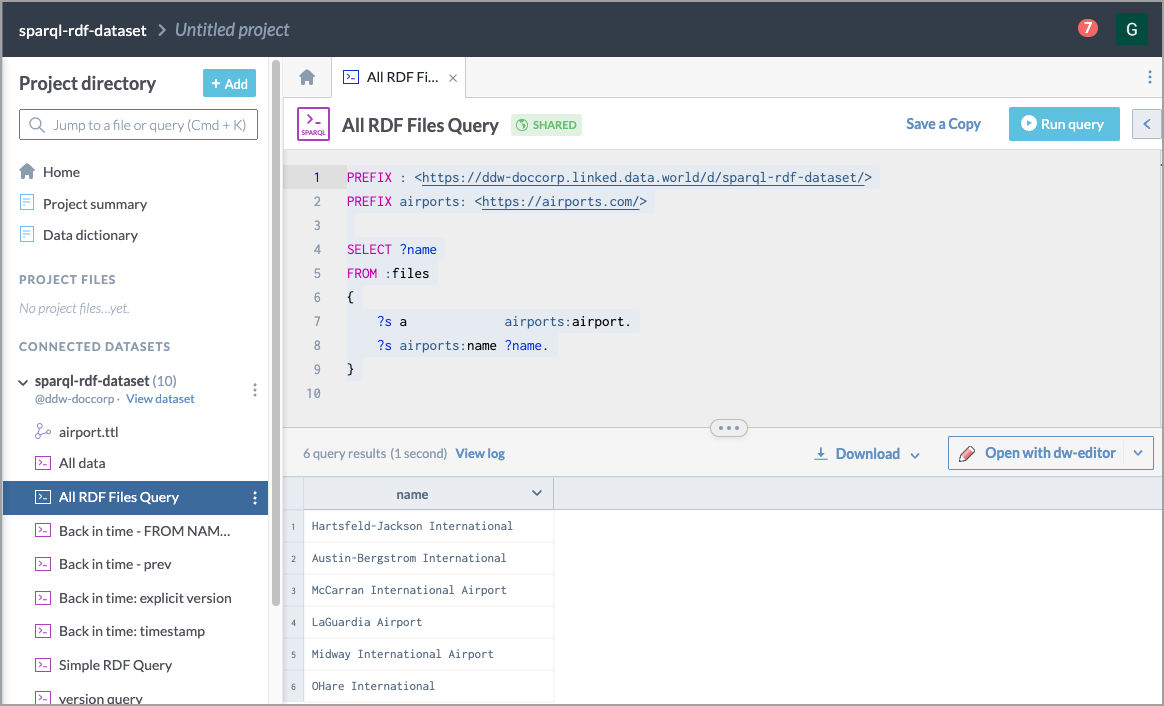
Here is an example of a query run against multiple files:
PREFIX : <https://ddw-doccorp.linked.data.world/d/sparql-rdf-dataset/>
PREFIX airports: <https://airports.com/>
SELECT ?name
FROM :files
{
?s a airports:airport.
?s airports:name ?name.
}This is what the query looks like when run on data.world:
System, system-meta, and axiom graphs
As mentioned previously, data.world enhances your data with a variety of metadata triples from standard data description ontologies. This includes adding the axiom triples which define those ontologies to your dataset, making your data even more self-describing, and creating a very rich environment for data validation and publication. Sometimes, you may wish to reference only those triples that data.world has added. For that purpose, named graphs have been made available that consist of useful subsets of those triples. These graphs are called:
:system - The :system graph for a dataset consists of all the metadata and axioms with which we have enhanced your data.
:system-meta - The :system-meta graph contains the metadata generated for your dataset.
:axiom - The :axioms graph consists of just the axioms.
Examples
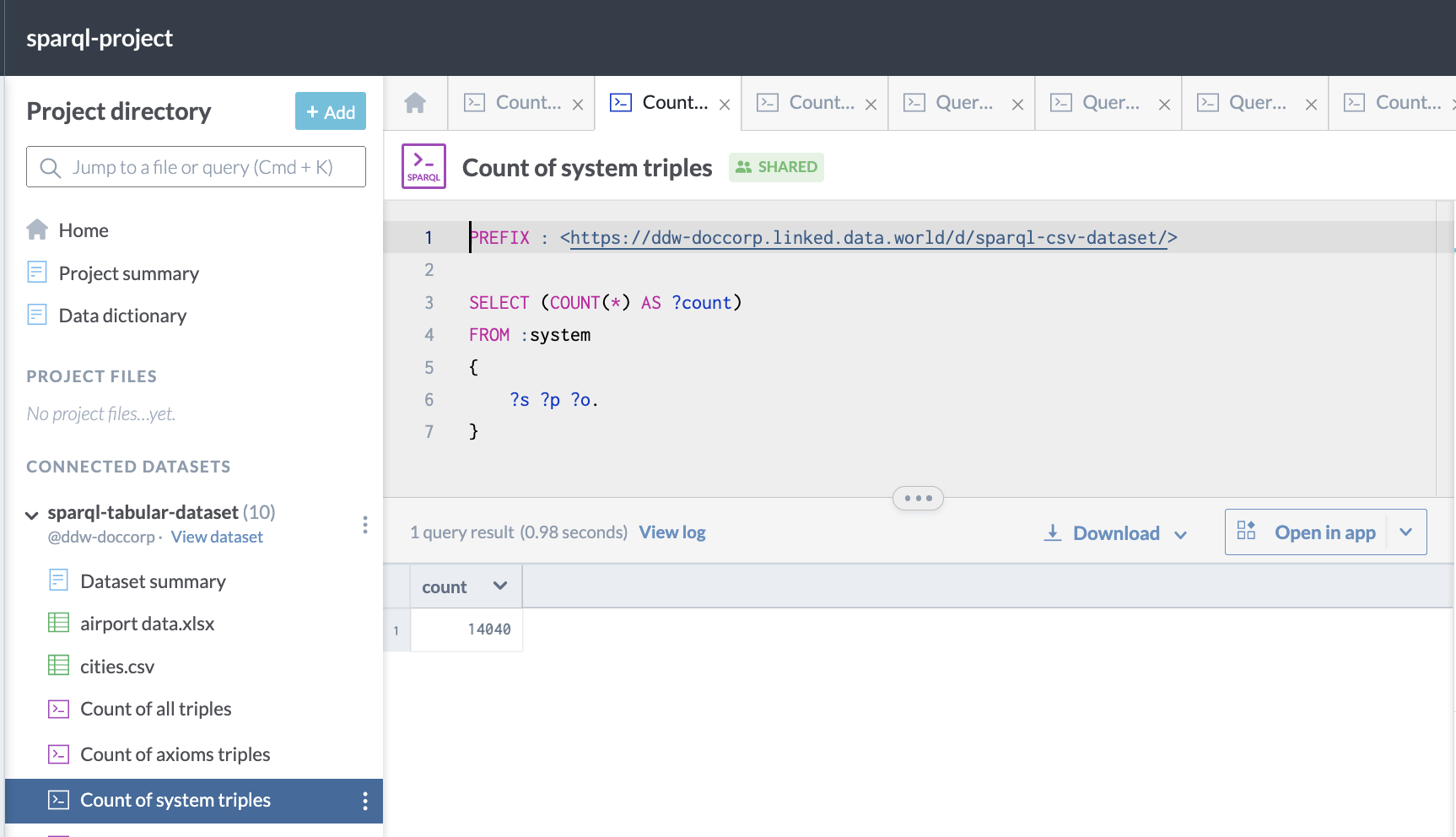
Here is an example of a query to count of the triples in the system graph of a dataset, which contains all of the metadata and axioms added by data.world to the dataset.:
PREFIX : <https://ddw-doccorp.linked.data.world/d/sparql-csv-dataset/>
SELECT (COUNT(*) AS ?count)
FROM :system
{
?s ?p ?o.
}This is what it looks like when run on data.world:
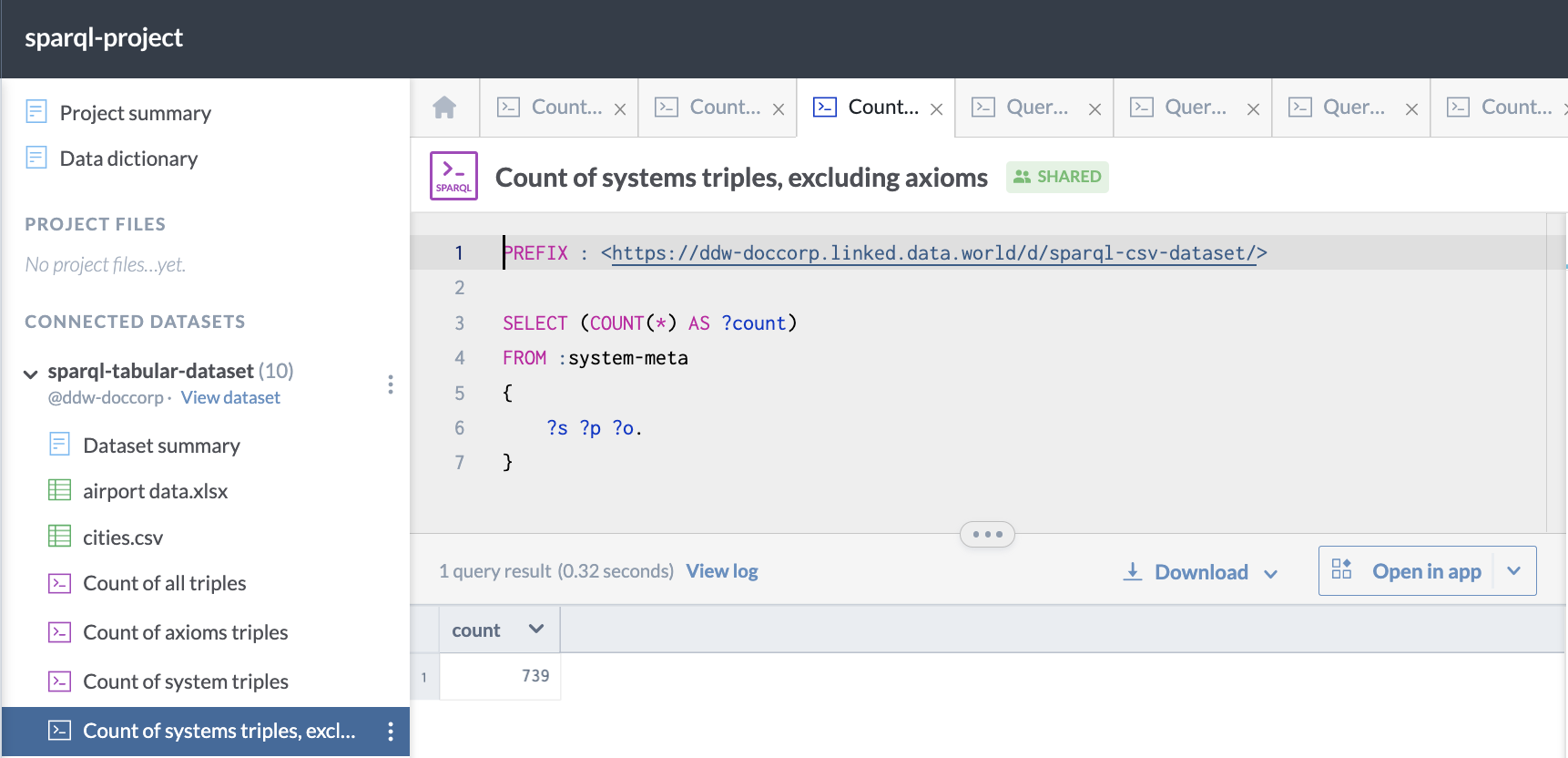
Here is an example of a query to count the triples in the system-meta graph of a dataset, which contains all of the metadata added by data.world to the dataset, excluding axioms:
PREFIX : <https://ddw-doccorp.linked.data.world/d/sparql-csv-dataset/>
SELECT (COUNT(*) AS ?count)
FROM :system-meta
{
?s ?p ?o.
}This is what the query looks like when run on data.world:
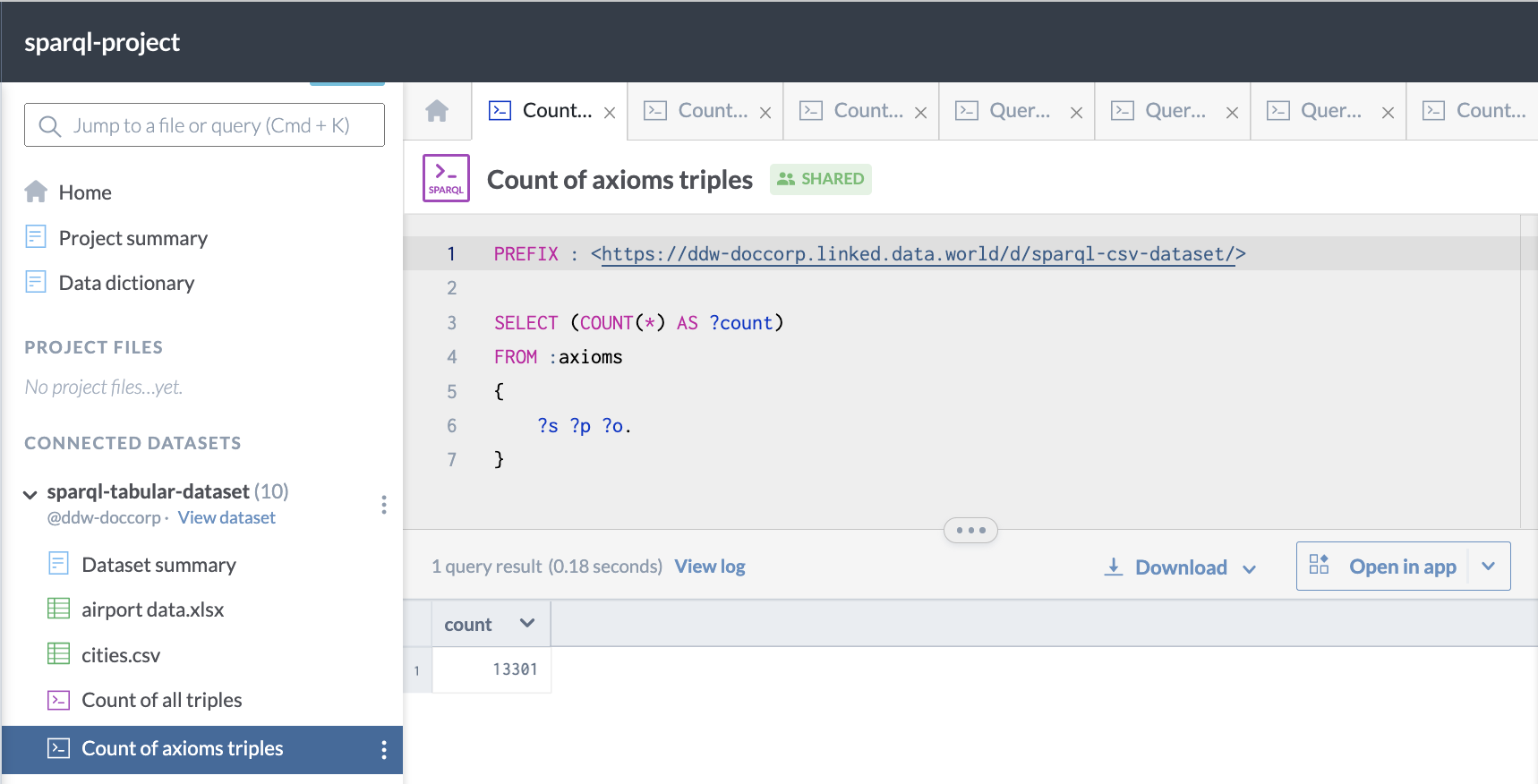
Finally, here is an example of a query which counts all of the triples in the axioms graph of a dataset, created by adding ontology axioms to the database:
PREFIX : <https://ddw-doccorp.linked.data.world/d/sparql-csv-dataset/>
SELECT (COUNT(*) AS ?count)
FROM :axioms
{
?s ?p ?o.
}This is what it looks like when run on data.world: