Apply column count tag to tables
Goal of this Eureka automation
With this automation we will tag tables based on the numbers of columns in them.
Note
Before you begin -
Ensure your organization has cataloged database tables and they appear in your catalog.
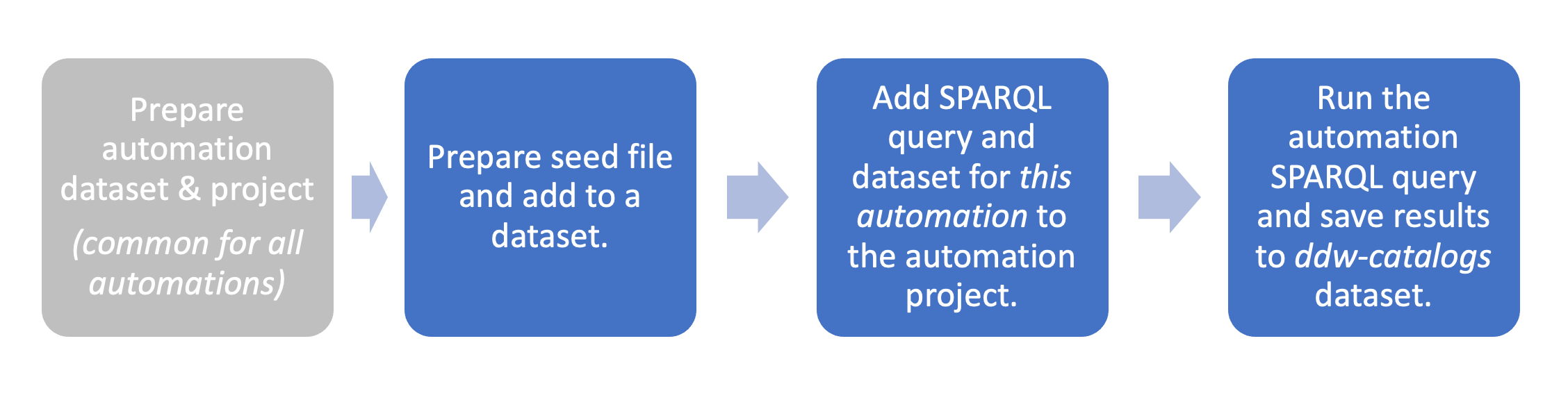
STEP 1: Prepare a seed file and add to a dataset
First we will prepare the seed file:
Create a seed file that assigns a tag based on a minimum and maximum columns in a table. In this example, if tables have between 0 and 10 columns, assign the tag low. If tables have between 11 and 50 columns, then tag medium, and so on. You can add/edit this seed file as you wish.
column-count-tag.seed.csv
min,max,tag 0,10,low 11,50,medium 51,1000,high
Now, we will create a dataset and add the seed file to it:
Create a dataset and name it ddw-eureka-column-count-tag.
Upload the seed file to the ddw-eureka-column-count-tag dataset.
STEP 2: Add dataset and SPARQL query to the Eureka Automations Project
Note
These tasks are done in the ddw-eureka-automations project created here.
Go to the project ddw-eureka-automations.
On the Project details page, click the Launch Workspace button.
Link the dataset ddw-eureka-column-count-tag created in STEP 1 to the project by clicking Add > Dataset > .
Create a new SPARQL Query by clicking +Add > SPARQL Query.
Add the following query. Replace yourorgname with the name of your organization.
PREFIX : <https://yourorgname.linked.data.world/d/ddw-eureka-column-count-tag/> PREFIX dwec: <https://dwec.data.world/v0/> PREFIX dct: <http://purl.org/dc/terms/> CONSTRUCT{ ?table dwec:textTag ?ColumnTag } WHERE { { select (count(*) as ?total) ?table where { ?table a dwec:DatabaseTable. ?column a dwec:DatabaseColumn. ?column dct:isPartOf ?table. } group by ?table } ?x a :tbl-column_count_tag_seed; :col-column_count_tag_seed-min ?min; :col-column_count_tag_seed-max ?max; :col-column_count_tag_seed-tag ?tag; . filter(?min <= ?total && ?total <= ?max) BIND(IF(?min <= ?total && ?total <= ?max, ?tag, "Unknown") as ?ColumnTag) }Save the query with:
Name ea-column-count-tag.result.ttl.rq
Description Depending on the number of columns a table has, tag with High, Medium or Low tag, based on the seed file.
STEP 3: Run your Eureka automation
Execute the SPARQL query added in Step 2.
From the Results page, select Download the results > Save to dataset.
Set file name. The query name will automatically appear. Just delete the suffix >.rq
Save the file to the ddw-catalogs dataset of your organization. You must set the file to auto-sync every hour.
Note
This file goes in the ddw-catalogs dataset.
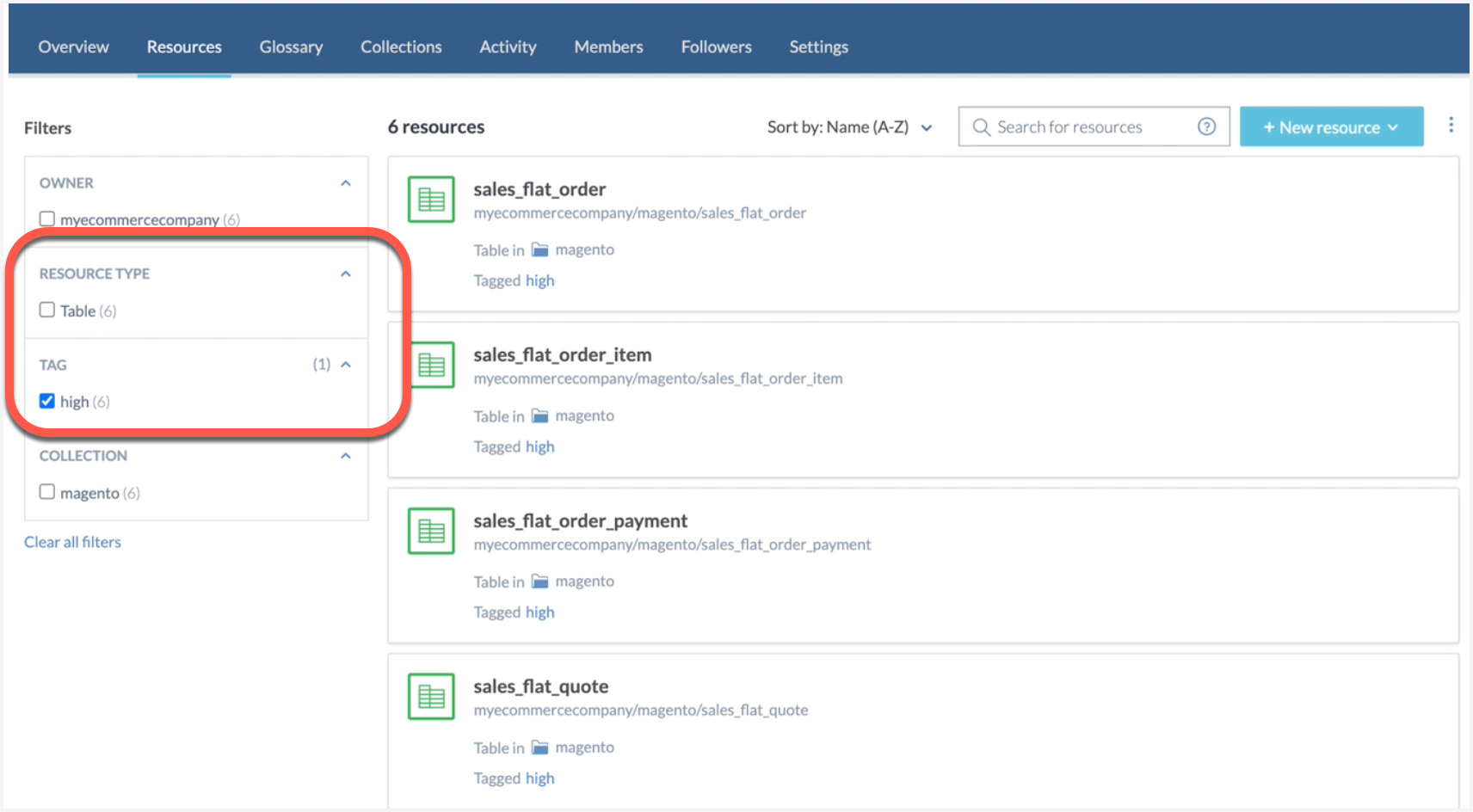
View the Results! 🎉
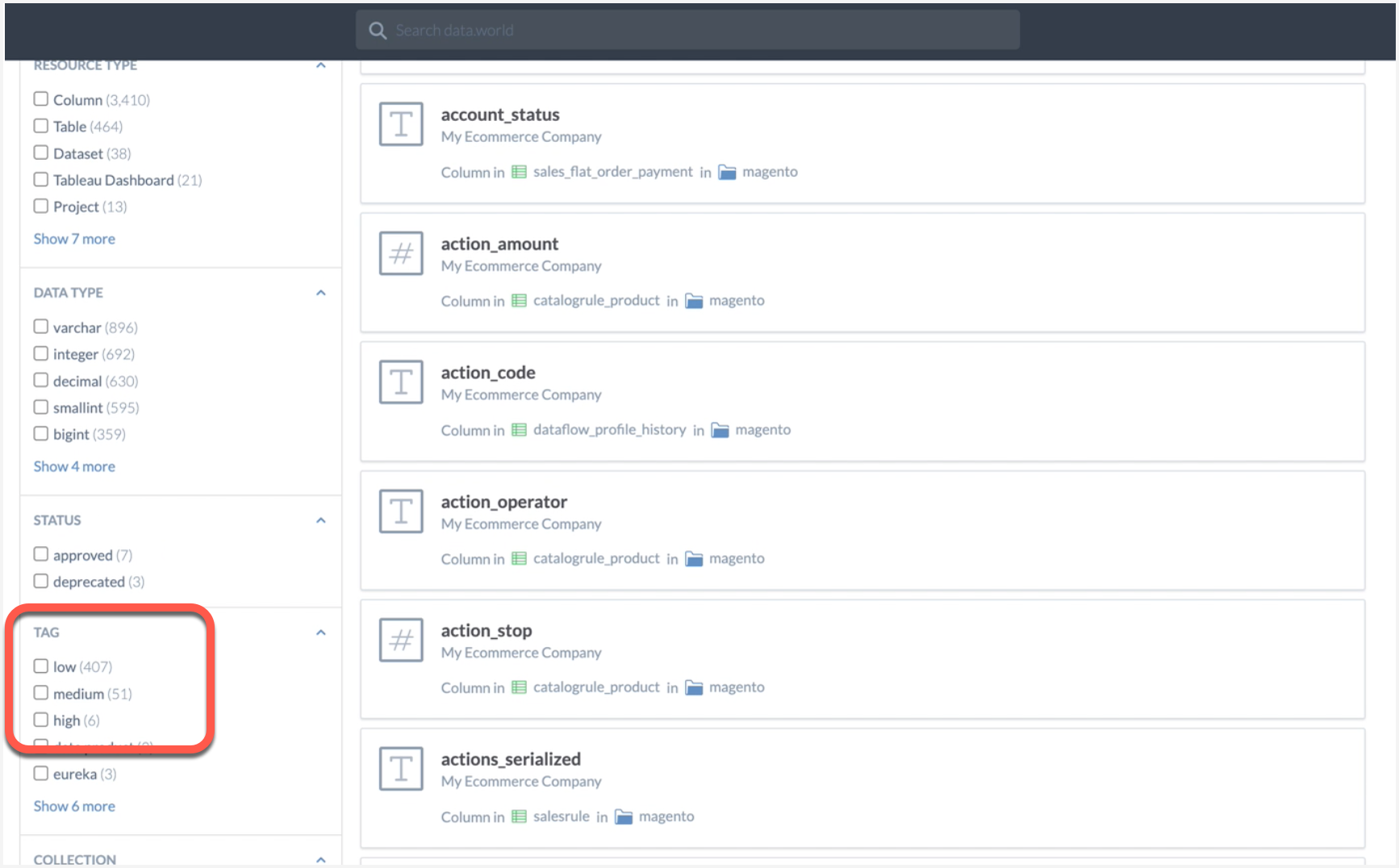
Go to your organization profile page and from the Resources tab, view the tags available for filtering.
Note
🎉 Congrats!Your tables are automatically tagged based on numbers of columns in them. You can use these tag to narrow down your lists.