About datasets
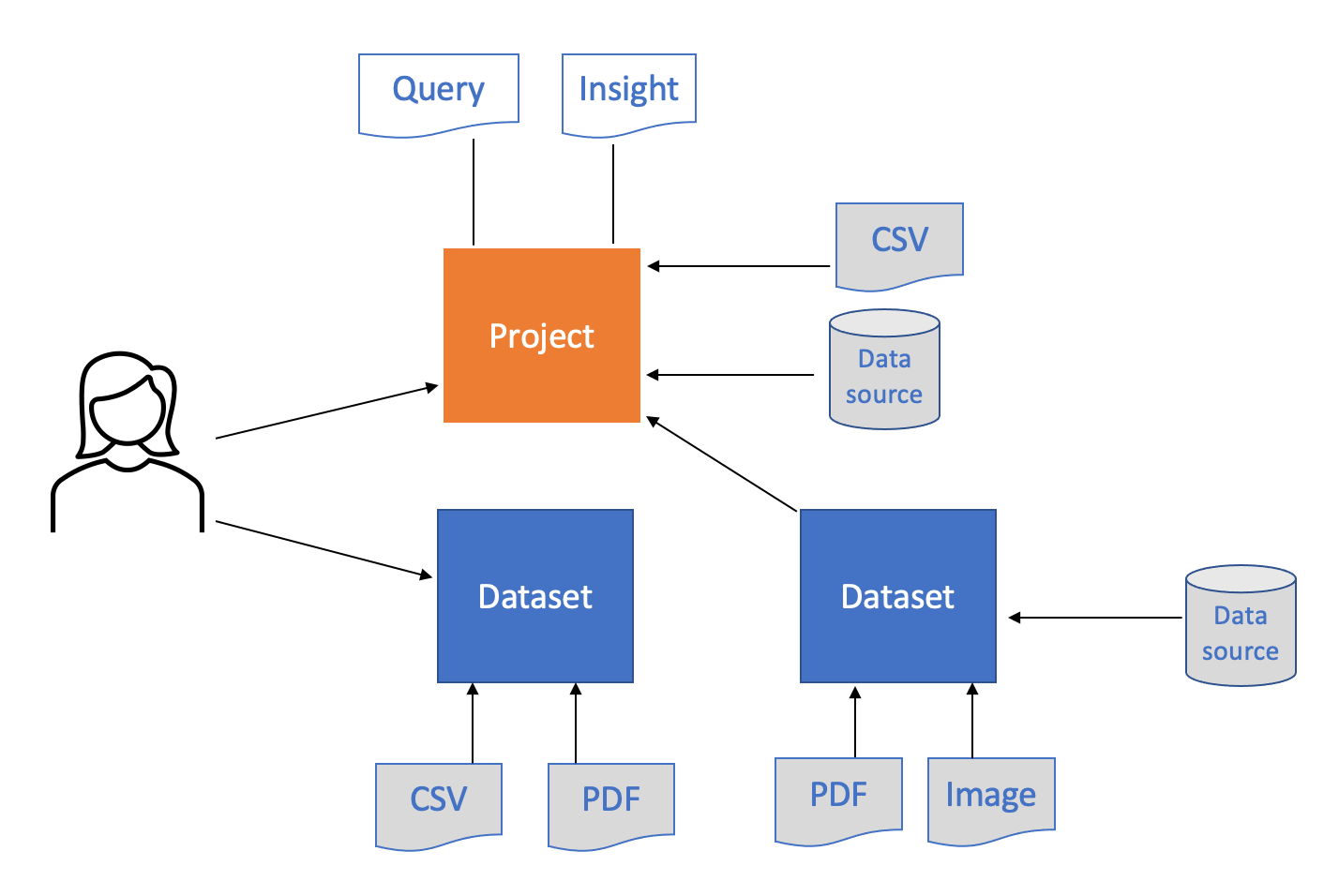
A dataset serves as a fundamental repository for storing data files along with their metadata, documentation, scripts, and any other resources that need to accompany the data. Datasets house all data to be stored, documented, and later shared and used in projects, acting as the building blocks for those projects. They contain data and metadata related to a specific topic, and the files and tabular data within a dataset are meant to be used, queried, and analyzed across one or more projects. Designed as reusable resources, datasets can be integrated with other datasets in projects or stand alone as a single source for querying and analysis.
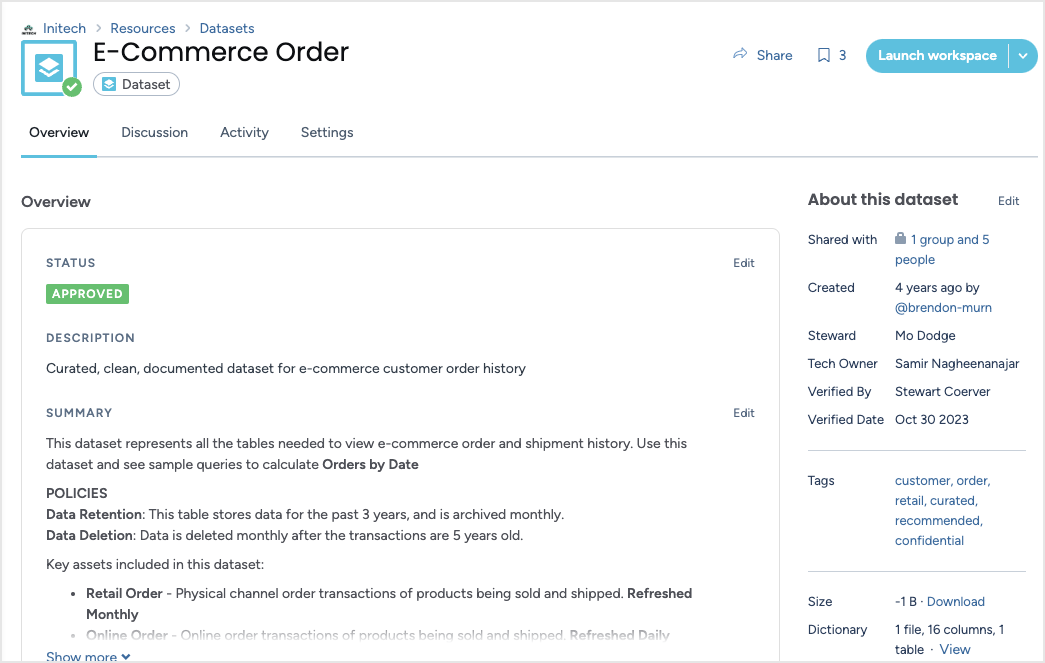
Datasets can be owned by either an individual or an organization, providing an additional layer of access permissions to project data. Since permissions are set at both the dataset and project levels, an individual might create a publicly available project, but if it includes datasets owned by an organization, those datasets—and any project queries involving them—remain visible only to organization members.
Because datasets are linked to projects, any updates to data or metadata in the dataset automatically reflect in the linked project. This linking approach ensures everything remains current and consistent across your organization, eliminating the need for data duplication within projects.