About the InfluxDB collector
Use this collector to discover InfluxDB buckets and columns across your enterprise. Dive deep into metadata about buckets, tasks, and measurement columns, empowering users to easily locate and monitor time series data, coupled with insights on its processing.
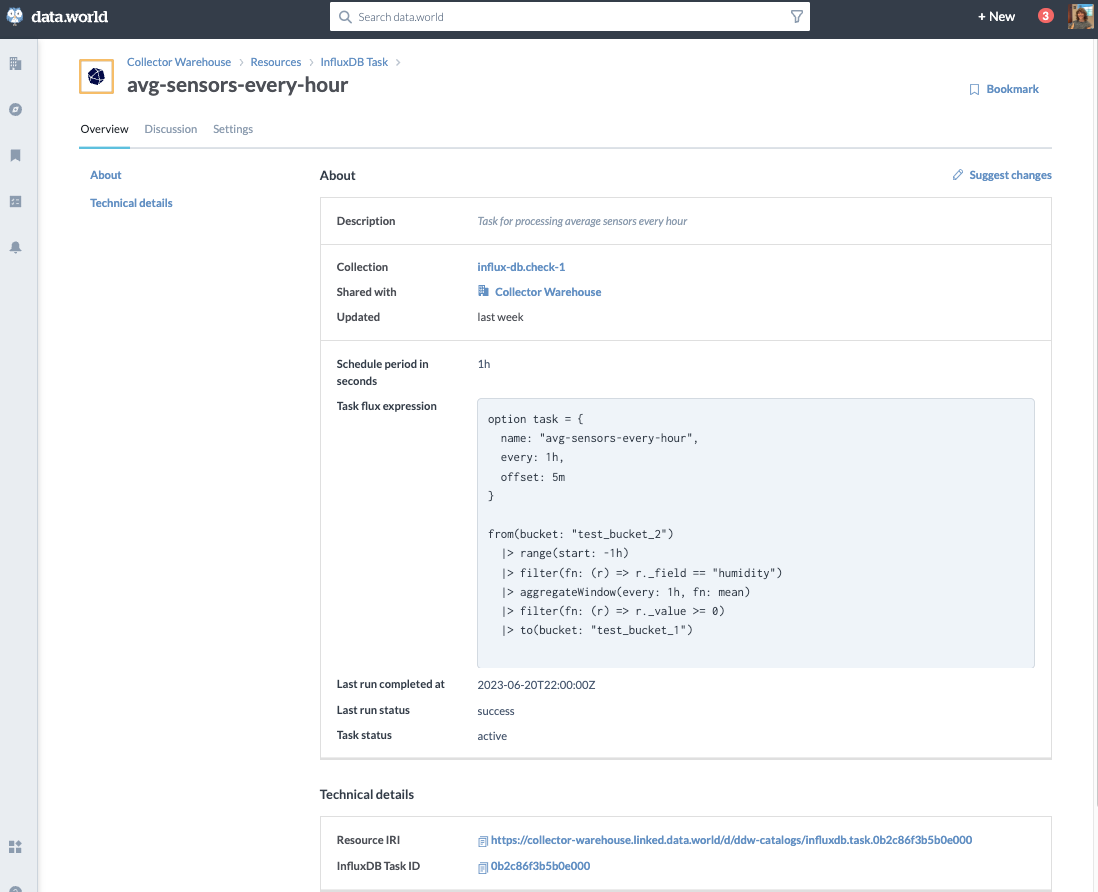
An example of metadata from an InfluxDB Task inside the data.world platform, including the expression, last run status, and task status.
Important
The InfluxDB collector can be run in the Cloud or on-premise using Docker or JAR files.
Note
The latest version of the Collector is 2.330. To view the release notes for this version and all previous versions, please go here.
What is cataloged
The collector catalogs the following information.
Object | Information cataloged |
|---|---|
Explicit Bucket |
|
Implicit Bucket
|
|
Label |
|
Measurement Schema |
|
Organization |
|
Task |
|
Telegraf Configuration |
|
Relationships between objects
By default, the harvested metadata includes catalog pages for the following resource types. Each catalog page has a relationship to the other related resource types. If the metadata presentation for this data source has been customized with the help of the data.world Solutions team, you may see other resource pages and relationships.
Resource page | Relationship |
|---|---|
Explicit Bucket |
|
Measurement Column |
|
Measurement Schema |
|
InfluxDB version supported
The collector supports InfluxDB Cloud 2.0.
Authentication supported
The collector authenticates to InfluxDB using using token-based authentication.