Cataloging sensitive data with DWCC-SDD (legacy version)
Note
If Catalog toolkit is deployed on your system, use this documentation.
There are three parts to using the DWCC-SDD collector to catalog the sensitive data in your data source:
Set up the required resources.
Run the collectors.
Create the sensitive data catalog file.
The first time you run the SDD collector, you will need to do all of these steps in order. Once you have completed your configuration, however, you can set the collectors to run and upload your sensitive data catalog file automatically as needed.
STEP 1: Set up the required resources
The first part of running the collector is to gather all the required resources. You will need:
To request the Sensitive Data Collector from support
To create a ddw-sensitive data dataset
Docker installed on the machine from which you wish to run the collector
Note
The DWCC-SDD collector only runs with Docker.
STEP A: Request the Sensitive Data Collector from support
Submit a request from our support website. Note that support will turn on this feature only if you have bought the add-on for it.
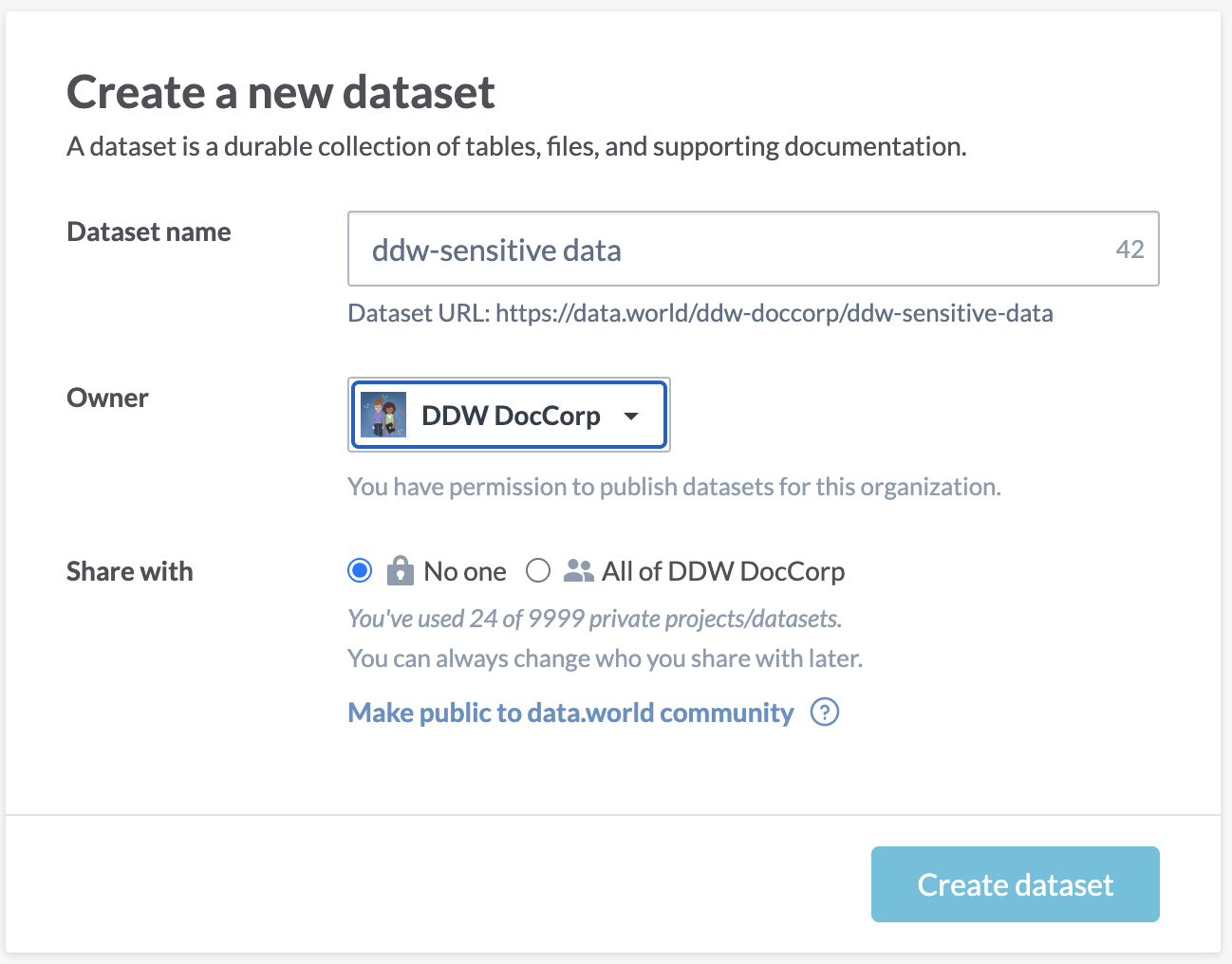
STEP B: Create a dataset
In the data.world organization, create a dataset with the name ddw-sensitive-data.
If you need help setting up your dataset, detailed instructions can be found here. Create the dataset with your organization as the owner and set it to private.
Important
You can name this dataset anything you would like--you can even use an existing dataset like ddw-catalogs. However. we recommend creating a specific ddw-sensitive data dataset to keep the workflow clean and separate.
STEP C: Install Docker
Note
The DWCC-SDD collector only runs with Docker.
Install Docker on the machine from which you wish to run the collector.
STEP D: Run the collector
Important
You can only run DWCC-SDD on a database that has already been cataloged.
Open a terminal window from the directory where you uploaded the dwcc-sdd-x.y.tar.gz zip file. Unzip and load the file into Docker using with the following command
gunzip dwcc-sdd-x.y.tar.gz && docker load -i dwcc-sdd-x.y.tar
Run the collector. If you are going to run DWCC-SDD on Snowflake, the command will be:
docker run -it --rm --mount type=bind,source=/tmp,target=/dwcc-output \ --mount type=bind,source=/tmp,target=/app/log dwcc-sdd:latest \ catalog-snowflake -S <SCHEMA> -a <DDW ORG> -d <DATABASE> -n <CATALOG NAME> -o "/dwcc-output" \ -P <PSWD> -r PUBLIC -s <CONNECTION> -p 443 -u <USER>
Command examples for other sources are available here. The resulting file will be <database_name>.<catalog_name>-sdd.dwec.ttl
Save the resulting file <database_name>.<catalog_name>-sdd.dwec.ttl from SDD docker to the ddw-sensitive-data dataset.
STEP 2: Configure the metadata profile for Sensitive Data Discovery
To configure the metadata profile for sensitive data:
Create an mdp-sensitive-data.ttl file as follows:
Copy the following ttl file contents in a text editor.
Replace yourorgname with the name of your organization.
Save the file as mdp-sensitive-data.ttl on your machine.
@prefix : <https://yourorgname.linked.data.world/d/ddw-catalogs/> . @prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> . @prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> . @prefix owl: <http://www.w3.org/2002/07/owl#> . @prefix label: <http://purl.org/net/vocab/2004/03/label#> . @prefix dwec: <https://dwec.data.world/v0/> . @prefix dct: <http://purl.org/dc/terms/> . @prefix skos: <http://www.w3.org/2004/02/skos/core#> . @prefix dcat: <http://www.w3.org/ns/dcat#> . :MetadataPresentation-sddClassificationType rdf:type dwec:MetadataPresentation ; rdf:type dwec:Facetable ; rdfs:label "Sensitive Data Classification" ; dwec:forType dwec:DatabaseTable, dwec:DatabaseColumn ; dwec:inMetadataSection :MetadataSectionInformational ; dwec:presentationSortOrder 1 ; dwec:viaProperty :sensitiveDataClassificationType . :MetadataPresentation-sddColumnClassificationMetric rdf:type dwec:MetadataPresentation ; rdfs:label "Sensitive Data Classification Metric" ; dwec:forType dwec:DatabaseColumn ; dwec:inMetadataSection :MetadataSectionInformational ; dwec:presentationSortOrder 2 ; dwec:viaProperty :sensitiveDataClassificationMetric .
Upload the mdp-sensitive-data.ttl file to the ddw-catalogs dataset.
STEP 3: Configure Eureka Automation for Sensitive Data Discovery
In this section, we create the Sensitive Data project and link it with the Metadata Knowledge Graph dataset in the organization.
To create the project:
Create a project called ddw-eureka-sensitive-data.
On the Project details page, click the Launch Workspace button.
Link the dataset ddw-sensitive-data from Step 1 to the project by clicking Add > Dataset.
Link the dataset ddw-metadata-knowledge-graph to the project by clicking Add > Dataset. If you haven't created this dataset, follow the instructions here.
Create a new SPARQL Query and add the following query. Replace yourorgname with the name of your organization.
PREFIX : <https://yourorgname.linked.data.world/d/ddw-catalogs/> construct { ?x :sensitiveDataClassificationMetric ?metric. ?x :sensitiveDataClassificationType ?type. ?table :sensitiveDataClassificationType ?type. } where { { SELECT DISTINCT ?x ?metric ?type WHERE { ?x dwec:hasSensitiveDataClassification [ dwec:hasSensitiveDataClassificationMetric ?metric; dwec:hasSensitiveDataClassificationType [ rdfs:label ?type; ] ]. } } UNION { SELECT DISTINCT ?table ?type WHERE { ?x dct:isPartOf ?table. ?x dwec:hasSensitiveDataClassification [ dwec:hasSensitiveDataClassificationMetric ?metric; dwec:hasSensitiveDataClassificationType [ rdfs:label ?type; ] ]. } } }Save the query with the name sensitive-data.ttl.rq
STEP 4: Execute the Eureka Automation for Sensitive Data Discovery
Run the sensitive-data.ttl.rq SPARQL query from the previous step.
From the Results page, select Download the results > Save to dataset or project.
In the Save data extract window:
a. The query name will automatically appear. Just delete the suffix .rq
b. Save the file to the ddw-catalogs dataset of your organization. You must set the file to auto-sync every hour.
Important
This file goes in the ddw-catalogs dataset.
View the results
Now that you have set up sensitive data, you can:
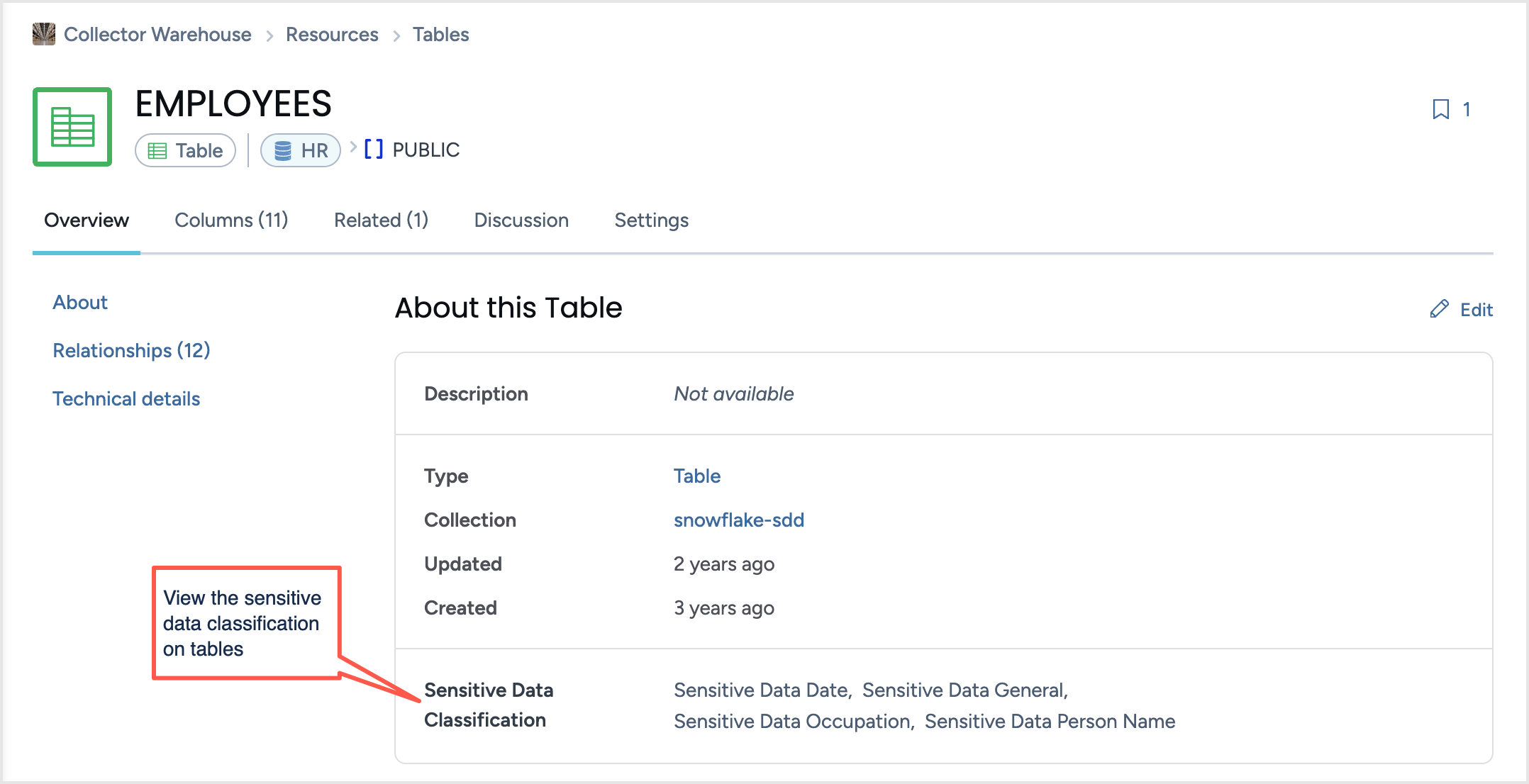
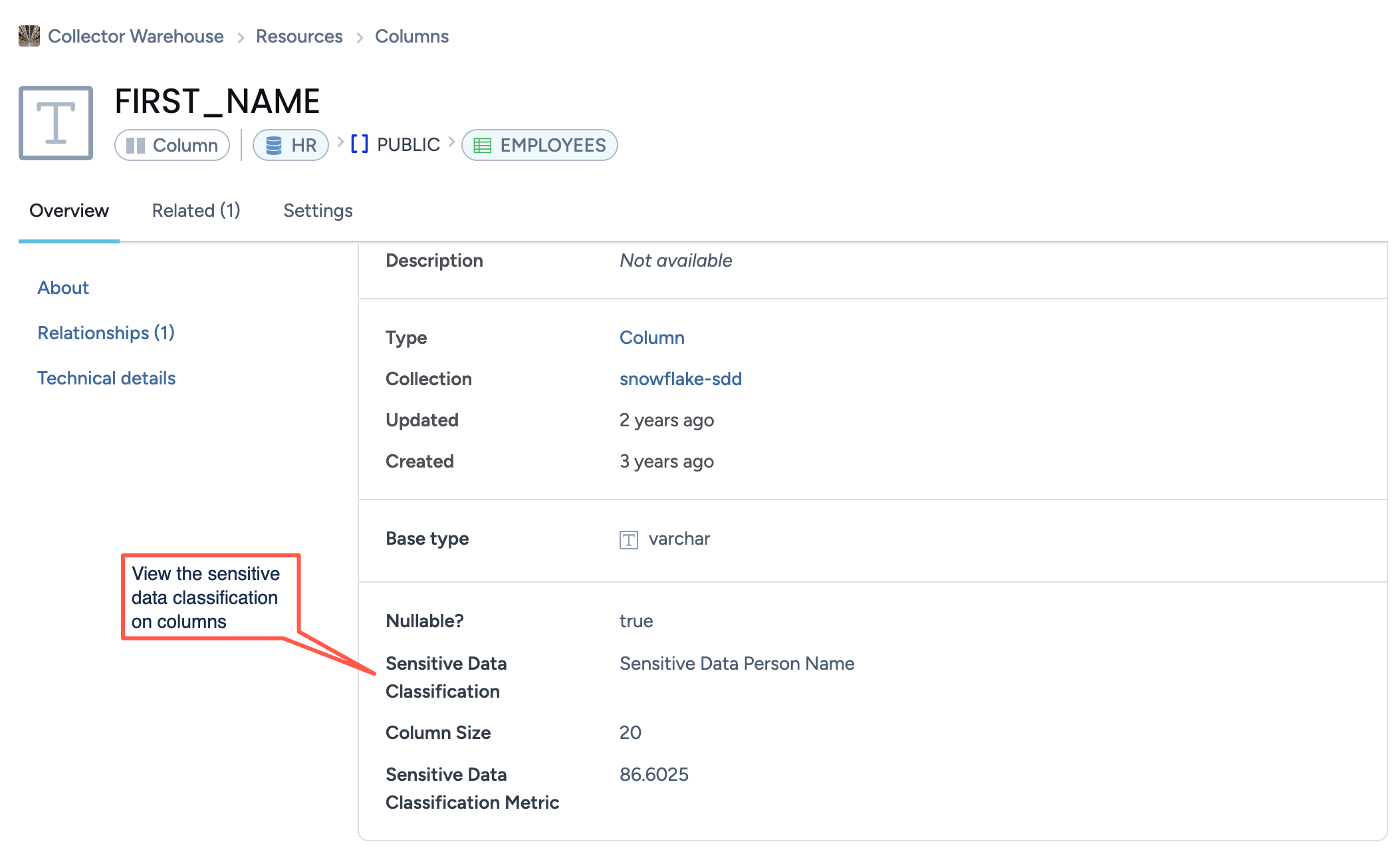
Browse to the resources to see the type of sensitive data.
On various product pages such as Search results, Resources, use the Sensitive Type filter to narrow down lists by sensitive types attached to the resources.