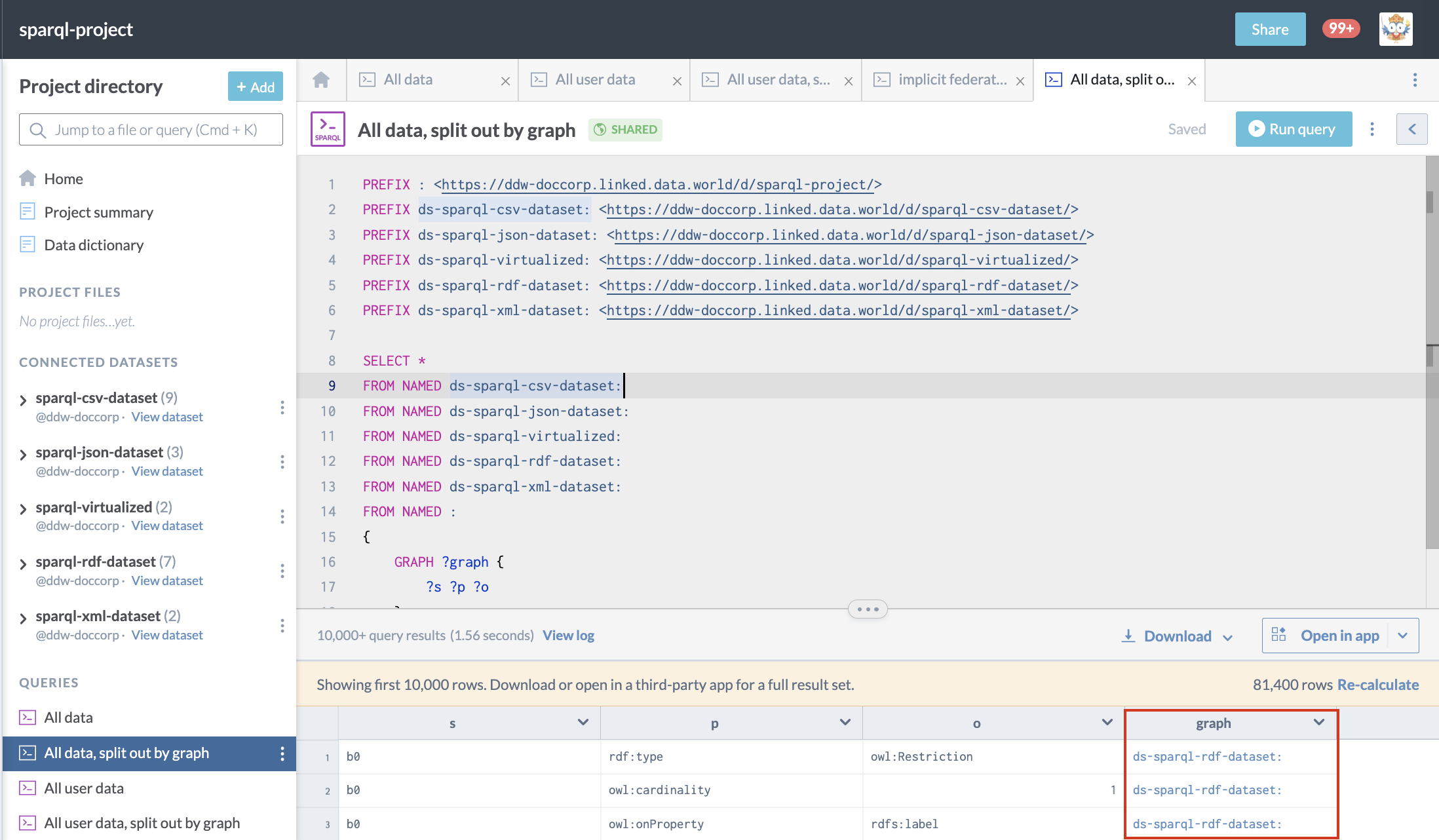
Query basics
Queries in data.world are run from the project workspace. The workspace is accessed from the Launch workspace button at the top right of the Overview tab of either a dataset or project page.
All data that resides on data.world is stored in RDF graphs consisting of triples. Each dataset in data.world has a default graph.
Default graph
The default graph contains all the data from all of the files that you add to the dataset plus all of the metadata that we add in. This metadata is generated according to several standard data description ontologies and is added to help manage, track, and publish your data.The default graph for a project contains all of the default graphs from the datasets in the project merged into a new default graph. When you run a SPARQL query, it runs against the default graph of the dataset or project.
Note
Note: By default, a SPARQL query runs against ALL of the data in the dataset/project.
In SPARQL FROM is optional, and if you don't use it you get a default. This is opposite the query behavior in SQL. The presence (or absence) of namespace PREFIXes has no impact on the set of triples the query runs against; only FROM clauses can do that.
Examples - Query basics
These examples show queries that return all the triples in the default graph for a dataset and for a project. Notice that the structure of the queries is identical--there is nothing to indicate from where to pull the data.
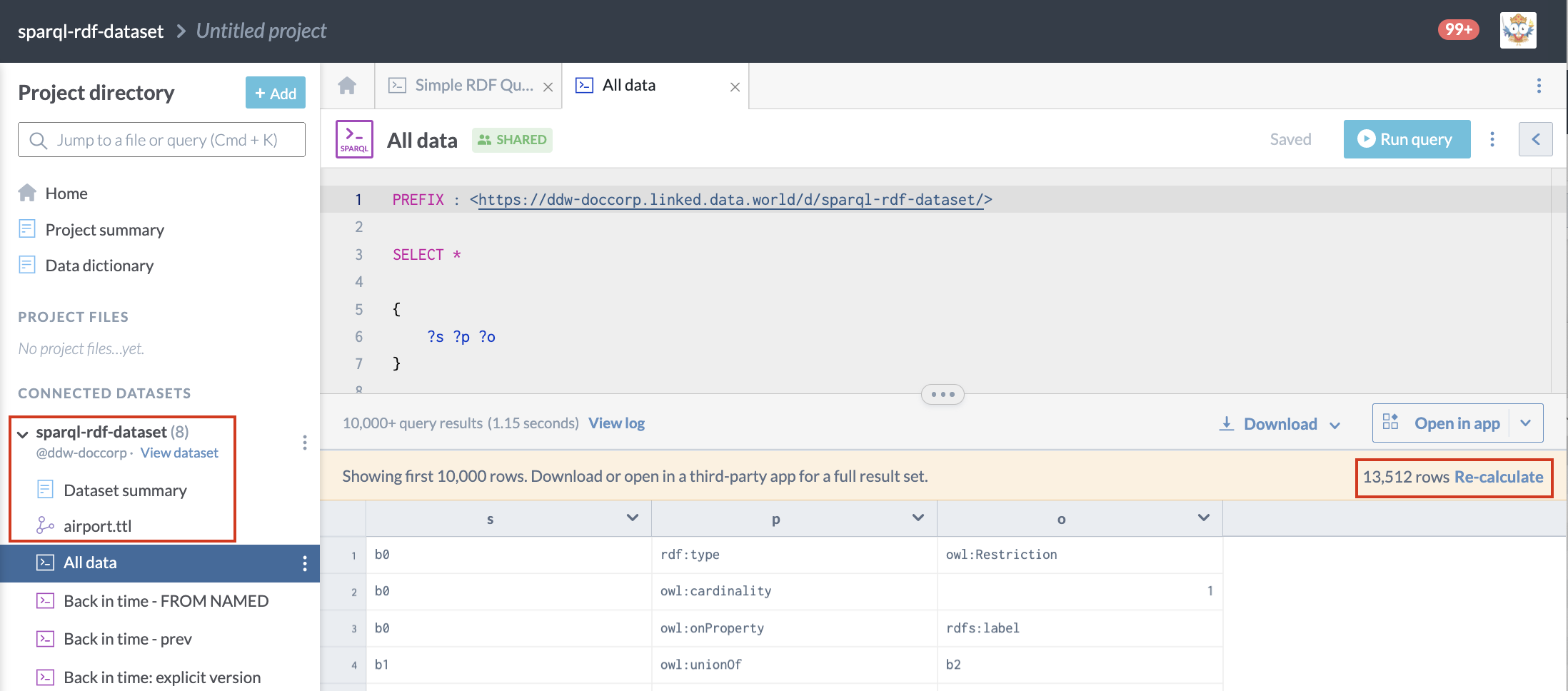
The following query is run against the default graph for the dataset sparql-rdf-dataset. This dataset has one file in it--airport.ttl--and all the data returned comes from it and from the metadata added in by data.world:
PREFIX : <https://ddw-doccorp.linked.data.world/d/sparql-rdf-dataset/>
SELECT *
{
?s ?p ?o
}This is what it looks like on data.world:
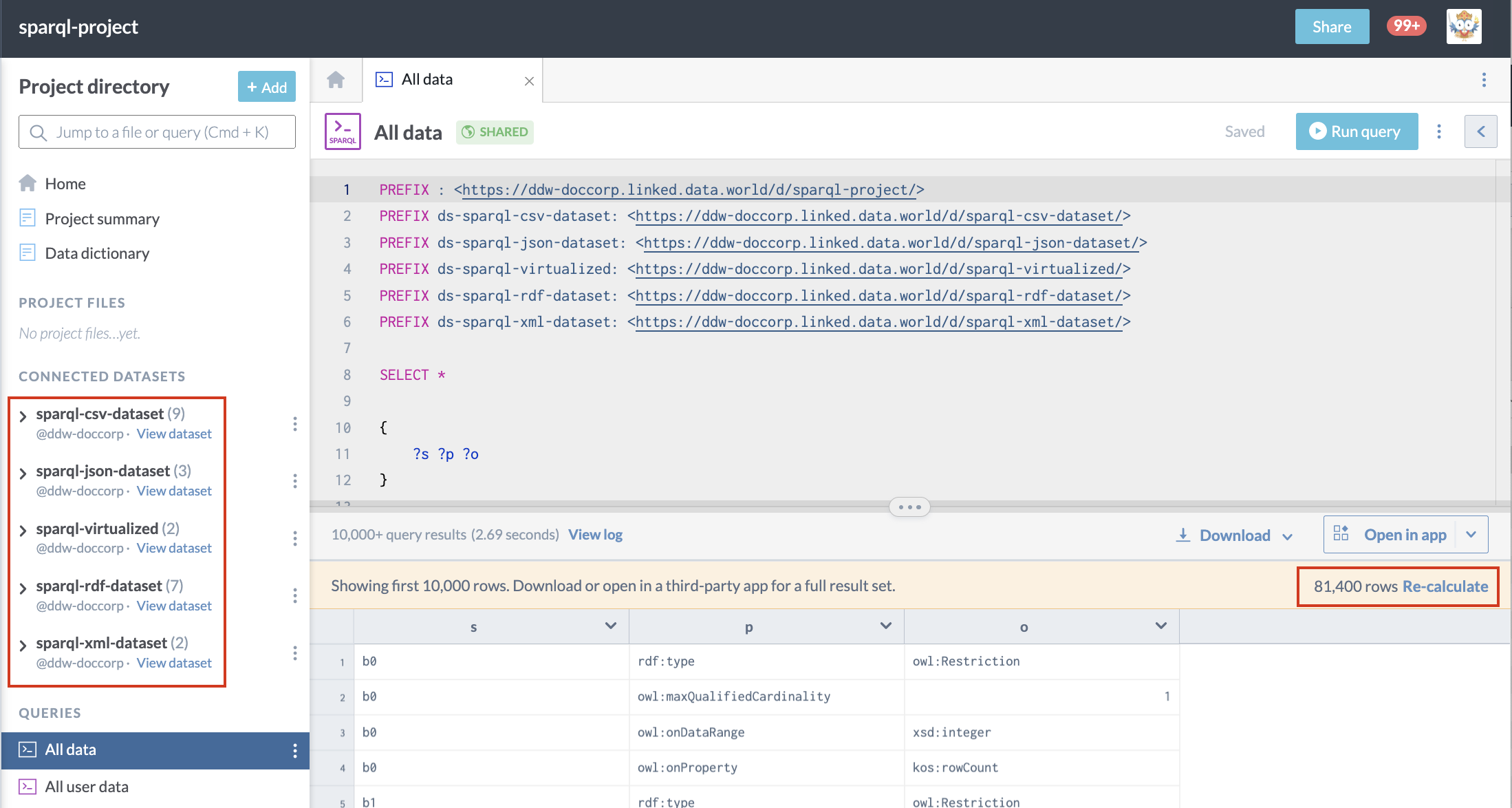
The following query is run against the default graph for the project sparql-project. This project has several linked datasets in it, each with their own files.
PREFIX : <https://ddw-doccorp.linked.data.world/d/sparql-project/>
PREFIX ds-sparql-csv-dataset: <https://ddw-doccorp.linked.data.world/d/sparql-csv-dataset/>
PREFIX ds-sparql-json-dataset: <https://ddw-doccorp.linked.data.world/d/sparql-json-dataset/>
PREFIX ds-sparql-virtualized: <https://ddw-doccorp.linked.data.world/d/sparql-virtualized/>
PREFIX ds-sparql-rdf-dataset: <https://ddw-doccorp.linked.data.world/d/sparql-rdf-dataset/>
PREFIX ds-sparql-xml-dataset: <https://ddw-doccorp.linked.data.world/d/sparql-xml-dataset/>
SELECT *
{
?s ?p ?o
}This is what it looks like on data.world. Note that we do we not have to specify which datasets to run the query against, but we also cannot tell from which ones the data came:
If you want to see where the data originated, you could modify your query by adding in FROM NAMED clauses and looping back through them with a GRAPH pattern:
PREFIX : <https://ddw-doccorp.linked.data.world/d/sparql-project/>
PREFIX ds-sparql-csv-dataset: <https://ddw-doccorp.linked.data.world/d/sparql-csv-dataset/>
PREFIX ds-sparql-json-dataset: <https://ddw-doccorp.linked.data.world/d/sparql-json-dataset/>
PREFIX ds-sparql-virtualized: <https://ddw-doccorp.linked.data.world/d/sparql-virtualized/>
PREFIX ds-sparql-rdf-dataset: <https://ddw-doccorp.linked.data.world/d/sparql-rdf-dataset/>
PREFIX ds-sparql-xml-dataset: <https://ddw-doccorp.linked.data.world/d/sparql-xml-dataset/>
SELECT *
FROM NAMED ds-sparql-csv-dataset:
FROM NAMED ds-sparql-json-dataset:
FROM NAMED ds-sparql-virtualized:
FROM NAMED ds-sparql-rdf-dataset:
FROM NAMED ds-sparql-xml-dataset:
FROM NAMED :
{
GRAPH ?graph {
?s ?p ?o
}
}This is what it looks like run on data.world: