About Sensitive Data Discovery (legacy version)
Warning
This feature is currently in Beta and is not widely available to all customers. Keep in mind that you will need to purchase an add-on to use this feature. For more details, please reach out to your Customer Success specialist.
What is Sensitive Data Discovery?
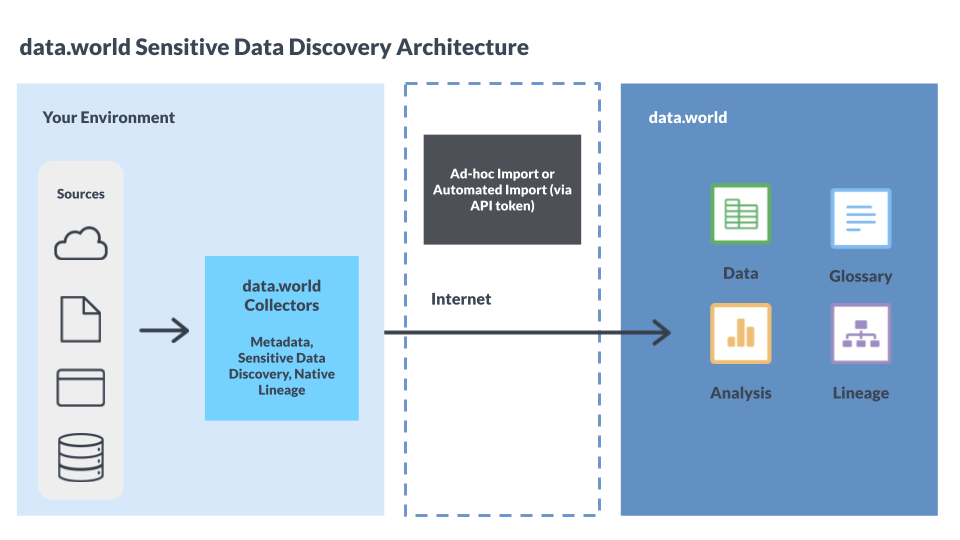
Sensitive Data Discovery, is a method that employs machine learning to automatically identify and categorize sensitive data in your source technology. Sensitive data can be Personal Identifiable Information (PII), Protected Health Information (PHI), or Payment Card Industry (PCI) information, to name a few. After scanning the source technology and classifying the data, the collector uploads this classification metadata to data.world. Users can then view these classifications for resources cataloged from their source technology.
The collector can scan any table, accessible via SQL, that contains at least one row of data. It does not have a limit on the number of tables it can scan. Tables are scanned at the column level.
Note
The Sensitive Data Collector (DWCC-SDD) performs scans on your source technology. However, it does not perform scans on live connected datasets or virtualized data assets within data.world.
The collector selects data from each table to classify by querying the first 1000 rows in the table or all the rows, if the table has fewer than 1000.
DWCC-SDD utilizes third-party Sensitive Data Discovery service to categorize your data. The collector takes a sample of data from the source technology, sends this sampled data to the bundled library for classification, and then captures the classifications in the collector output.
As the model is integrated with the collectors, no data is sent to third-party Sensitive Data Discovery service and the service does not directly connect to or read from the source database. Data utilized for classification is not used for model training. Since the collectors only catalogs classification metadata, the actual data used in the classifications is not stored on the data.world platform.
Key Features
Sensitive Data Discovery consists of four main features:
Scan: The tool scans multiple data sources. It uses pre-trained machine learning to instantly identify over 30 types of sensitive data.
Classification: This feature allows you to distinguish between various types of sensitive data and apply specific rules for handling each type. For example, the term confidential could have a unique meaning within your organization. By applying the confidential classification, you can apply your business logic to the data.
Action: All the information obtained is completely reportable. You can generate a report detailing all your assets, including the sensitive data types and classifications applicable to them.
Integration: Finally, you have the option to export these reports to your preferred BI tool to integrate them into a broader system or project.
Scanned entity types
DWCC-SDD scans the following entity types.
LOCATION_ADDRESS
DATE
EMAIL_ADDRESS
SSN
NAME
PASSPORT_NUMBER
NUMERICAL_PII
ORGANIZATION
OCCUPATION
ORIGIN
PASSWORD
PHYSICAL_ATTRIBUTE
POLITICAL_AFFILIATION
RELIGION
TIME
URL
ZODIAC_SIGN
CREDIT_CARD
CREDIT_CARD_EXPIRATION
CVV
BANK_ACCOUNT
ROUTING_NUMBER
ID_NUMBER
IP_ADDRESS
USERNAME
HEALTHCARE_NUMBER
BLOOD_TYPE
MEDICAL_CONDITION
DRUG
INJURY
MEDICAL_PROCESS
MEDICAL_OTHER
MEDICAL_STATISTICS
Supported sources
The Sensitive Data Collector can be run on the following sources:
Amazon Athena
AWS Redshift
Google BigQuery
PostgreSQL
Snowflake
Supported languages for the content processed from the source
The Collector can be run on content in various languages, such as, Dutch, English, French, German, Hindi, Italian, Japanese, Korean, Mandarin (simplified), Portuguese, Russian, Spanish, Tagalog, Ukrainian.
Important things to note
Before initiating the Sensitive Data Discovery collector, verify that your organization has a database that has been cataloged already.
The Sensitive Data Collector does not operate on datasets that are already imported and virtualized into the system. It should be run in conjunction with the regular Collector to tag incoming data in the application.
Every time new data is imported into the application using the regular Collector, you should rerun the Sensitive Data Collector.