Running the MongoDB collector in Cloud
Warning
This collector is in public preview. It has passed our standard testing, but it is not yet widely adopted. You might encounter unforeseen edge cases in your environment. data.world is committed to promptly addressing any issues with public preview collectors. If you face any problems, please report them through your Customer Success Director, implementation team, or support team for assistance.
Important
If your system is configured with the Catalog Toolkit , please follow these instructions to prepare your system for collectors runs and to make sure the collectors output show in the correct organizations and datasets.
Configuring the cloud collector for MongoDB
To configure the cloud collector for MongoDB:
In the Catalog experience, go to the Admin page > Metadata collectors section.
Click the Add a collector button.
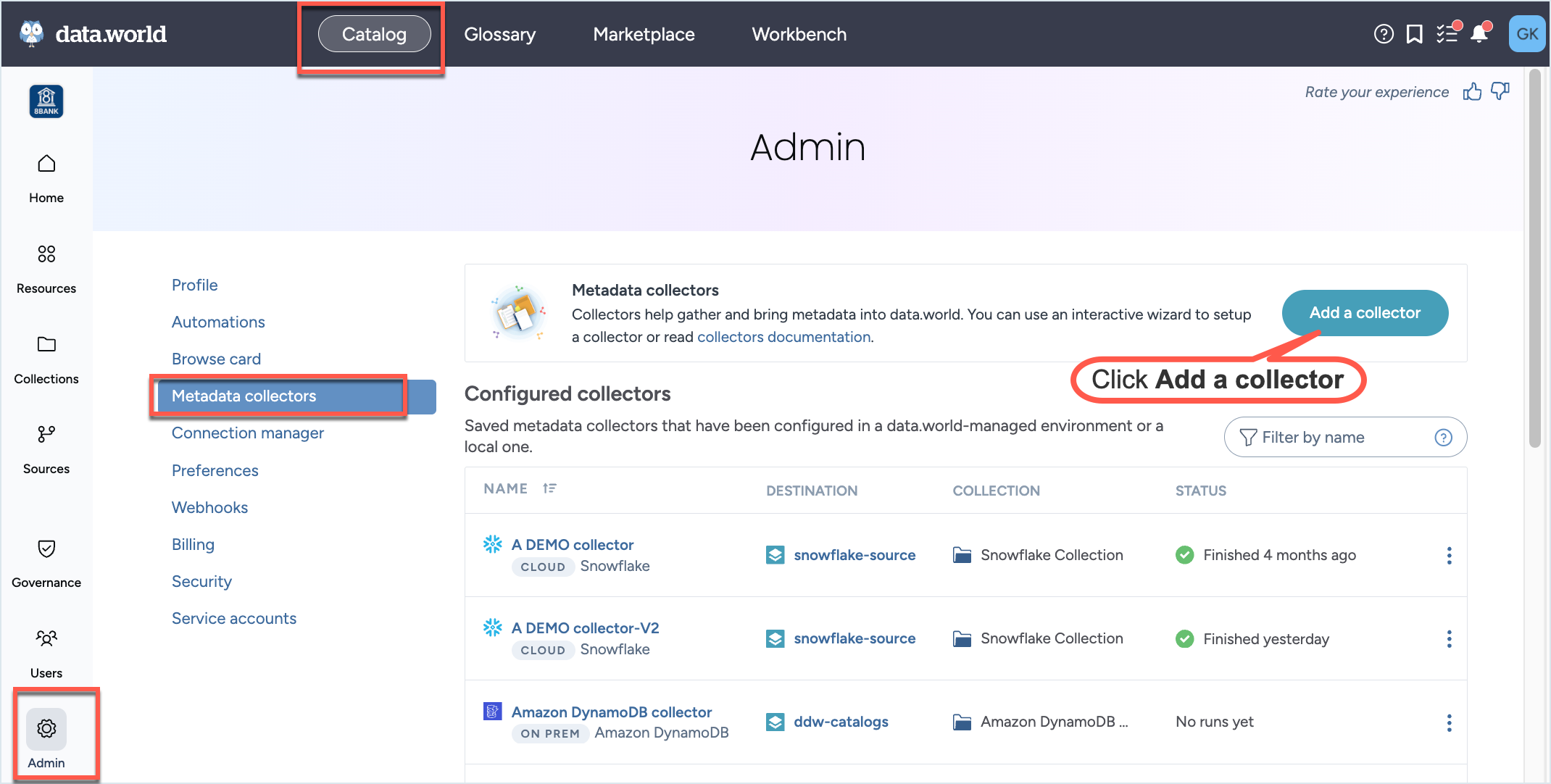
On the Choose metadata collector screen, select the correct metadata source. Click Next.
On the Choose where the collector will run screen, in the Cloud section, select data.world. Click Next.
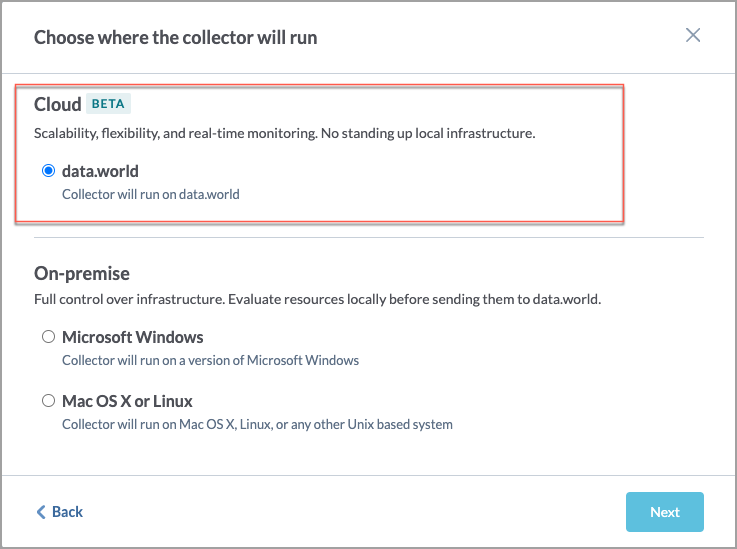
On the Configure a cloud MongoDB Collector screen, set the following:
On the next screen, set the following properties and click Next.
Table 2.Field name
Details
Required?
Connection String
Specify the connection string to connect to your MongoDB cluster/instance. Ensure any option parameters are URL encoded.
To get a connection string, go to the selected cluster in the MongoDB web interface from which you want to collect the catalog, click Connect > Drivers, then select Java and your desired authentication method. For example:
For username/password authentication, use a string like mongodb+srv://<db_user>:<db_password>@<clusterUrl>/?retryWrites=true&w=majority&appName=<clusterName>.
Replace <db_password> with the password for the <db_user> database user, <clusterUrl> and <clusterName> with your cluster URL and name accordingly.
For X.509 authentication, use a string like mongodb+srv://<clusterUrl>/?retryWrites=true&w=majority&appName=<clusterName>&authMechanism=MONGODB-X509&authSource=%24external&tls=true.
Replace <clusterUrl> and <clusterName> with the appropriate values. As a prerequisite, set the javax.net.ssl.keyStore and javax.net.ssl.keyStorePassword values as system properties or pass them as java parameters, where:
javax.net.ssl.keyStore: the path to a key store containing the client TLS/SSL certificates
javax.net.ssl.keyStorePassword: the password to access the key store defined in javax.net.ssl.keyStore
For details, see x.509 security and Configure the JVM Key Store documentation pages.
For AWS IAM authentication, use a string like mongodb+srv://<AWS access key>:<AWS secret key>@<clusterUrl>/?authSource=%24external&authMechanism=MONGODB-AWS&retryWrites=true&w=majority&authMechanismProperties=AWS_SESSION_TOKEN:<session token (for AWS IAM Roles)>&appName=<clusterName> aa
Replace <AWS access key> and <AWS secret key> with the secret and access key of your Amazon resource. If you are using an assumed role to authenticate, replace <session token (for AWS IAM Roles)> with the resultant session token. Also, replace <clusterUrl> and <clusterName> with your cluster URL and name accordingly.
For details, see Connection string options documentation.
Yes
Included Databases
Specify the databases to be collected. You can either provide the database name or a regular expression to match. Use the parameter multiple times for multiple specific databases. For example, --include-database="databaseA" --include-database="databaseB"or use a regular expression such as ^(databaseOne|databaseTwo|databaseThree)$.
If multiple regular expressions are specified, the collector will harvest databases that match any of them.
No
Excluded Databases
Specify the databases to be excluded by the collector. You can either provide the database name or a regular expression to match. Use the parameter multiple times for multiple specific databases. For example, --exclude-database="databaseA" --exclude-database="databaseB" or use a regular expression such as ^(databaseOne|databaseTwo|databaseThree)$.
If multiple regular expressions are specified, the collector will exclude databases that match any of them. If both --include-database and --exclude-database are specified, --include-database takes precedence.
No
Analysis Samples Count
Specify the document amount from a collection for sampling analysis ($sample aggregation). It is used to determine collection field types and must be a non-negative integer. The default is 1000.
No
On the next screen, provide the Collector configuration name and an optional Configuration description, and set the run schedule. You can also set the schedule at a later point.
Click Save and View to go the collector details page.
Scheduling collector runs
Important things to note:
Different collectors can be scheduled to run at the same time, but one collector can only run once a day.
It is recommended that you schedule the runs in off-peak hours.
The collector runs in the timezone in which the scheduler is located. For example, if the scheduler sets the collector runs from PST timezone, the collectors will follow the PST timezone.
Runs may start up to one hour after the scheduled time.
Cloud collectors are designed to automatically run against the latest version of the collector supported by the UI.
To schedule collector runs:
On the Configured collectors page, locate the collector you want to run on a schedule.
Click the Edit configurations button.
Go to the screen where you can set the schedule for the collector and set the following:
Enable the Scheduled runs option.
From the Frequency dropdown, select from Daily, Weekly, or Monthly.
For Weekly and Monthly options, select the day when the collector should run.
Select the time for running the collector.
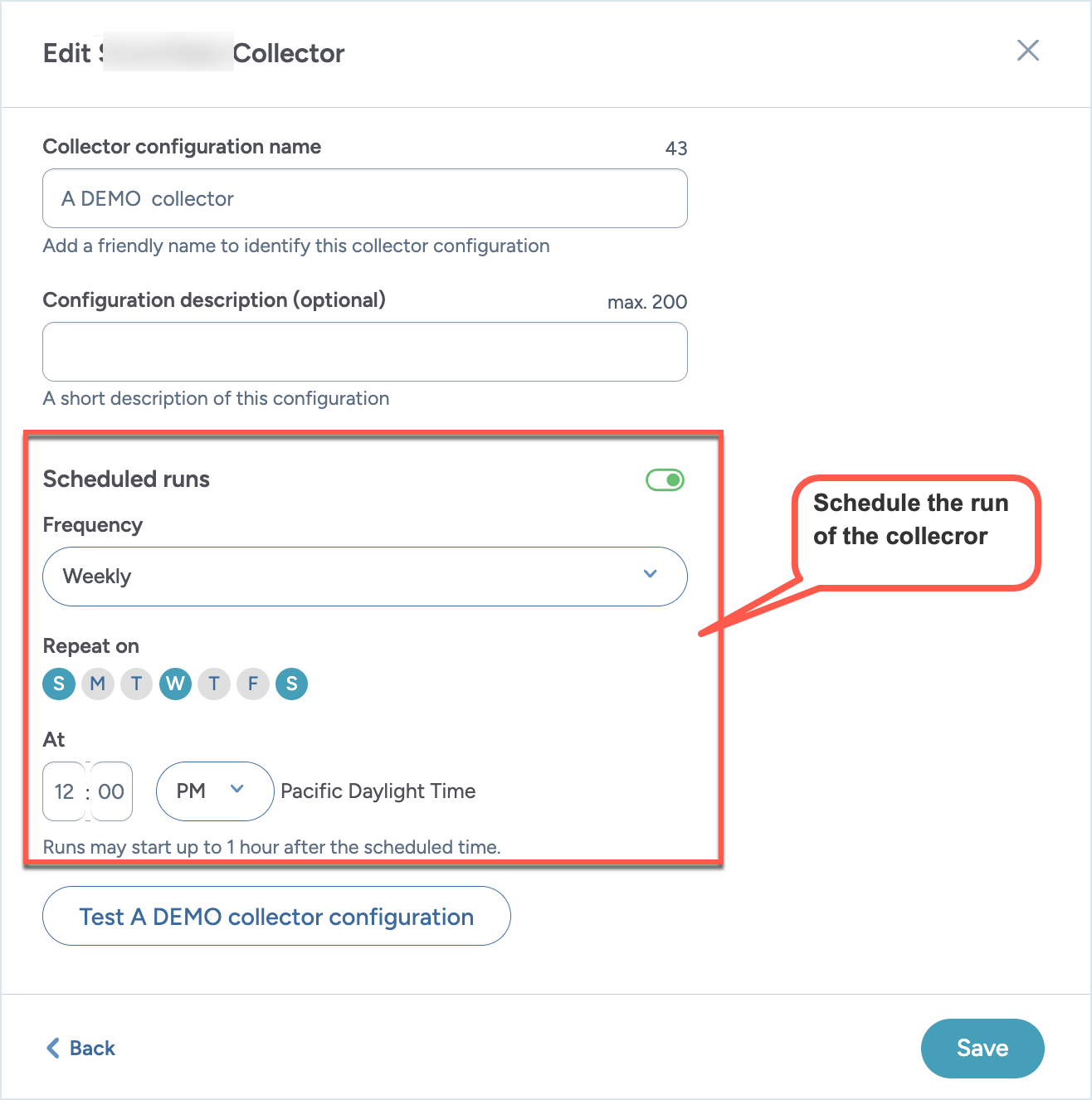
Click Save and view. The schedule and next run date and time are displayed on the collector details page.
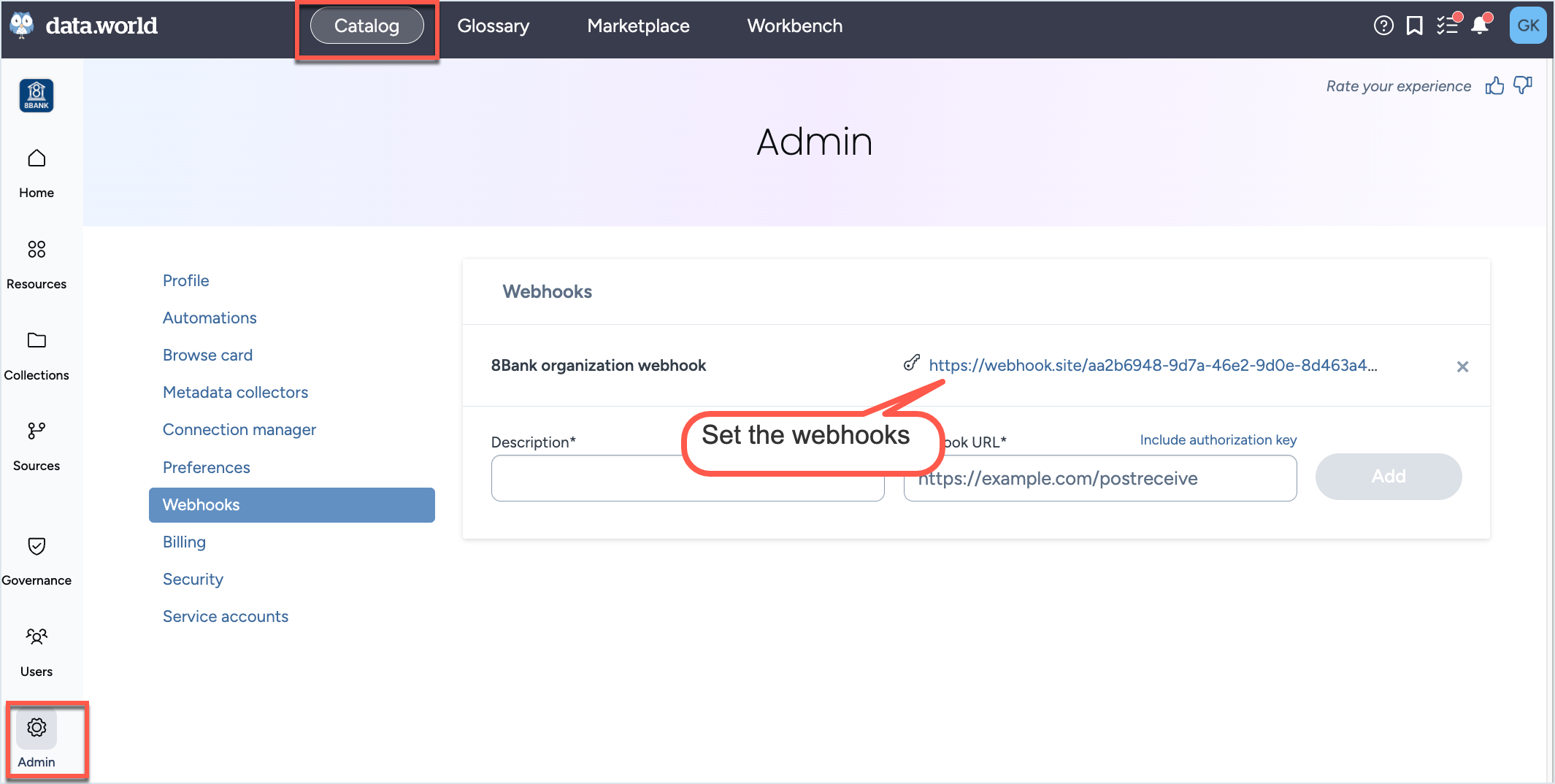
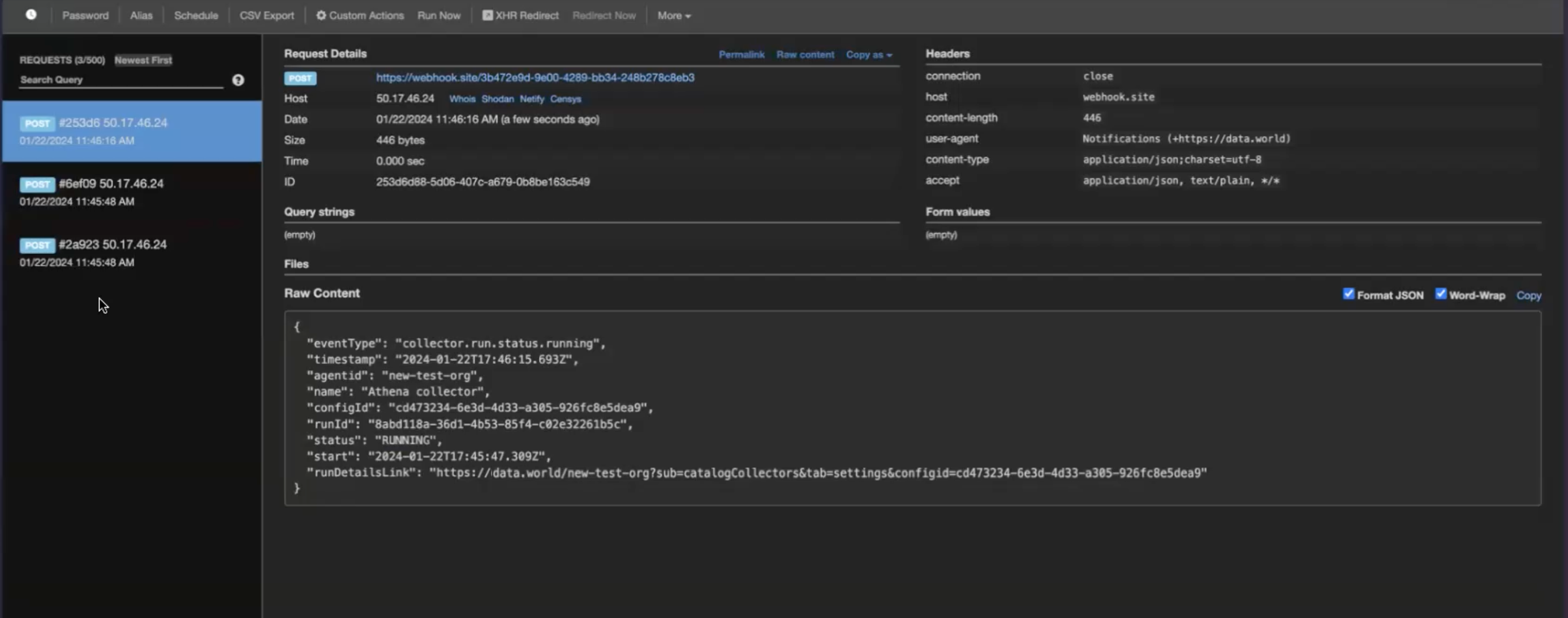
To get notifications about the collector runs, simply setup web hooks at the Organization level from the Catalog experience> Admin page. The Webhooks will automatically start capturing the Status events (Pending, Provisioning, Running, Completed, Error, Cancelled) for the collector runs.
Sample data captured by the webhook.
Running collectors manually
After setting up the collector configuration, it's recommended to manually execute it once to confirm everything is set up correctly. Even for collectors scheduled to run automatically, you can initiate them manually at any time. Cloud collectors are designed to automatically run against the latest version of the collector supported by the UI.
To run the collectors manually:
On the Configured collectors page, locate the collector you want to run.
On the collector configuration details page, click the Run now button. Alternatively, on the Configured collectors page, click the Three dot menu and click Run/Sync now button.
On both pages, the Status field shows the status as Running with information about time elapsed since the run was started.
The collector starts running in the background and you can navigate away from the page at any time. If a collector run errors out, the Status section and the Status field update to an Error state.
After the collector has completed the required pre-configuration steps and starts harvesting the metadata, you get an option to Cancel the harvesting process, if you want. The Status section and the Status field update to Canceled.
After the collector run has completed, the Status section of the collector configuration details page updates to show the successful status. The Last run summary page also updates to show the total number of resource collected and total number of types of resources collected. The Resources collected by type gives granular level information about the number of resources collected for each type of resource.
Browse to the Collection and Dataset specified while running the collector to view the collector output.
To get notifications about the collector runs, simply setup web hooks at the Organization level from the Catalog experience > Admin page. The Webhooks will automatically start capturing the Status events (Pending, Provisioning, Running, Completed, Error, Cancelled) for the collector runs.
Sample data captured by the webhook.
Canceling a collector run
After starting a collector run, you can cancel it if needed.
Important things to note:
Logs generate only after the collector starts up (about 5 minutes). No logs are available if the collector is canceled before this period.
After canceling a run, the collector produces the logs within 5 minutes
To stop a running collector:
Locate the running collector you want to stop. After the collector has completed the required pre-configuration steps and starts harvesting the metadata, you get an option to Cancel it.
On the collector configuration details page, click the Cancel run button. Alternatively, on the Configured collectors page, click the Three dot menu and click Cancel run button.
The collector stops running. On both pages, the Status field shows the status as Canceled with information about time elapsed since the run was canceled.
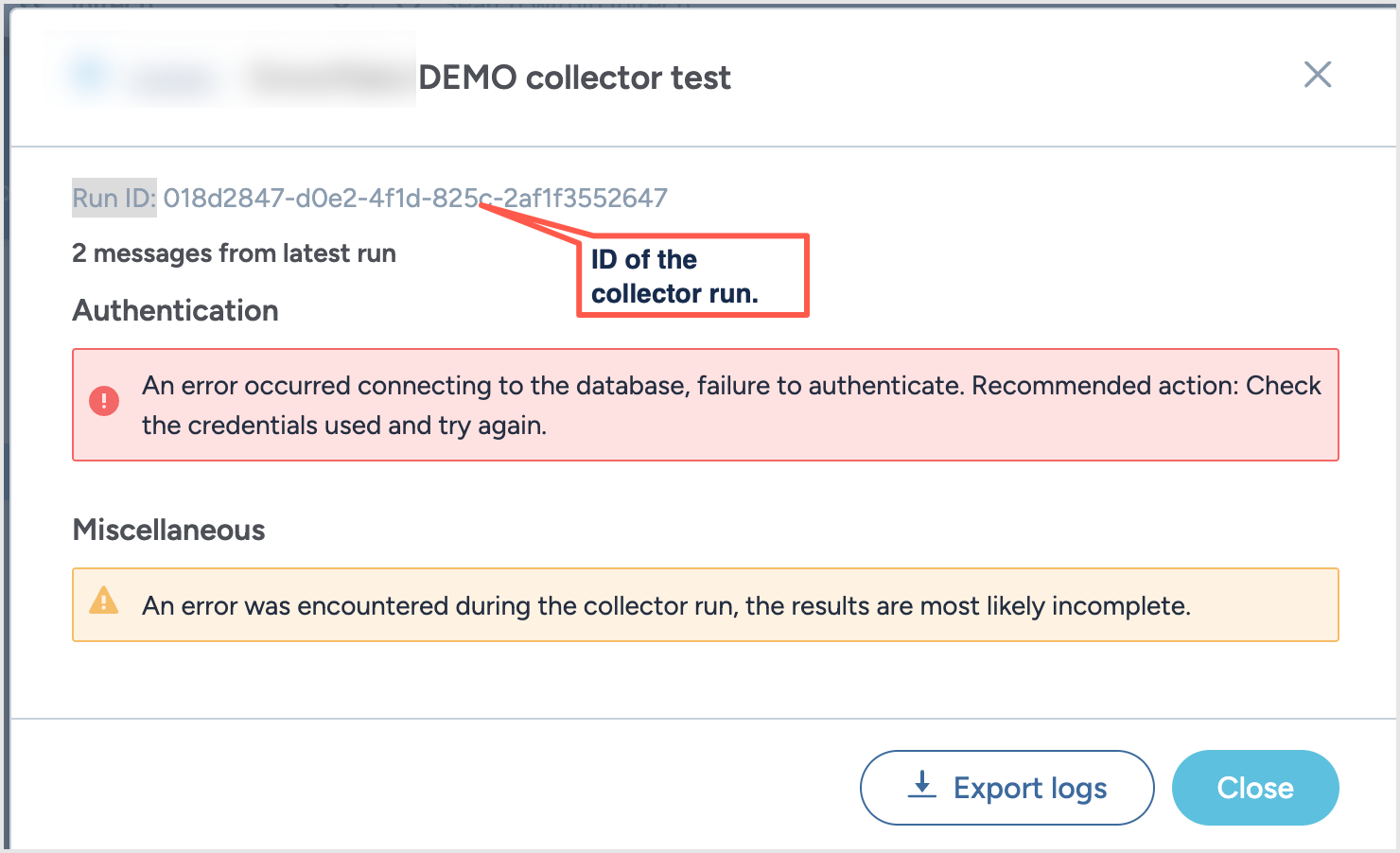
The collector produces a log file in 5 minutes after stop running. To download a logs, click the View debugging info link. A pop-up window opens.
In the pop-up window, click Export logs to download the log file. The window also includes the Run ID of the collector run that failed. While reporting this issue to data.world support team, include this Run ID to help expedite the troubleshooting process.
Copying collector configurations
After you have configured a collector for a source system, you can easily create a copy of the configuration to configure another collector for the same source system but for different parameters.
To copy collector configurations:
On the Configured collectors page, locate the collector configuration you want to copy.
From the Three dot menu, click Duplicate configuration.
In the Edit Collector window, provide a new name for the collector configuration. Optionally, set a schedule. Click Save and view.
You are taken to the copied collector configuration page. Click the Edit Configuration button to adjust the details of the configuration.
Deleting configurations
Important things to note:
Deleting the configuration will not affect the resources that were collected from previous runs.
Any scheduled future runs for the collector are suspended.
To delete a configuration:
On the Configured collectors page, locate the collector configuration you want to delete.
From the Three dot menu, click the Delete configuration button.
Confirm the deletion. The configuration is deleted and removed from the Configured collectors page.