Preparing to run the Power BI Service collector
Setting up pre-requisites for running the collector
Make sure that the machine from where you are running the collector meets the following hardware and software requirements.
Item | Requirement |
|---|---|
Hardware (for on-premise runs only) Note: The following specs are based upon running one collector process at a time. Please adjust the hardware if you are running multiple collectors at the same time. | |
RAM | 8 GB |
CPU | 2 Ghz processor |
Software (for on-premise runs only) Docker or Java Runtime Environment | |
Docker | Click here to get Docker. |
Java Runtime Environment | OpenJDK 17 is supported and available here. |
data.world specific objects (for both cloud and on-premise runs) | |
Dataset | You must have a ddw-catalogs dataset set up to hold your catalog files when you are done running the collector. If you are using Catalog Toolkit , follow these instructions to prepare the datasets for collectors. |
Network connection | |
Allowlist IPs and domains | |
Setting up access for cataloging Power BI resources
Important things to note
A Power BI administrator is needed to enable settings in the Power BI Admin Portal.
Dataflows require the user/service principal to be added to the workspace with at least contributor access. When authenticating with username/password, the app registration needs to have Dataflow.Read.All permissions in API permissions.
STEP 1: Registering your application
To register a new application:
Go to the Azure Portal.
Click the App Registrations option in the Azure services.
Click New Registration and enter the following information:
Application Name: DataDotWorldPowerBIApplication
Supported account types: Accounts in this organizational directory only
Click Register to complete the registration.
STEP 2: Creating Client secret and getting the Client ID
To create a Client Secret:
Go to the Azure Portal.
On the application page, select Certificates and Secrets.
Click on Secret and add a description.
Select the desired expiration date.
Click on Create, and copy the secret value. You will use this value while setting the parameters for the collector.
To get the Client ID from the Azure portal:
Click the Overview tab in the left sidebar of the application home page.
Copy the Client ID from the Essentials section. You will use this value while setting the parameters for the collector.
STEP 3: Setting up authentication
There are two separate ways to authenticate to Power BI:
Service principal
User and password
This section will walk you through the process for both authentication types.
OPTION 1: Setting up REST API for service principals
Important
Perform this task only if you are using the service principal for authentication. You do not need to do this task if you are using user and password for authentication. You can refer to to the Microsoft documentation for more details.
When running under a service principal, there must be no Power BI admin-consent-required permissions set on your app. For more information, see Enable service principal authentication for read-only admin APIs.
When using Service Principal authentication, the collector will automatically harvest all the objects listed here except for personal workspaces, user workspaces, and report pages.
If you want to harvest all apps and any workspace in the tenant:
Use the --all-workspaces-and-apps parameter. This excludes the harvesting of personal and user workspaces by default.
To harvest Personal Workspaces and My Workspaces, add the parameters:
--include-user-workspace
To harvest report pages, you need to give the Service principal access to each workspace that you want to harvest. This is needed because the admin API used to access all workspaces and apps in the tenant does not have an API endpoint for report pages.
To set up service principal authentication:
Sign into Power BI using a Power BI Admin account.
On the Settings page, browse to Admin Portal.
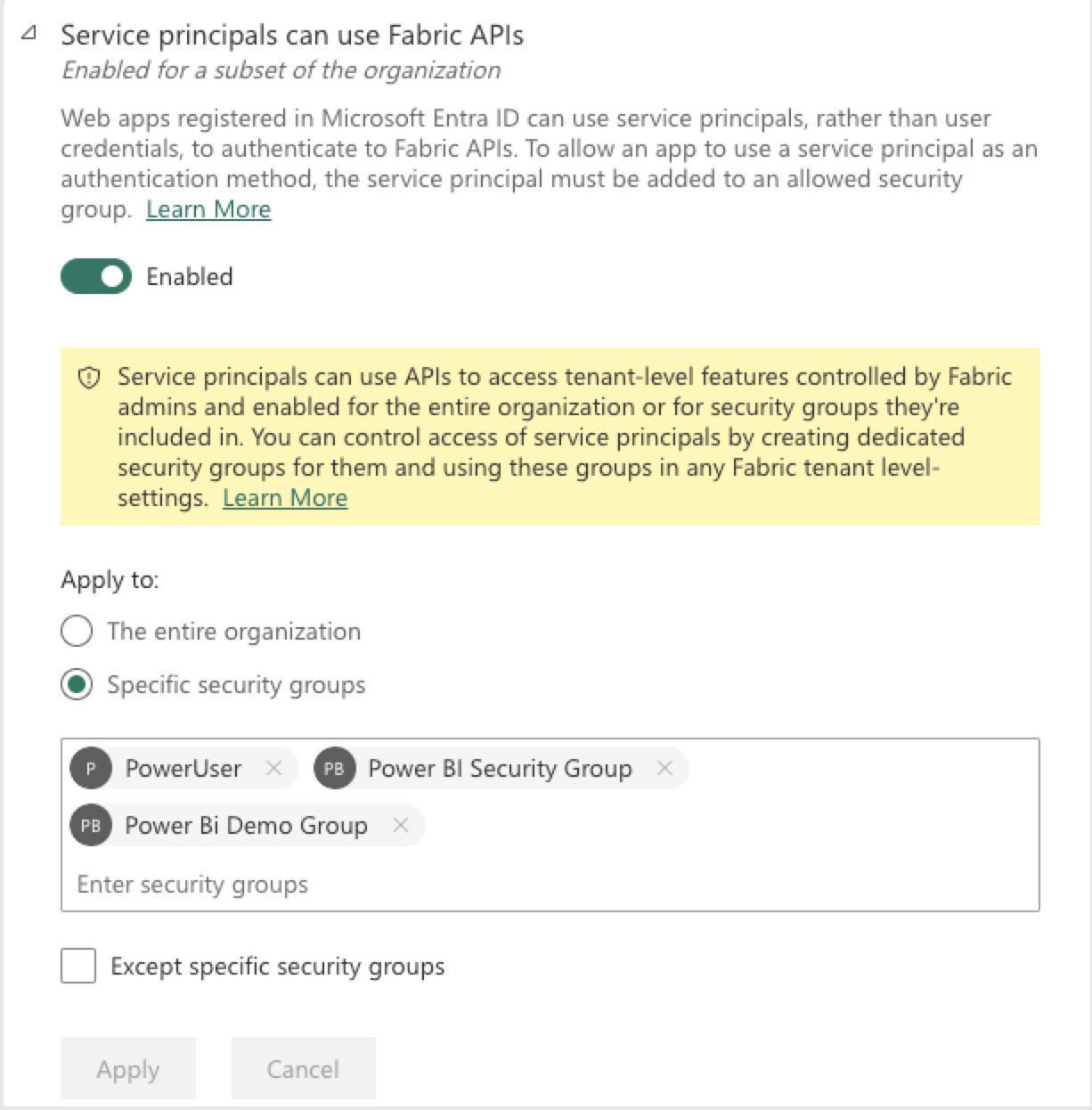
Under developer settings, search for Service principals can use Fabric APIs. Enable the setting and select if it applies to The entire organization or Specific security group and make sure to select a security groups that includes the Service principal. Click Apply to save the changes. See Microsoft documentation for more details.
If you need to add the Service Principal to the workspaces, do the following:
Open the workspace, click on Manage access.
Search for the Service Principal or the Security Group the Service Principal belongs to. If dataflows are used, then at a minimum Contributor access is required, otherwise select Viewer.
Click Add.
OPTION 2: Setting up permissions for username & password authentication
Important
Perform this task only if you are using user and password for authentication. You do not need to do this task if you are using service principal authentication. You can refer to to the Microsoft documentation for more details.
If you are using User authentication, the collector will automatically harvest all the objects listed here except for personal workspaces, user workspaces, and report pages.
If you want to harvest all apps and any workspace in the tenant:
Use the --all-workspaces-and-apps parameter. This excludes the harvesting of personal and user workspaces by default.
To harvest Personal Workspaces and My Workspaces, add the parameters:
--include-user-workspace
To harvest report pages, you need to give the user access to each workspace that you want to harvest. This is needed because the admin API used to access all workspaces and apps in the tenant does not have an API endpoint for report pages.
To add permissions when using username and password authentication:
If you are planning to use the all-workspaces-and-apps option while running the collector, the user must have administrator rights (such as Microsoft 365 Global Administrator or Power BI Service Administrator) to use metadata scanning. For details see the Power BI documentation.
If you are not planning to use the all-workspaces-and-apps option, do the the following:
Click on API Permissions, and select Add Permission.
Search for the Microsoft Graph and select the following permissions:
Application permission: Application.Read.All
Delegated permission: User.Read (assigned by default)
Search for the Power BI service, and click on Delegated permissions. Select the following permissions:
App.Read.All
Dashboard.Read.All
Dataflow.Read.All
Dataset.Read.All
Report.Read.All
Tenant.Read.All
Workspace.Read.All
Click on the Grant Admin consent button, which is located next to the Add permission button. This allows the data.world collector to run as a daemon without having to ask the user permission on every crawler run.
Note
Only administrators of the tenant can grant admin consent.
STEP 4: Setting up metadata scanning
Set up metadata scanning to access the detailed data source information, such as tables and columns, provided by Power BI through the read-only admin APIs. Before running metadata scanning on an organization's Power BI workspaces, a Power BI administrator must set it up. The collector uses the Power BI Scanner APIs to establish lineage to source tables and columns. Be sure to familiarize yourself with the limitations to the scanner APIs.
Option 1: When using service principal authentication
Follow the Power BI documentation to enable service principal authentication for Power BI read-only APIs.
Next, follow the Power BI documentation to enable the following enhanced tenant settings for metadata scanning.
Enhance admin APIs responses with detailed metadata
Enhance admin APIs responses with DAX and mashup expressions
Option 2: When using username and password authentication
Important
The user must have administrator rights (such as Microsoft 365 Global Administrator or Power BI Service Administrator) to use metadata scanning. For details see the Power BI documentation.
Follow the Power BI documentation to enable the following enhanced tenant settings for metadata scanning:
Enhance admin APIs responses with detailed metadata
Enhance admin APIs responses with DAX and mashup expressions
STEP 5: Getting the Tenant ID
To find the tenant ID, click the question mark in the Power BI app and then choose About Power BI.
The tenant ID can be found at the end of the Tenant URL. You will use this value while setting the parameters for the collector.
Configuring Power BI for Report Image Harvesting
You must perform these tasks to enable the harvesting of preview images from Power BI reports. Note that report image harvesting is not supported for Power BI Apps.
Enable the Export reports as image files setting from the Admin settings.
Ensure that the reports to be exported are located in a workspace with Premium, Embedded, or Fabric capacity. For details, see the Power BI documentation.
Setting up a YAML file for Lineage Mapping
This is an optional task for harvesting lineage information. Set up the YAML file and pass this YAML file using the Datasource name mapping file (--datasource-mapping-file) option while running the collector.
Set up a YAML file in the following scenarios:
Scenario | Details | Action |
|---|---|---|
You have a data source in Power BI which uses an ODBC connection. In these instances, Power BI does not provide the host or database type of the source. | In the YAML file, map the DSN to a specific database host and type. If the database name is missing in the Power BI data source, add the defaultDatabaseName option to the data source in the YAML file. | |
You have multiple server names (aliases) for the same database instance (host) and the database collector uses a different alias than the one defined in the Power BI connection. | Use the YAML file to map the database host to user-specified aliases. | |
Custom SQL statements are used in Power BI table source definitions. The Power BI collector currently supports connecting to the following database types to resolve lineage from SQL statements: Snowflake, SQL Server, PostgreSQL, Redshift, Oracle, Databricks, Denodo, BigQuery Lineage resolution for table sources using SQL statements only supports SQL consisting of a single SELECT statement. | Configure databases specified in custom SQL statements by including datasourceKey, host, and secure credentials using environment variables. |
To setup the YAML file:
Important
You can use Environment variables in the file for sensitive information such as passwords.
Create a YAML file (datasources.yml).
Multiple Server Name Aliases: Add the following to map a host alias:
datasources: - datasourceKey: "<host or data source key in Power BI source, example>" host: <my-datasource-host>
For example, if in your power BI table source is the following, then the datasourceKey will be the host-alias.snowflakecomputing.com.
let Source = Snowflake.Database("host-alias.snowflakecomputing.com", "KOS_TEST"), PowerBiTest_Test_Table = Source{[Schema="POWERBI_TEST",Item="TEST_TABLE"]}[Data] in PowerBiTest_Test_TableYour datasources.yml file will look like:
datasources: - datasourceKey: host-alias.snowflakecomputing.com host: host-actual.snowflakecomputing.com
Custom SQL statements: Add the following for databases specified in custom SQL statements. Environment variables are supported in the file.
datasources: - datasourceKey: "<host or data source key in Power BI source>" OR - name: <data source name> host: <my-datasource-host> databaseUsername: <username> # recommend setting up env variable databasePassword: <password> # recommend setting up env variable
Use the following option to specify which databases a datasource configuration applies to. If not provided, it is assumed the datasource settings apply to all databases on the given host.
applicableDatabases: - <database_name>
For example:
datasources: - datasourceKey: "example.cpcnqsn422gx.us-east-1.rds.amazonaws.com, 1433" host: example.cpcnqsn422gx.us-east-1.rds.amazonaws.com databaseUsername: ${DB_USERNAME} # recommend setting up env variable databasePassword: ${DB_PASSWORD} # recommend setting up env variable applicableDatabases: - 8bank_databaseOptions available if JDBC properties are required when connecting to the source database:
Table 3.Option
Description
jdbcProperties
Multiple JDBC properties can be specified using a YAML list. The expected format is jdbcProperties: key=value.
For example: jdbcProperties: encrypt=true
For multi value, it would look like:
jdbcProperties:
- encrypt=true
-readOnly=true
Options available for Snowflake databases credentials:
Table 4.Option
Description
databaseUsername: ${DB_USERNAME}
Required if custom SQL queries are used in Power BI database sources.
databasePassword: ${DB_PASSWORD}
Required if SQL queries are used and if a private key is not used for authentication to Snowflake.
snowflakePrivateKeyFile: privateKeyFile
Required if SQL queries are used and if a private key is used for authentication to Snowflake.
snowflakePrivateKeyFilePassword: ${privateKeyFilePassword}
Required if SQL queries are used and if a private key is used for authentication to Snowflake.
snowflakeRole: role
Required if SQL queries are used.
snowflakeWarehouse: warehouse
Use to override warehouses used in Power BI expressions in the database connection.
Options available for Databricks databases credentials:
Table 5.Option
Description
databricksHttpPath
Required if the source database is Databricks.
Options available for Oracle Autonomous Databases:
Table 6.Option
Description
oracleAutonomousDbConnectionString
Required if the source is an Oracle Autonomous Database.
The connection string should be in the format: jdbc:oracle:thin:<host>:<port>/<service_name>, jdbc:oracle:thin:@(address=(protocol=tcps)(port=<port>) (host:<host>))(connect_data=(service_name=<service_name>))(security=(ssl_server_dn_match=yes))), or jdbc:oracle:thin:@alias_name?TNS_ADMIN=/path/to/wallet
Options available for BigQuery:
Table 7.Option
Description
project
Required if the source is a BigQuery table.
bigQueryCredentialJsonString
Required for supplying BigQuery credentials.
ODBC Connections in Power BI: Map the DSN to a specific database host and type.
For ODBC connections, list data sources with their corresponding host and database type.
If ODBC connections use Odbc.Query, specify the username and password.
If ODBC connections specify the database name, include defaultDatabaseName.
datasources: - name: "Name-for-datasource" host: <my-datasource-host> databaseType: <type-of-database> databaseUsername: <username> # optional databasePassword: <password> # optional defaultDatabaseName: <database name> # optional
The list of possible databaseTypes are: postgres, redshift, bigquery, oracle, mysql, netezza, snowflake, sqlanywhere, sqlserver, databricks, denodo. Types are not case-sensitive but should be a single word with no spaces.
For example:
datasources: - name: "SQL Server DSN Production" databaseType: sqlserver host: 8bank-sqlserver.cpetgx.us-east-1.rds.amazonaws.com
Example for BigQuery database:
datasources: - project: "project-name" databaseType: bigquery bigQueryCredentialJsonString: "{"key": "value","key": "value"}"