Understanding the catalog graph
Important
The information in this section is for advanced users who want to understand the technical details about the data catalog.
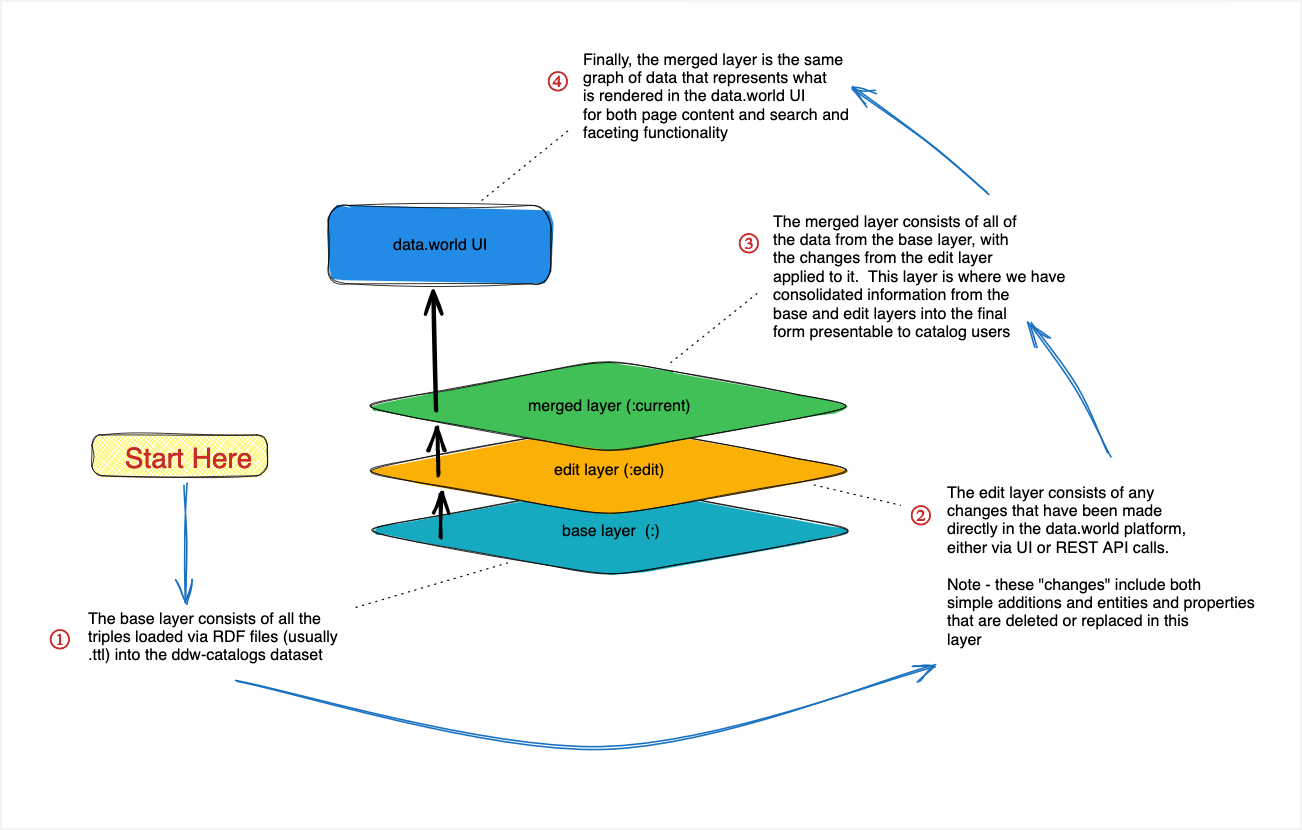
The data.world data catalog is made of following three layers.
Base layer
The base layer of your catalog is created by adding graph files to the Data Catalog Configuration (ddw-catalogs) dataset. The base layer captures information about what exists, load it into the platform, and define how to present this information in the UI.
Automatically cataloged metadata by the collectors
Bulk import of glossary
Catalog configuration files (customized metadata profile (MDP) files)
Edit layer
Edits made by users directly in the UI or via APIs are added to the edit layer. Catalog enrichment and management (manual edits) add context and get knowledge out of humans. Direct user edits are applied in the edit layer.
Merged layer
Both the edit layer and base layer are combined to present a merged or flattened view of the catalog to the user in the UI. The full flattened graph contains everything that is bulk loaded, as well as any changes made through the UI or the API. The edit layer overrides the base layer where applicable.
How do I decide in which layer my data should go in?
If data.world is not the source of record for specific information, then that data should be in the base layer, and contained in files that are imported from elsewhere.
As an example, run collectors to harvest metadata from your data source and do not edit it in data.world. That way, whenever the metadata is updated in the data source, it will be automatically updated in data.world on the next collector run.
If data.world is the source of record for a specific data, then that data should be added in the edit layer. Users will be able to change it in the edit layer, and data.world will be the source of record. Data changing in the base layer will be overridden by data.world, because data.world are the source of record.
How do the different layers work together?
The system always starts with the base layer as the ground truth - everything that is loaded in from collectors, MDP files, SPARQL transformations and pipelines, etc. Everything that is loaded into the ddw-catalog dataset forms that base layer - this graph is available as the default graph named : in that dataset.
Then as edits are applied in the UI and API, that information is stored, and the :edit graph represents those changes. It contains information about both additions to and subtractions from the graph.
Those additions and subtractions from the edit graph (:edit) are processed against the base graph (:), and that produces the merged layer (:current).
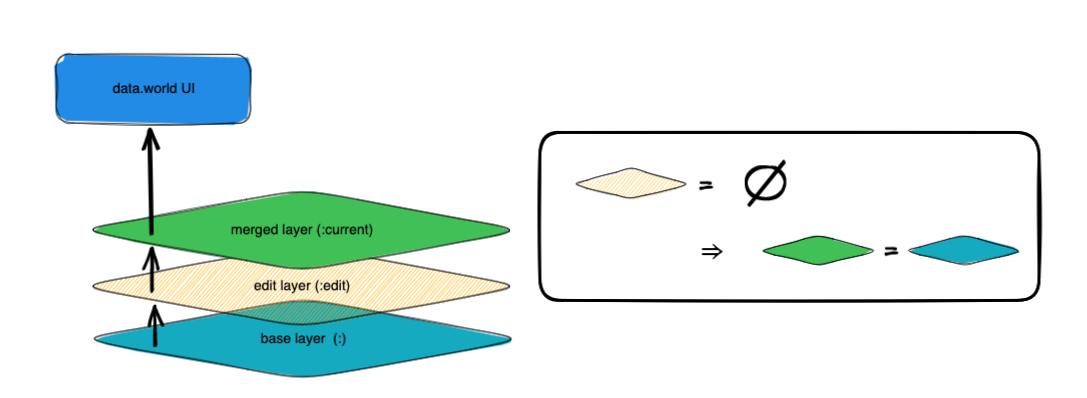
If the edit layer is empty, then the merged layer is identical to the base layer.
Properties added in edit Layer: When a property is added in the edit layer, it is merged into the current layer.
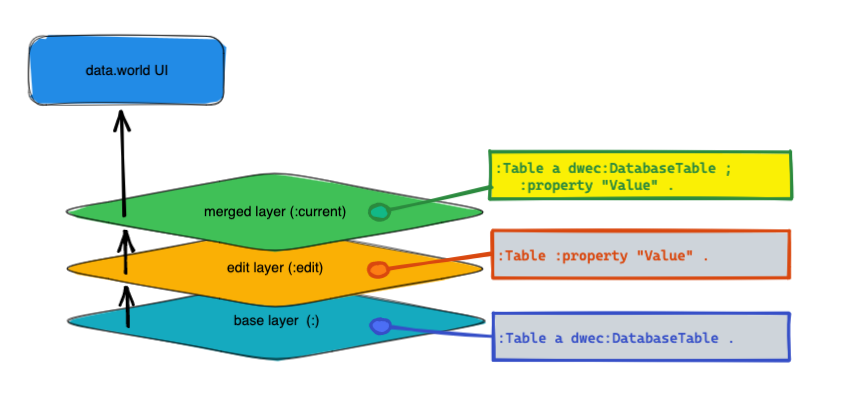
Values edited for single value properties: When you edit a single-value property in the edit layer, it replaces the value set from the base layer. After this, any changes made to the base layer are ignored and the actions in the edit layer supersede everything else.
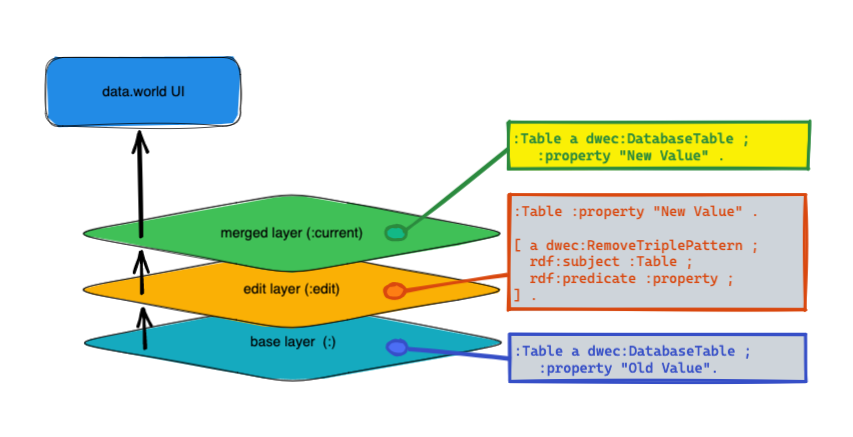
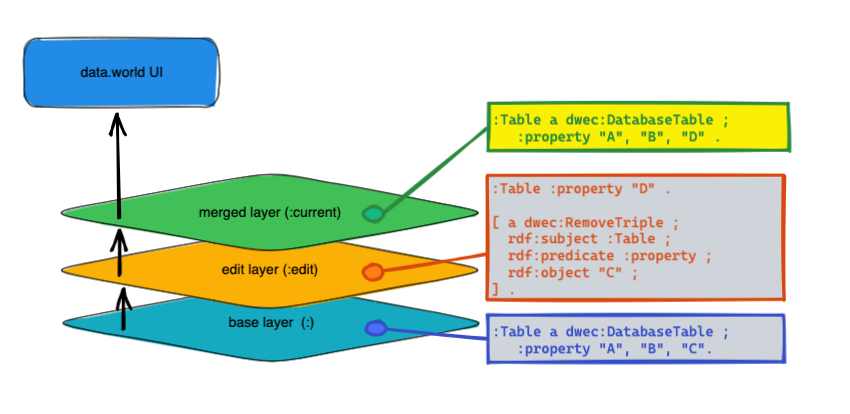
Values edited for multiple value properties: If a property has values A, B, and C and you remove C and add D in the edit layer, the property will have values A, B, D in the merged layer. After this, any changes made to the base layer are ignored and the actions in the edit layer supersede everything else.