Querying data
After you have added data to your project, create queries to extract information from the data sources and make it consumable for users. All data files are normalized so they are immediately queryable and joinable, whether they are similar formats or not. This lets you jump right into analyzing and querying to perform calculations, produce summaries, and manipulate data across many different formats and locations.
data.world supports SQL and SPARQL query languages. While data.world is built on semantic web technologies that are best queried using SPARQL, we recognize that most people are more familiar with SQL. For that reason, we have developed our own version of SQL to easily query data.world datasets.
SQL: If you are new to SQL, we have documentation that will walk you through everything from What is a database to How do I join all these different tables together so I can query them all at the same time. There is also a tutorial based on the exercises in the documentation.
SPARQL: SPARQL (pronounced "Sparkle") is a powerful query language to retrieve, modify and make the best use out of linked data. It is recognized as one of the key technologies of the semantic web due to its flexibility as well as ease of joining complex data structures and detecting intricate patterns in data. Its also the query language upon which the data.world platform is based. To learn more, see SPARQLing data.world.
SQL Query - native versus emulated
Whenever possible, data.world translates your query into the proper syntax to run on the target system. There are cases, however, where a query cannot be fully translated. When that happens, part of the query will run natively on the target system, and part will run on data.world as an emulation. As a result, the total query processing time will frequently be greater than if the entire query ran on the target system.
The most up-to-date information about the support for aggregations and functions is in our dataset Function Support Matrix.
If you are comfortable with SQL you can write your own query to search for support for aggregations in a specific system:
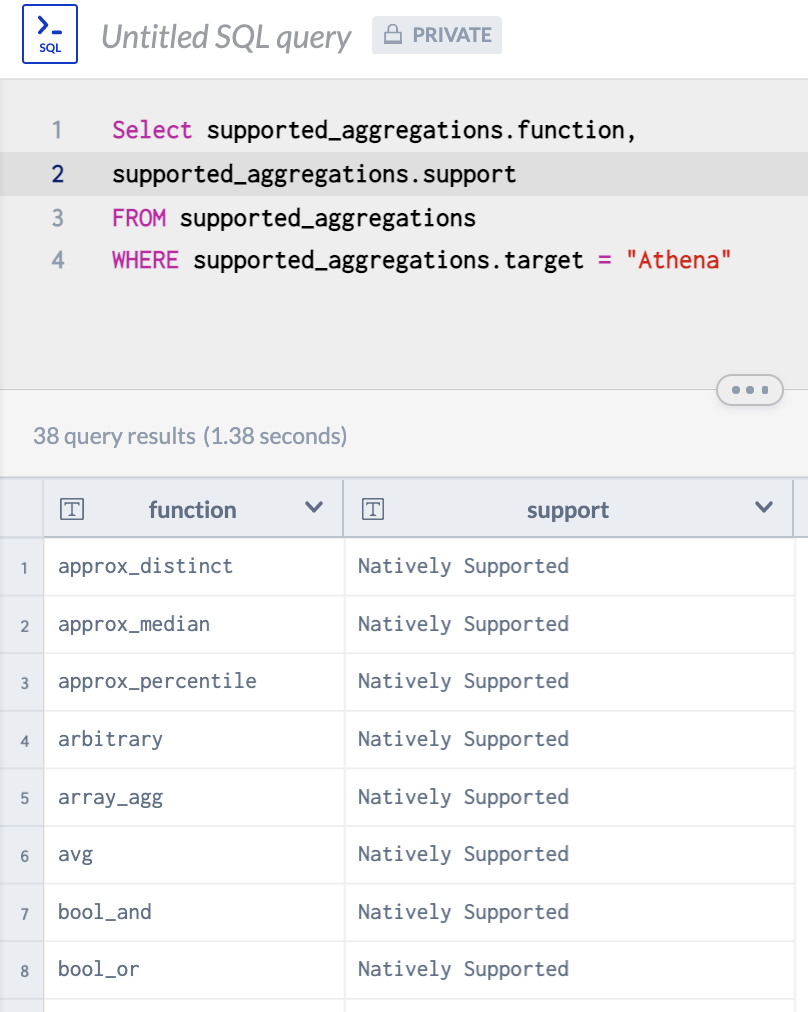
Tables for the aggregation and function support for each system Is in the Reference section.