Apply Stewards to Tables
Goal of this Eureka automation
With this automation we will automatically assign stewards to database tables in the organization.
Note
Before you begin:
Ensure your organization has cataloged database tables and they appear in your catalog.
Your must also have these tables added in Collection as we will be assigning Stewards to all tables in the specified collections.
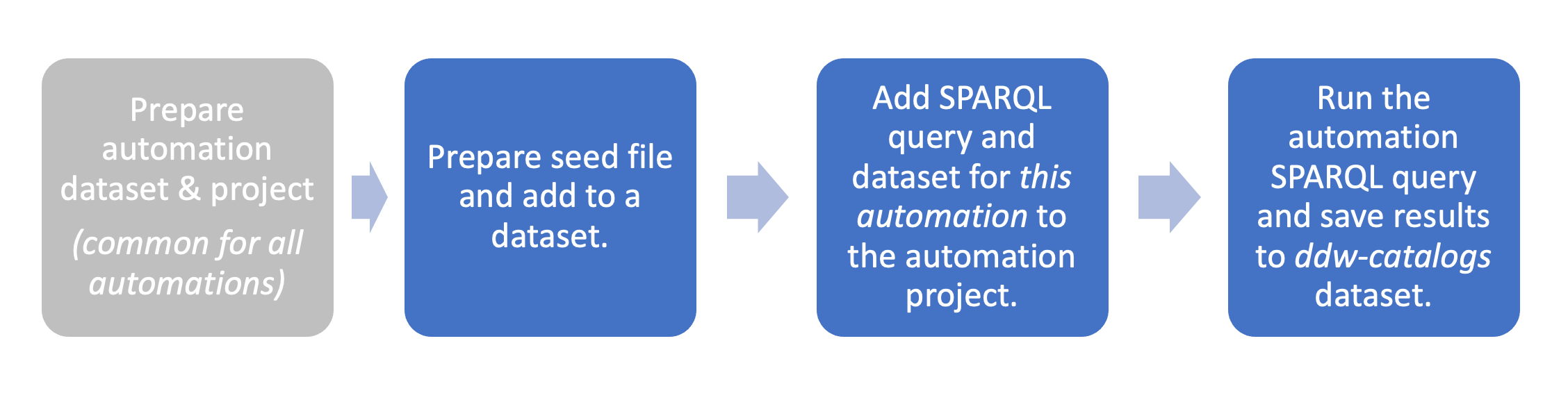
STEP 1: Prepare the seed file and add it to a dataset
First we will prepare the seed file:
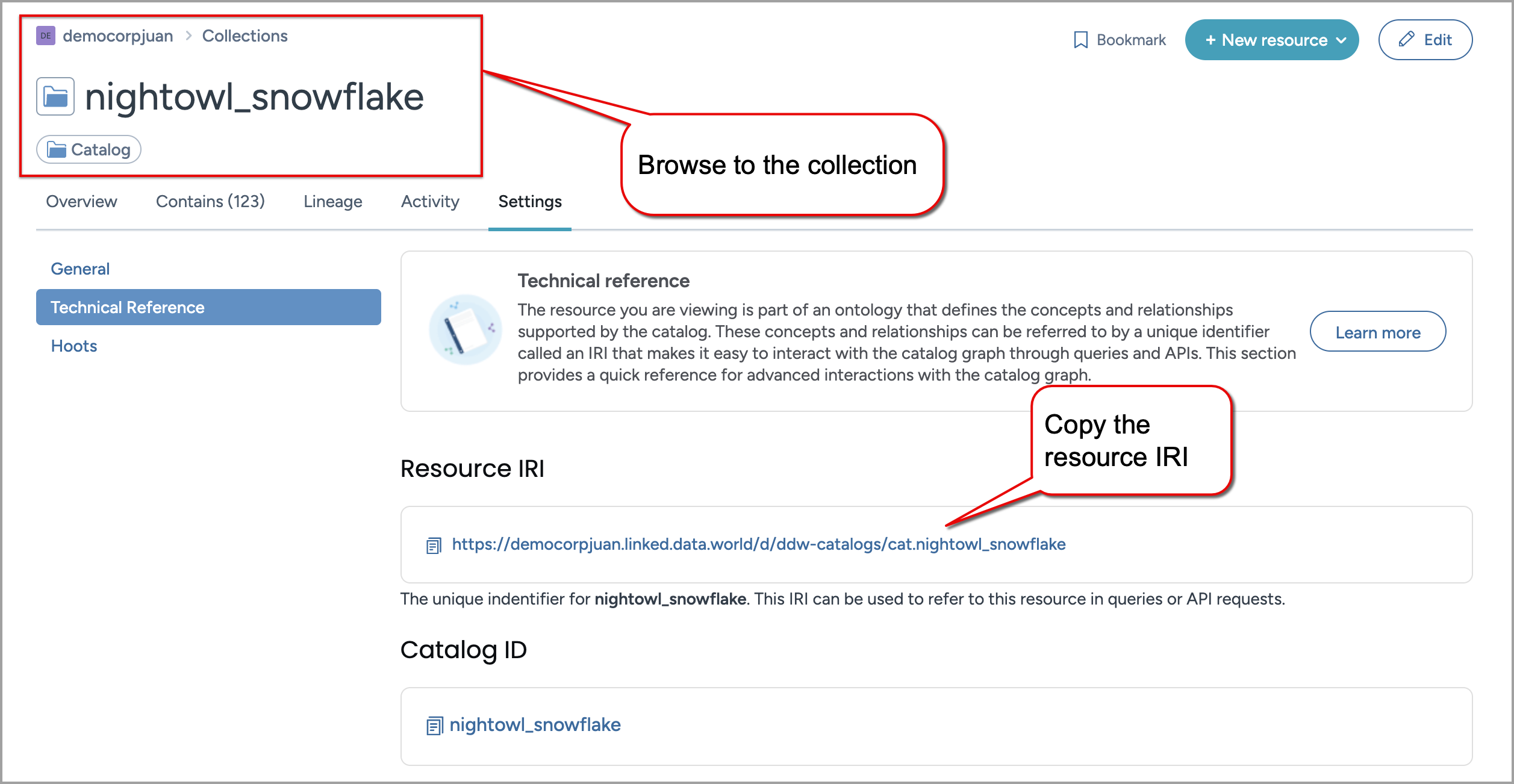
Browse to the Collection that stores the tables you want to assign the Steward. On the collection Settings page, in the Technical Reference tab, copy the Resource IRI.
Locate the person that is to be assigned as the Steward. On the person Settings page, in the Technical Reference tab, copy the Resource IRI.
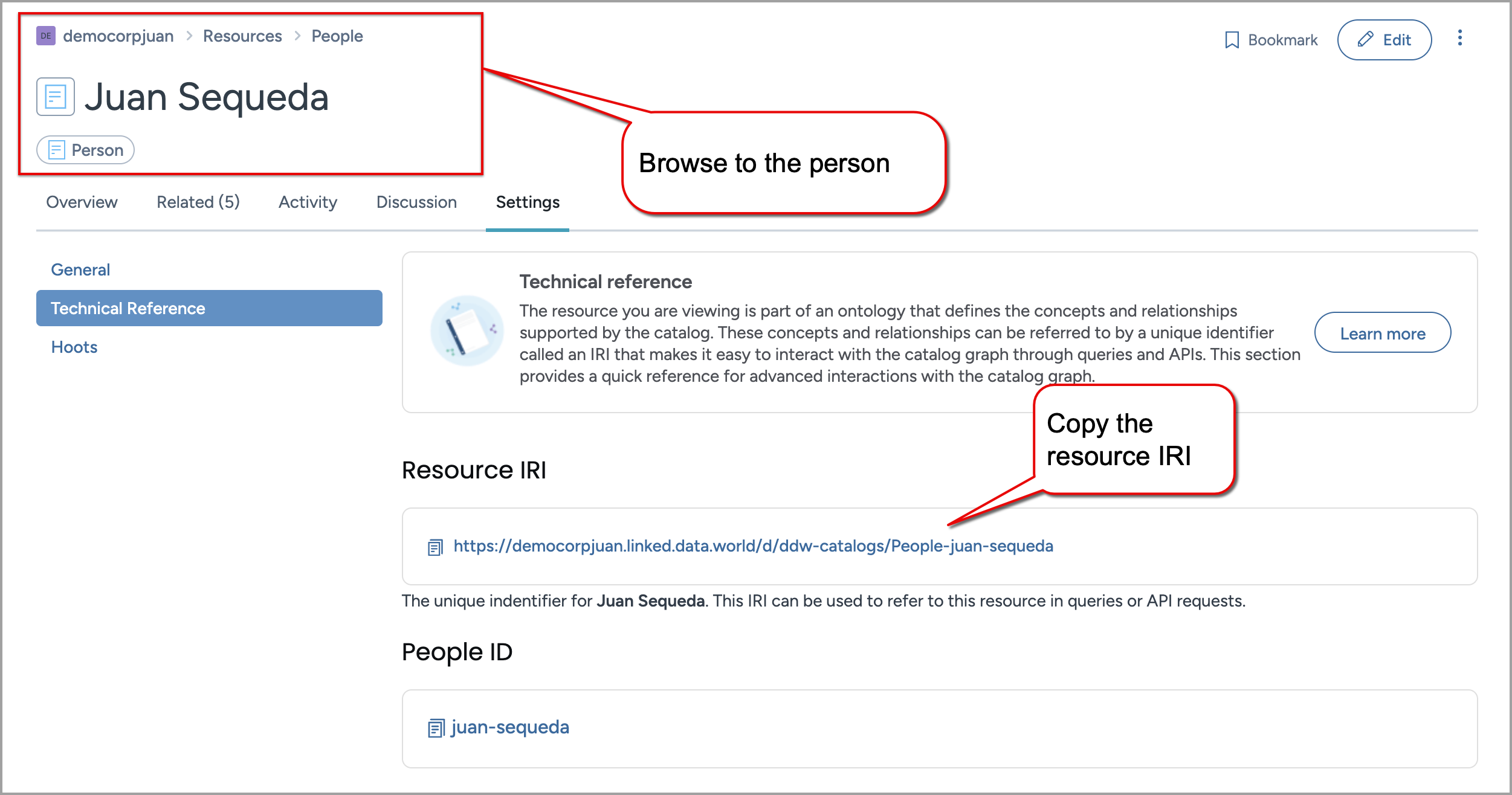
In this example, we are relating the database collection :cat.nightowl_snowflake to have a steward :People-juan-sequeda and the database collection :cat.magento to have a steward :People-tim-gasper
Create the seed file assign-stewards-to-tables.seed.ttl using this information. Don't forget to replace yourorgname with the name of your organization and upload it to the
@prefix : <https://yourorgname.linked.data.world/d/ddw-catalogs/> . :cat.nightowl_snowflake :hasSteward :People-juan-sequeda. :cat.magento :hasSteward :People-tim-gasper .
Now, we will create a dataset and add the seed file to it:
Create a dataset and name it ddw-eureka-assign-stewards-to-tables.
Upload the seed file assign-stewards-to-tables.seed.ttl to it.
STEP 2: Add dataset and SPARQL query to the Eureka Automations Project
Note
These tasks are done in the ddw-eureka-automations project created here.
Go to the project ddw-eureka-automations.
On the Project details page, click the Launch Workspace button.
Link the dataset ddw-eureka-assign-stewards-to-tables created in STEP 1 to the project by clicking Add > Dataset > .
Create a new SPARQL Query by clicking +Add > SPARQL Query.
Add the following query. Replace yourorgname with the name of your organization.
PREFIX : <https://yourorgname.linked.data.world/d/ddw-catalogs/> construct{ ?x :stewards ?stewardName. } where { ?catalog a dwec:Catalog. ?catalog :hasSteward ?steward . ?steward dct:title ?stewardName . ?catalog dcat:record ?record. ?record foaf:primaryTopic ?x. ?x a dwec:DatabaseTable . }Save the query with:
Name: ea-assign-stewards-to-tables.result.ttl.rq
Description: Given a seed file that defines People as data stewards for database collections, the automation assigns data stewards to the corresponding database tables in the collections.
STEP 3: Run your Eureka automation
Execute the SPARQL query added in STEP 2.
From the Results page, select Download the results > Save to dataset.
Set file name. The query name will automatically appear. Just delete the suffix .rq
Save the file to the ddw-catalogs dataset of your organization. You must set the file to auto-sync every hour.
Note
This file goes in theddw-catalogs dataset.
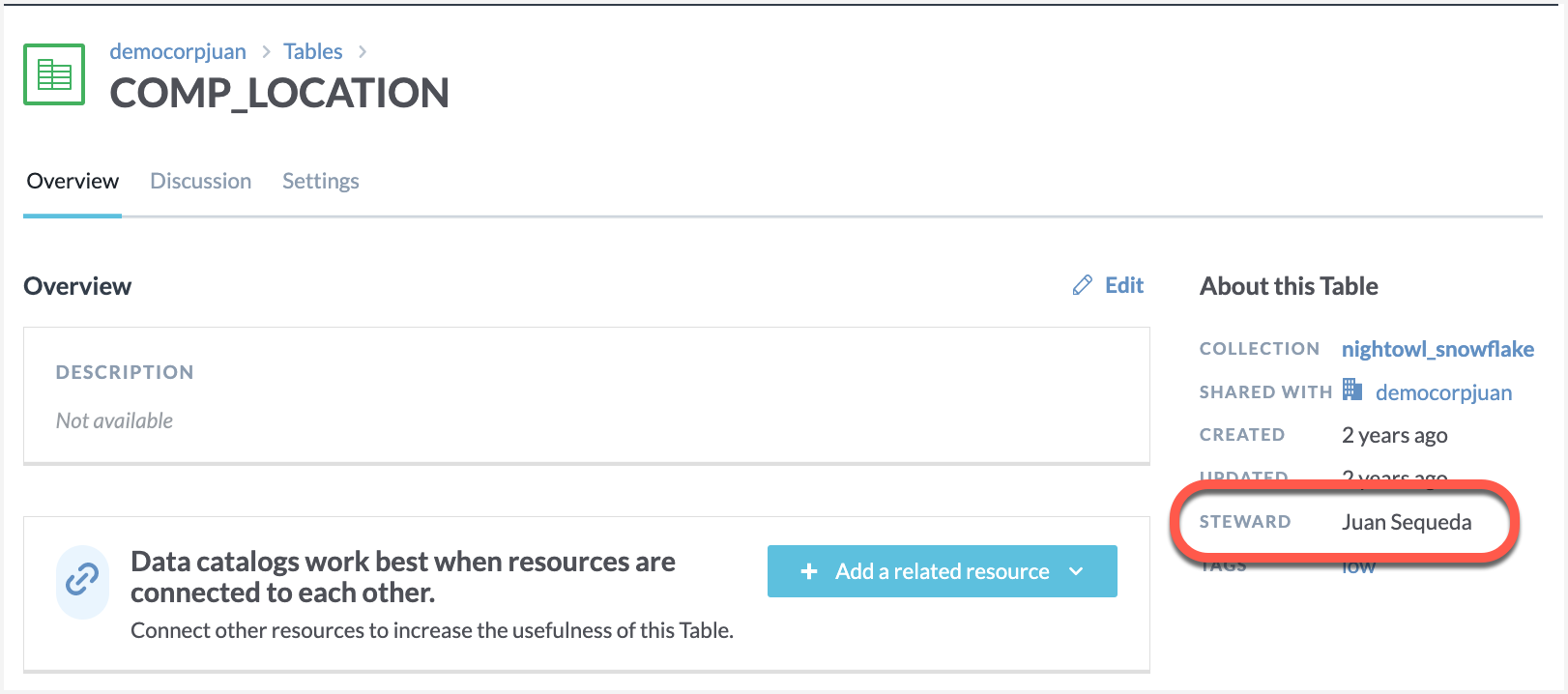
View the Results! 🎉
Browse to the tables in the collections that you had picked for assigning stewards.
Note
Congrats! Check the table details page and it should now have the Steward assigned to it.