Preparing to run the BigQuery collector
Setting up pre-requisites for running the collector
Make sure that the machine from where you are running the collector meets the following hardware and software requirements.
Item | Requirement |
|---|---|
Hardware (for on-premise runs only) Note: The following specs are based upon running one collector process at a time. Please adjust the hardware if you are running multiple collectors at the same time. | |
RAM | 8 GB |
CPU | 2 Ghz processor |
Software (for on-premise runs only) Docker or Java Runtime Environment | |
Docker | Click here to get Docker. |
Java Runtime Environment | OpenJDK 17 is supported and available here. |
data.world specific objects (for both cloud and on-premise runs) | |
Dataset | You must have a ddw-catalogs dataset set up to hold your catalog files when you are done running the collector. If you are using Catalog Toolkit , follow these instructions to prepare the datasets for collectors. |
Network connection | |
Allowlist IPs and domains | |
Setting up authentication for BigQuery
data.world connects to BigQuery using a Service Account associated with your project.
To set up authentication for BigQuery:
Create a service account with the following roles BigQuery Data Viewer and BigQuery User. For additional information on predefined roles and permissions, see Google Cloud Platform documentation.
After you create a service account, create a key for the account and download the associated
JSONkey file.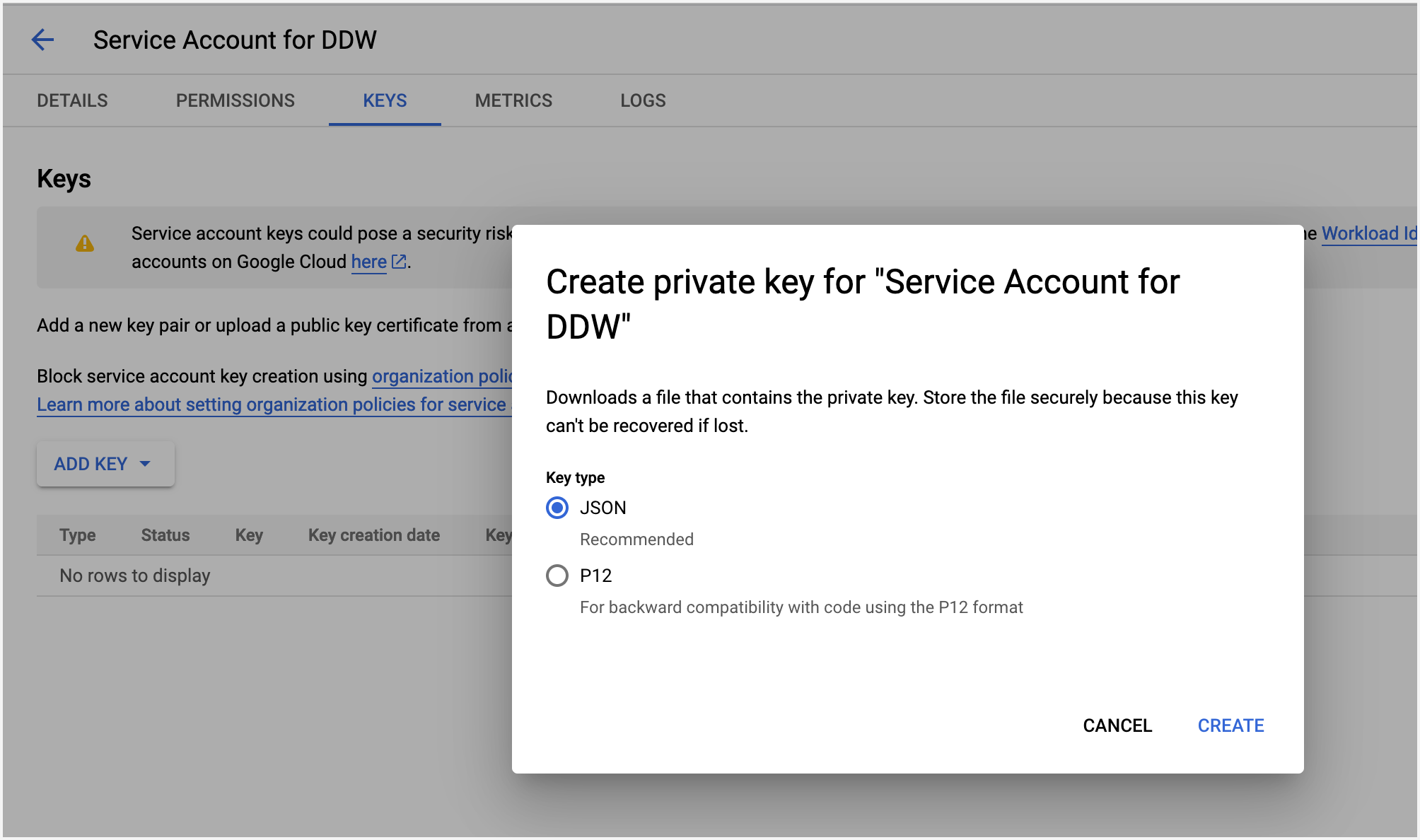
Place this key file on the machine from where you plan to run the collector. You will need this file while running the collector.